Java码农学底层
学习《深入理解Java虚拟机》接近尾声,对12.4节中描述的操作系统中的线程实现很感
兴趣。所以就趁热打铁,继续看《Operating System Concept》(恐龙书操作系统概念)
和《Linux内核设计与实现》两本经典操作系统图书。前者偏重理论,在每章知识点讲解
结束后会对各个操作系统的实现加以指点,而后者则是对Linux的具体实现,一个个具体
代码片段进行分析,细致入微。于是在此做些总结,融合这两本书中的内容,留作日后
深入学习《深入Linux内核》的参考。
中断:操作系统的神经,不仅响应外界(键盘、鼠标、网卡等各种IO设备的输入数据)
的请求,并且还定时触发系统定时器(削减时间片等)和动态定时器(中断处理程序的
下半部The Half Bottom)。《操作系统概念》中将现代操作系统称为中断驱动的系统
一点都不为过,因此将中断比喻成操作系统及其管理的硬件这个庞大野兽躯体内的神经
名副其实。
进程:如果说CPU是操作系统乃至整个PC机的大脑,那么进程就是实际去完成大脑意志
的肉体了。任意时刻都至少有一个进程在运转着,按照CPU中指令的要求完成动作。这个
操作系统中最重要的概念之一涉及了很多内容:生命周期、调度、通信、同步、安全保护
等等。本篇是对进程基础知识的总结,算是开篇吧,之后再逐一学习高级的内容。
进程的结构
一个进程包括了程序计数器、堆、栈、代码(TextSection)、全局变量(DataSection)等。在
栈和堆之间的空闲内存可能会被开辟出来作为进程间通信的共享内存区(关于进程间通信
IPC的知识在以后会学习到)。
对Java虚拟机来讲,它也只不过是操作系统管理的众多进程中的一个,没有什么特别之处。
JVM自己管理着从操作系统申请来的堆空间和数据区,将其作为内存堆和方法区供所有内部
的线程共享。同时JVM中的线程拥有各自私有的PC程序计数器、Java方法栈等。
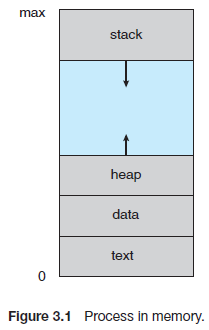
Linux的进程描述符是task_struct,被保存在双向循环链表中(在下一篇讨论进程调度时将
会看到它是如何保存的)。通过遍历这个链表及task_struct中的parent和children指针,我们
就可以得到当前所有进程的父子关系(见后面讨论的进程创建),当然在用户空间中我们是
没法访问内核的数据结构的,这需要我们改写内核的源码,在内核态操作,还是先学好基础
再弄高级的吧。:)
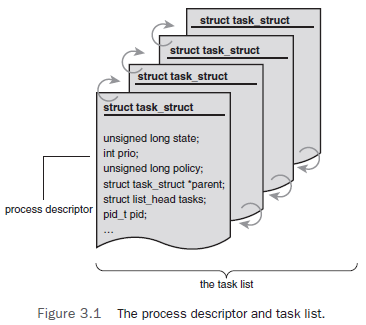
既然这些task_struct是被单独保存在一个链表中供内核使用的,那么各个进程是如何关联到
它的呢?在每个进程地址空间的底部(低地址)都有一个thread_info结构,其中保存了指向
该进程的task_struct的指针。这样做就可以通过栈指针计算出task_struct而不用额外的寄存器
专门记录了。这对于像x86这样寄存器并不富裕的体系结构来说是种优化,在内核栈的尾端创建
thread_info结构,通过计算偏移间接地查找task_struct结构。但对于寄存器富裕的体系结构,
完全可以用一个专门寄存器存放指向当前进程的task_struct结构。
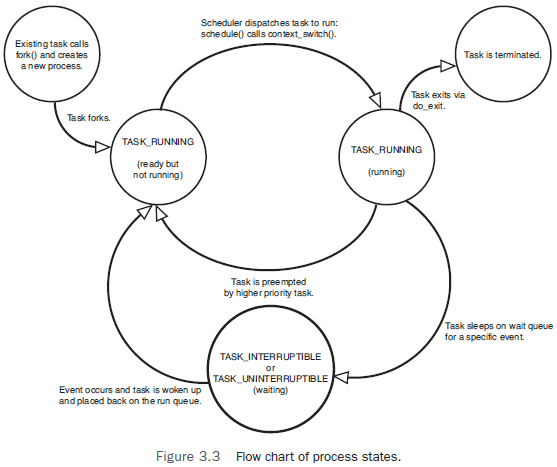
进程的状态
对于单任务系统来讲,进程只需新建、运行、终止三种状态就够了。因为进程在运行过程
中不会因为阻塞而进入其他状态,无论如何其他进程都要等到当前进程执行完毕后才能开始。
但在多任务系统中,当进程发生阻塞时内核会让当前进程休眠,让其他进程启动,从而使
CPU一直保持运转。因此多任务系统的进程还需要一个等待(waiting)状态。
在多任务分时系统中,一个进程即便没有发生阻塞也不可能一直占用CPU,所有进程要共享
CPU资源,不断切换执行。所以分时系统的进程还需要一个准备(ready)状态。
所以现代操作系统中的进程状态可以归纳为下图:
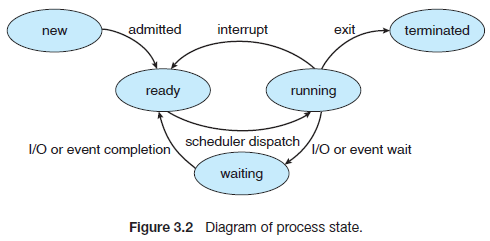
任意时刻一个CPU上只有一个进程能处于running状态。但Linux中的ready和running状态都用
TASK_RUNNING来表示。
进程的创建
Windows和Unix/Linux的进程创建方法很不同,首先来看Windows的进程创建。在Windows中
我们通过调用CreateProcess()函数创建子进程,传入的参数中包含了子进程要执行的exe文件
路径。此外还会传递一些进程的属性信息作为参数。
#include <windows.h>
#include <stdio.h>
#include <tchar.h>
void _tmain( int argc, TCHAR *argv[] )
{
STARTUPINFO si;
PROCESS_INFORMATION pi;
ZeroMemory( &si, sizeof(si) );
si.cb = sizeof(si);
ZeroMemory( &pi, sizeof(pi) );
if( argc != 2 )
{
printf("Usage: %s [cmdline]\n", argv[0]);
return;
}
// Start the child process.
