一、基础数据类型补充
1.join:把列表中的数据进行拼接。拼接成字符串
lst = ["汪峰", "吴君如", "李嘉欣", "陈慧琳", "关之琳"] # 遍历列表. 把列表中的每一项用"_" 做拼接 s = "_".join(lst) # 把列表转化成字符串 print(s)
结果:
汪峰_吴君如_李嘉欣_陈慧琳_关之琳
s1 = "汪峰_吴君如_李嘉欣_陈慧琳_关之琳" ls = s1.split("_") # 把字符串转化成列表 print(ls)
结果:
['汪峰', '吴君如', '李嘉欣', '陈慧琳', '关之琳']
print("*".join("马化腾"))
结果:
马*化*腾
2.关于删除
lst = ["渣渣辉", "古天绿", "陈小春", "彭佳慧", "郑中基", "胡辣汤"] lst.clear() print(lst)
结果:
[]
lst = ["渣渣辉", "古天绿", "陈小春", "彭佳慧", "郑中基", "胡辣汤"] for el in lst: # for 内部有一个变量来记录当前被循环的位置, 索引. lst.remove(el) # 直接删除. 是删不干净的. 原因是每次删除都设计到元素的移动. 索引在变. print(lst)
结果:
['古天绿', '彭佳慧', '胡辣汤']
***************************************************************************************************
先把要删除的内容保存在一个新列表中. 循环这个新列表. 删除老列表 new_lst = [] for el in lst: new_lst.append(el) for el in new_lst: lst.remove(el) print(lst)
****************************************************************************************************
删除姓张的人
lst = ["张无忌", "张三丰", "张翠山", "张嘉译", '刘嘉玲', "刘能", '刘老根'] # 删除姓张的人 new_lst = [] for el in lst: if el.startswith("张"): new_lst.append(el) for el in new_lst: lst.remove(el) print(lst)
结果:
['刘嘉玲', '刘能', '刘老根']
dic = {"谢逊": '金毛狮王', "韦一笑":"青翼蝠王","殷天正":"白眉鹰王","金花婆婆":"紫衫龙王"}
for k in dic:
dic['谢逊'] = "张无忌他爹"
print(dic)
结果:
{'谢逊': '张无忌他爹', '韦一笑': '青翼蝠王', '殷天正': '白眉鹰王', '金花婆婆': '紫衫龙王'}
字典在循环的时候,不允许改变他的大小,但是可以修改,如上
——————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————
——————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————
li = [11, 22, 33, 44] for e in li: li.remove(e) print(li) 结果: [22, 44]
分析原因:for的运行过程,会有一个指针来记录当前循环的元素是哪一个,一开始这个指针指向第0个,然后获取到第0个元素,紧接着删除第0个,这个时候,原来是第1个的元素会自动的变成第0个,然后指针向后移动一次,指向1元素,这时原来的1已结变成了0.也就不会被删除了
用del删除试试看:
li = [11, 22, 33, 44] for i in range(0, len(li)): del li[i] print(li) 结果: 报错 # i= 0, 1, 2 删除的时候li[0] 被删除之后. 后面一个就变成了第0个. # 以此类推. 当i = 2的时候. list中只有一个元素. 但是这个时候删除的是第2个 肯定报错啊
经过分析发现. 循环删除都不⾏. 不论是⽤del还是⽤remove. 都不能实现. 那么pop呢?
for el in li: li.pop() # pop也不行 print(li) 结果: [11, 22]
只有这样才是可以的:
for i in range(0, len(li)): # 循环len(li)次, 然后从后往前删除 li.pop() print(li)
或者. 用另一个列表来记录你要删除的内容. 然后循环删除
li = [11, 22, 33, 44] del_li = [] for e in li: del_li.append(e) for e in del_li: li.remove(e) print(li)
注意: 由于删除元素会导致元素的索引改变, 所以容易出现问题. 尽量不要再循环中直接去删除元素. 可以把要删除的元素添加到另一个集合中然后再批量删除.
