编译器在实际阅读源程序的时候,首先通过扫描程序执行语法分析(Lexical analysis):它将字符序列收集到称作记号(token)的有意义单元中,记号同自然语言,如英语中的字词。
例如在下面的代码行中:
a[index] = 4 + 2
这个代码包括了12个非空字符,但只有8个记号:

每一个记号均由一个或多个字符组成,在进一步处理之前它已被收集在一个单元中。
语法分析程序从扫描程序中获取记号形式的源代码,并定义程序结构的语法分析(syntax analysis),这与自然语言中句子的语法分析类似。语法分析定义了程序的结构元素极其关系。通常将语法分析的结果表示为分析树(parse tree)或语法树(syntax tree)。
例如:还是那行C代码,它表示一个称为表达式的结构元素,该表达式是一个由左边为下标表达式、右边为整型表达式的赋值表达式组成。这个结构可按下面的形式表示为一个分析树:
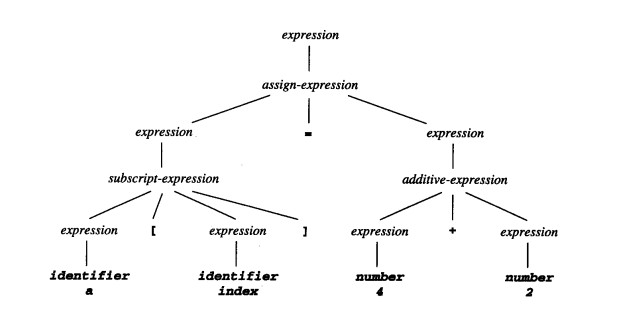
请注意,分析树的内部节点均由其表示的结构名标示出,而分析树的叶子则表示输入中的记号序列(结构名以不同字体表示以示与记号的区别)。
分析树对于显示程序的语法或程序元素很有帮助,但是对于表示该结构却显得力不从心了。分析程序更趋向于生成语法树,语法树是分析树中所包含信息的浓缩(有时因为语法树表示从分析树中的进一步抽取,所以也被称为抽象的语法树(abstract syntax tree))。下面是C赋值语句的抽象语法树的例子:
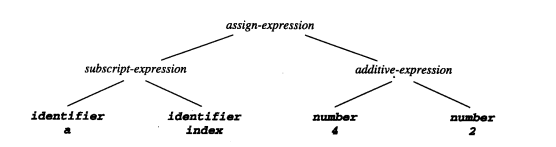
ps: 昨天看到这个,本来想立刻记录下来的,因为种种别的事情,耽误了。o(︶︿︶)o 唉,只有今天来做了。
我本想找一个现成的介绍之类的转载过来,这样能够省不少力气。
可是,没有合适的。
以上均是我的手打,半个多小时啊~