if( !CreateProcess( NULL, // No module name (use command line)
argv[1], // Command line
NULL, // Process handle not inheritable
NULL, // Thread handle not inheritable
FALSE, // Set handle inheritance to FALSE
0, // No creation flags
NULL, // Use parent's environment block
NULL, // Use parent's starting directory
&si, // Pointer to STARTUPINFO structure
&pi ) // Pointer to PROCESS_INFORMATION structure
)
{
printf( "CreateProcess failed (%d).\n", GetLastError() );
return;
}
// Wait until child process exits.
WaitForSingleObject( pi.hProcess, INFINITE );
// Close process and thread handles.
CloseHandle( pi.hProcess );
CloseHandle( pi.hThread );
}通过这个例子还可以看出在Windows中Process和Thread是完全不同的概念,子进程的进程和
线程句柄分别保存在pi的两个属性中。在后面学习线程时我们会看到,Linux中是不区分进程和
线程的,真是有趣的想法!
Unix的进程创建很特别,不像Windows操作系统提供Spawn的机制,Unix将进程创建分解成
两个单独的函数中去执行:fork()和exec()。这样做的目的是可以在开始执行子进程前对其
进行设置,做一些初始化工作,使进程的创建更加灵活。下面是一个简单的实例。
#include <sys/types.h>
#include <stdio.h>
#include <unistd.h>
int main(void)
{
pid_t pid;
pid = fork();
if (pid < 0) {
fprintf(stderr, "Fork failed.\n");
exit(-1);
}
else if (pid == 0) {
execlp("/bin/ls", "ls", NULL);
}
else {
wait(NULL);
printf("Child complete.\n");
exit(0);
}
}但将进程创建分成两步后也要考虑更多的问题,比如fork()时要将父进程的全部数据都拷贝过来
吗?那样的话exec()执行新程序时又要重新覆盖掉地址空间岂不是浪费。对此Linux做了细致的
优化。传统的fork()系统调用直接把所有资源复制给新创建的进程,如果新进程打算立即执行一个
新的程序,那么之前所有的拷贝都前功尽弃了。Linux的fork()使用写时拷贝(copy-on-write)页
技术,创建进程时内核并不复制整个进程地址空间,而是让子进程也共享父进程的地址空间。资源
的真正复制只有在需要写入时才进行,在此之前只是以只读方式共享。所以,fork()的实际开销就
是复制父进程的页表以及给子进程创建唯一的进程描述符,非常快速。所以在进程调用时,
内核会有意选择子进程首先执行,因为一般子进程都会马上调用exec()函数。如果父进程首先执行
的话,有可能会开始向地址空间写入。
fork()的具体调用过程为clone()->do_fork()->copy_process(),在此先记录一下,为以后深入源码
研究作参考。
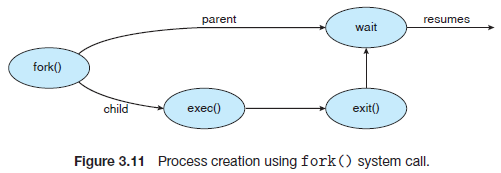
下图是Unix进程创建的简要流程,一次fork()调用分别在父进程和子进程中返回两次。
进程的继承关系
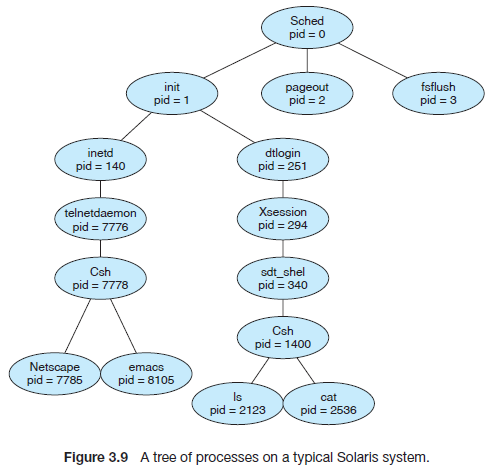
下面是Solaris系统启动后的进程树,init进程下有两个子进程。dtlogin进程是一个登录用户,通过
X-windows(Xsession)操作Solaris,打开了C-shell执行ls、cat等命令。另一个进程inetd,通过telnet
服务为另一个用户开启C-shell,并打开Netscape和emacs等程序。在Unix-like系统中,我们可以
通过ps或pstree来查看当前进程信息。
前面Windows创建进程的例子中,在CreateProcess()之后,父子进程之间便没有关系了。但在
Linux中父子进程是有很强的继承关系的,所以当父进程在子进程之前退出,这些子进程就会
变成孤儿,所以内核还要为它们找到新的父进程,如果找不到就会让init进程作为它们的父进程。
而当子进程已经完成但父进程还没有调用wait()获得其返回值时,子进程便处于TASK_ZOMBIE
僵尸状态了。由于父子进程间联系较弱,所以Windows没有这两个问题。