limit 1 : 只返回第一条符合条件的记录,找到第一条符合条件的记录之后数据库便不会再往下搜寻其它记录了,效率较高
如果没有加上 limit 1,数据库在找到第一条符合条件的记录之后,还会继续向下查询,寻找其它符合条件的记录,直到整张表扫描完成为止,效率较低
下面我们就来验证一下 limit 1 能否提升查询效率
现有 employee_1000000,表中数据量是 100 万, name 字段是以数字自增的
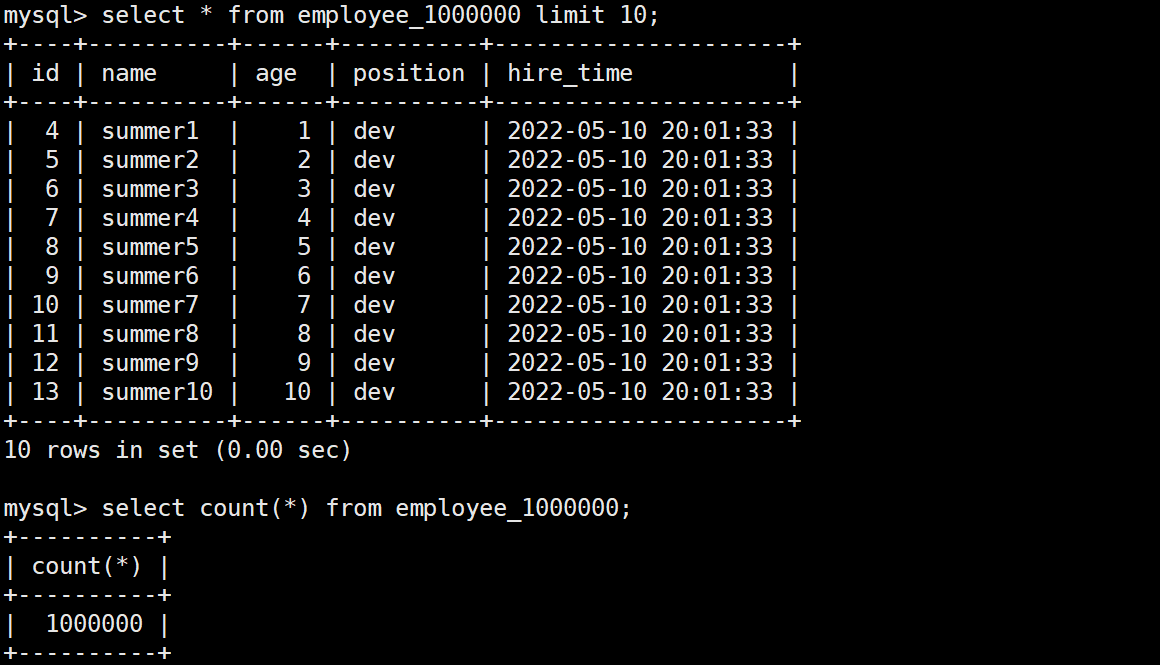
先看一下如下查询效果
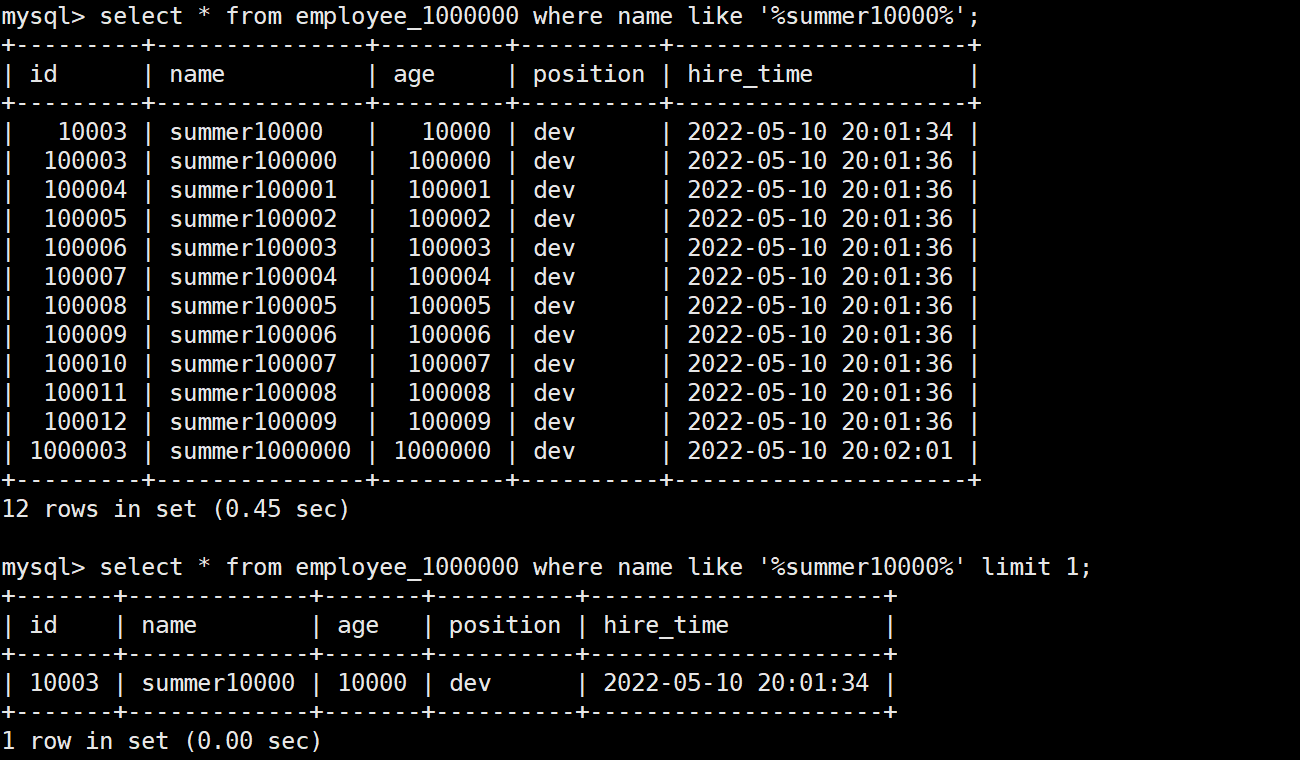
没有使用 limit 耗时 0.45 s,而使用了 limit 1 之后耗时 0.00 s,基本就是 ms 级别的了
因为加了 limit 1 之后搜寻到 id = 10003 的记录之后就直接返回了,不会再往下查找,整个搜寻实际就相当于扫描到第 10003 行就结束了,效率较高