dict中的元素在迭代过程中是不允许进行删除的
dic = {'k1': 'alex', 'k2': 'wusir', 's1': '金老板'}
# 删除key中带有'k'的元素
for k in dic:
if 'k' in k:
del dic[k] # dictionary changed size during iteration, 在循环迭代的时候不允许进行删除操作
print(dic)
#那怎么办呢? 把要删除的元素暂时先保存在一个list中, 然后循环list, 再删除
dic = {'k1': 'alex', 'k2': 'wusir', 's1': '金老板'}
dic_del_list = []
# 删除key中带有'k'的元素
for k in dic:
if 'k' in k:
dic_del_list.append(k)
for el in dic_del_list:
del dic[el]
print(dic)
3.fromkeys
d = {} dd = d.fromkeys("马化腾","周芷若") fromkeys是一个类方法.作用是创建新字典 print(d) 原字典没变化 print(dd) 新的字典是通过第一个参数的迭代. 和第二个参数组合成key:value创建新字典
结果:
{}
{'马': '周芷若', '化': '周芷若', '腾': '周芷若'}
d = dict.fromkeys(["哇哈哈", "爽歪歪"], []) # 所有的key用的都是同一个列表,改变其中一个。 另一个也跟着改变
## {'哇哈哈': [], '爽歪歪': []}
d["哇哈哈"].append("张无忌") print(d)
结果:
因为两个key指向的是同一个结果
{'哇哈哈': ['张无忌'], '爽歪歪': ['张无忌']}
print(id(d['哇哈哈']), id(d["爽歪歪"]))
结果:
52754712 52754712
dic.fromkeys(iter, value)