没有加 limit 1 会扫描整张表的 100 万条记录,效率低
大多数情况下 limit 1 可以提升查询效率,但是某些极端的条件下,limit 1 并不能带来效率的提升
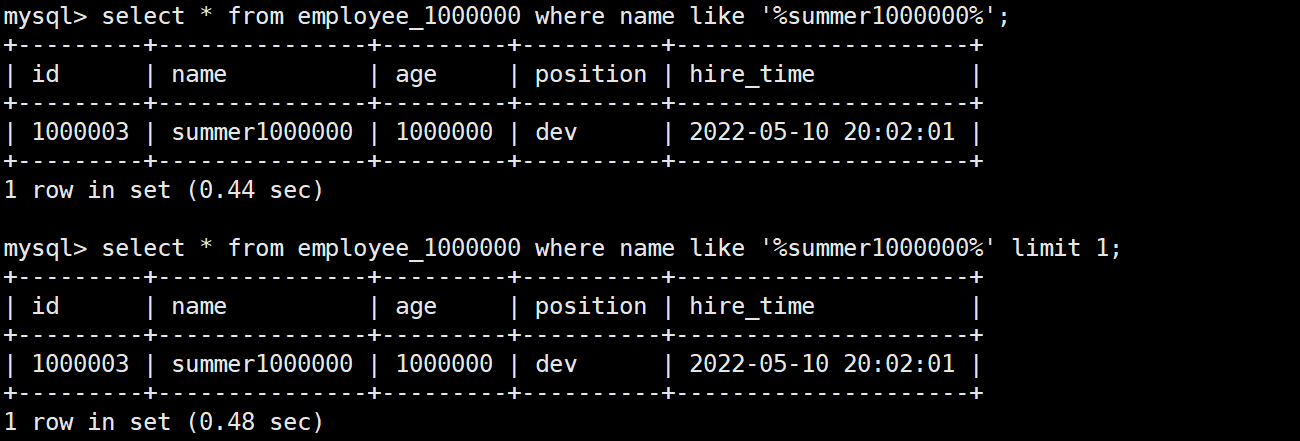
加了 limit 1 和没加 limit 1 的时间是一样的
因为整张表只有一条符合条件的记录,并且该记录是 employee_1000000 表的最后一条记录,不加 limit 1 要搜寻到第 1000000 条记录的时候才找到结果,加了 limit 1 也是需要搜寻到第 1000000 条记录的时候才拿到结果,所以它们的时间是一样的
即便如此,但是如果我们已经预知结果集只有一条记录,或者只想搜寻符合条件的一条记录,那么可以加上 limit 1 来提升性能,排除极端个例,绝大多数情况下还是能带来性能提升的