把可迭代对象进行迭代。 和后面的value组合成键值对 返回新字典
坑1:返回新字典。不会改变原来的字典
dict = {} dic = dict.fromkeys(["jay", "JJ"], ["周杰伦", "麻花藤"]) print(dic) print(dict) 结果: {'jay': ['周杰伦', '麻花藤'], 'JJ': ['周杰伦', '麻花藤']} {}
坑2:d = fromkeys(xxx, []) 字典中的所有的value都是同一个列表
dic = dict.fromkeys(["jay", "JJ"], ["周杰伦", "麻花藤"]) print(dic) dic.get("jay").append("胡大") print(dic) 结果: {'jay': ['周杰伦', '麻花藤', '胡大'], 'JJ': ['周杰伦', '麻花藤', '胡大']}
补充

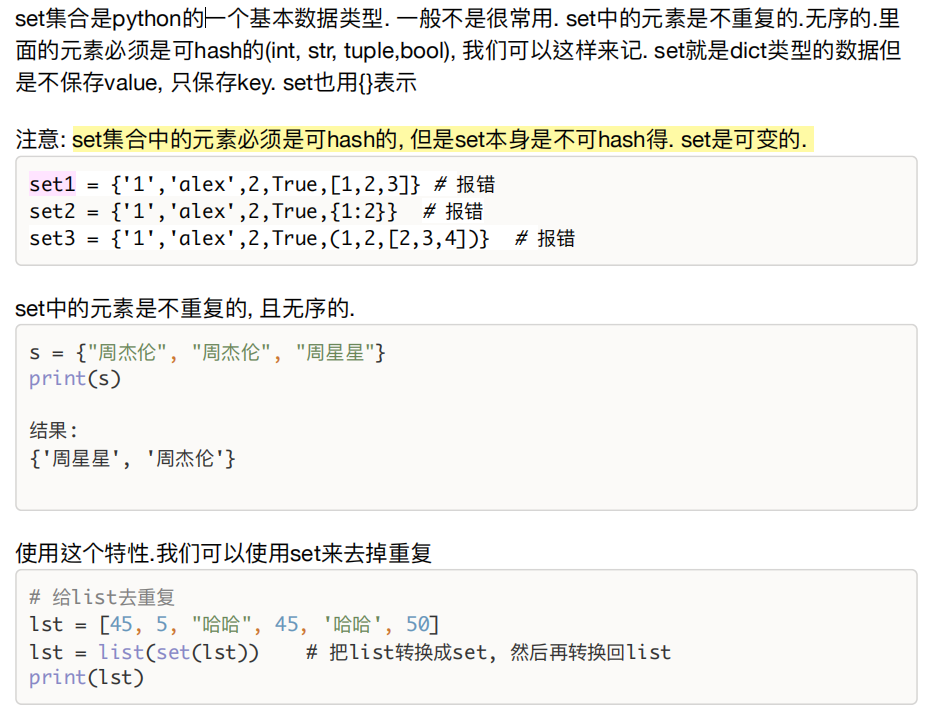
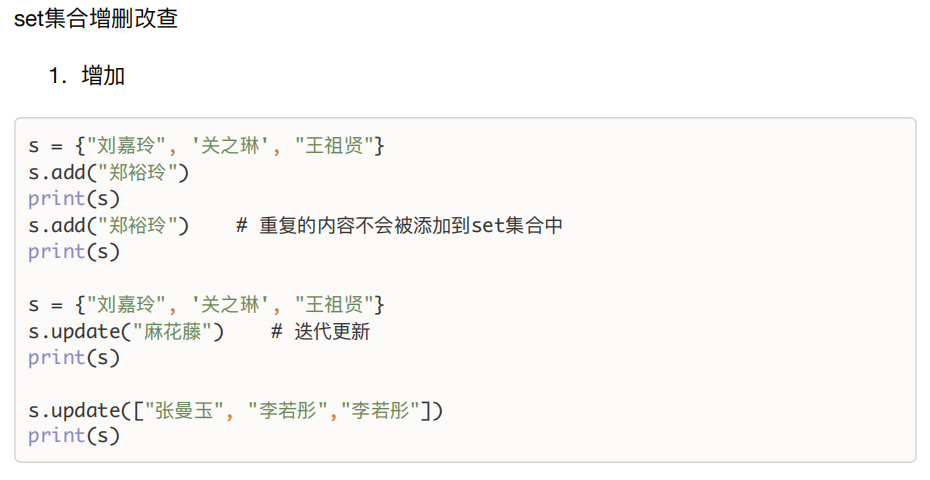
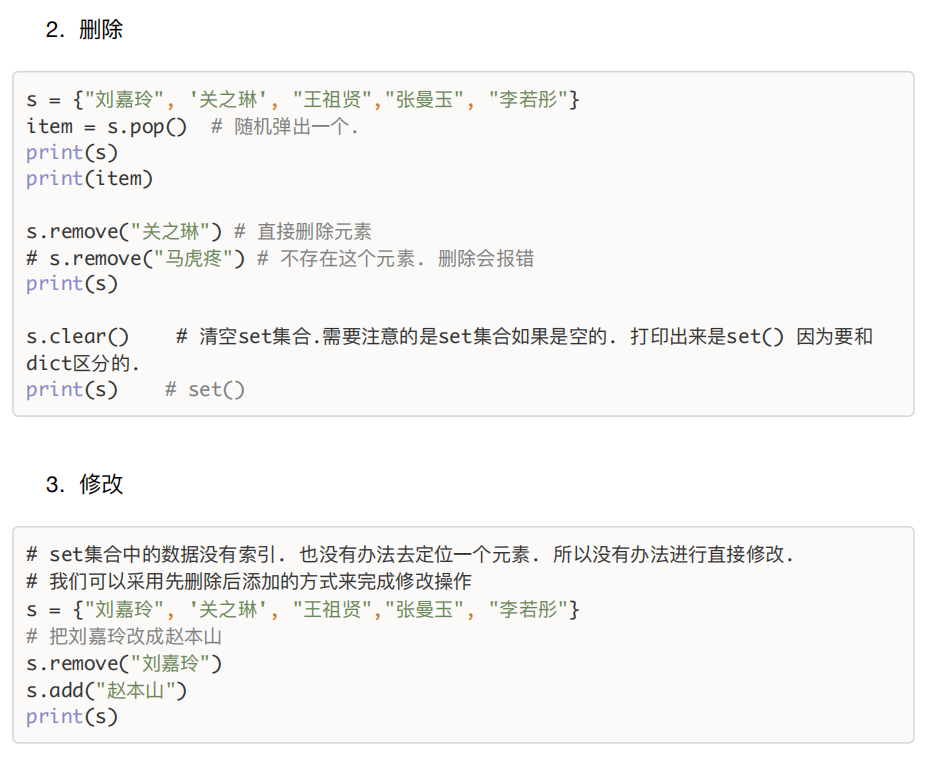
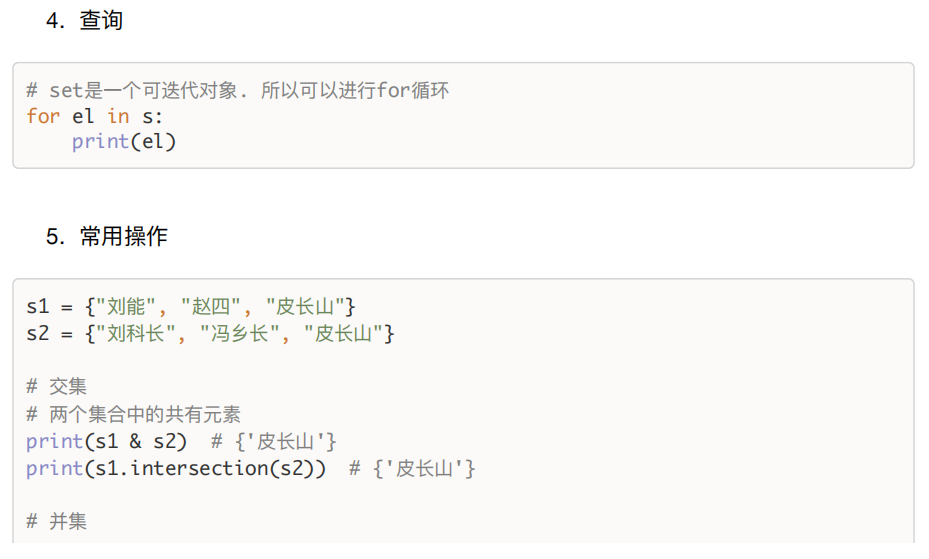
二、set集合
特点:无序不重复,内部元素必须可哈希
dic = {"a":"哇哈哈", "a":"爽歪歪"}
print(dic) # key 不会重复
结果:
{'a': '爽歪歪'}

三、深浅拷贝
作用: 快速创建对象
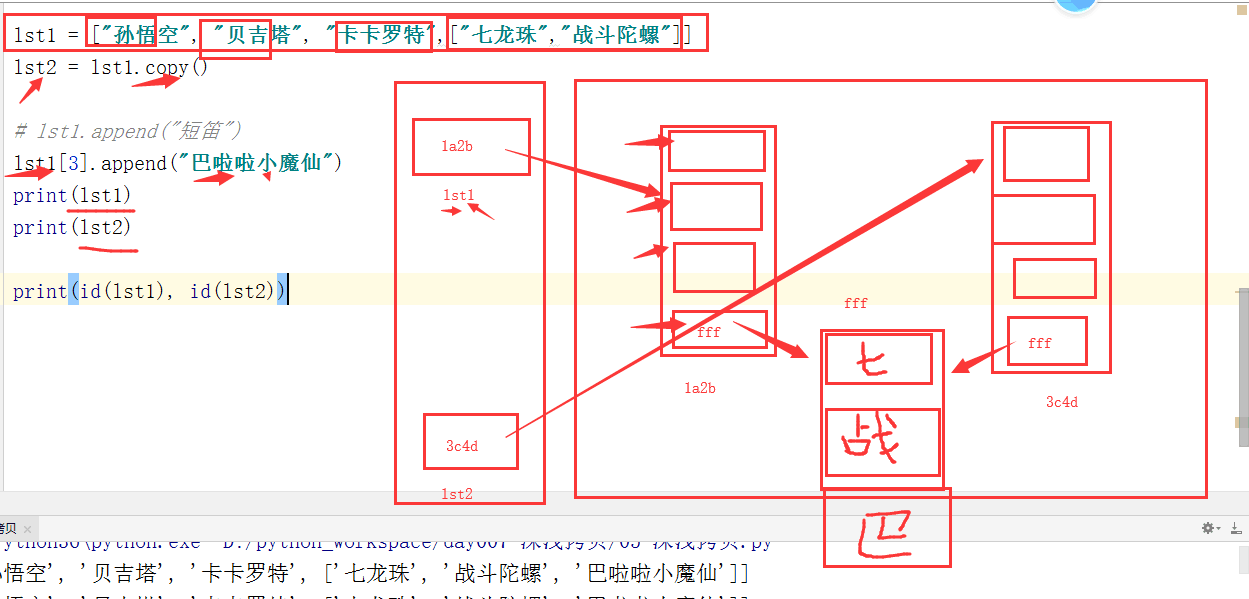
1.浅拷贝
浅拷贝. 只会拷贝第一层. 第二层的内容不会拷贝. 所以被称为浅拷贝 copy() [:]
2.深拷贝
深度拷贝. 把元素内部的元素完全进行拷贝复制. 不会产生一个改变另一个跟着改变的问题
import copy
copy.deepcopy()

深浅拷贝
lst1 = ["太白","日天","哪吒","银王","金王"] lst2 = lst1 lst1.append("女神") print(lst1,lst2) print(id(lst1)) print(id(lst2))
结果:
['太白', '日天', '哪吒', '银王', '金王', '女神'] ['太白', '日天', '哪吒', '银王', '金王', '女神']
50071112
50071112
浅拷贝,
lst1 = ["太白","日天","哪吒","银王","金王"] lst2 = lst1[:] # 创建了新列表 lst2 = lst1.copy() # 会创建新对象, 创建对象的速度会很快. lst1.append("女神") print(lst1) print(lst2)
结果:
['太白', '日天', '哪吒', '银王', '金王', '女神']
['太白', '日天', '哪吒', '银王', '金王']
lst1 = ["太白","日天",["盖浇饭", "锅包肉", "吱吱冒油的猪蹄子"],"哪吒","银王","金王"] lst2 = lst1.copy() # 会创建新对象, 创建对象的速度会很快. lst1[2].append("油泼扯面") print(id(lst1[2]), id(lst2[2]))
结果:
15992392 15992392
深拷贝
导入拷贝模块 import copy lst1 = ["太白","日天",["盖浇饭", "锅包肉", "吱吱冒油的猪蹄子"],"哪吒","银王","金王"] lst2 = copy.deepcopy(lst1) print(id(lst1[2]), id(lst2[2]))
结果:
46719864 46720824 赋值没有创建新对象。多个变量共享同一个对象 浅拷贝。 会创建新对象。 新的对象中里面的内容不会被拷贝 深拷贝。 创建一个一摸一样的完全新的对象。 这个对象延伸出来的内容也会跟着复制一份