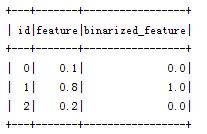
二元化(Binarization)是通过(选定的)阈值将数值化的特征转换成二进制(0/1)特征表示的过程。
Binarizer(ML提供的二元化方法)二元化涉及的参数有inputCol(输入)、outputCol(输出)以及threshold(阀值)。(输入的)特征值大于阀值将映射为1.0,特征值小于等于阀值将映射为0.0。(Binarizer)支持向量(Vector)和双精度(Double)类型的输出
package ml
import java.util
import org.apache.spark.ml.feature.Binarizer
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{Row, DataFrame, SQLContext}
import org.apache.spark.sql.types.{DataTypes, StructField}
import org.apache.spark.{SparkContext, SparkConf}
/**
* Created by Administrator on 2017/6/6.
*/
/*
二元化(Binarization)是通过(选定的)阈值将数值化的特征转换成二进制(0/1)特征表示的过程。
Binarizer(ML提供的二元化方法)二元化涉及的参数有inputCol(输入)、outputCol(输出)以及threshold(阀值)。
(输入的)特征值大于阀值将映射为1.0,特征值小于等于阀值将映射为0.0。(Binarizer)支持向量(Vector)和双精度(Double)类型的输出
* */
object Binarizer1 {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("test").setMaster("local")
val sc = new SparkContext(conf)
val sql = new SQLContext(sc);
val fields = new util.ArrayList[StructField];
fields.add(DataTypes.createStructField("id", DataTypes.IntegerType, true));
fields.add(DataTypes.createStructField("feature", DataTypes.DoubleType, true));
val data = Array((0, 0.1), (1, 0.8), (2, 0.2))
val structType = DataTypes.createStructType(fields);
val d: RDD[(Int, Double)] = sc.parallelize(data)
val row = d.map {
row => Row(Integer.valueOf(row._1), row._2)
}
val df: DataFrame = sql.createDataFrame(row, structType)
df.printSchema()
df.show()
val binarizer: Binarizer = new Binarizer()
.setInputCol("feature")
.setOutputCol("binarized_feature")
.setThreshold(0.5)
val binarizedDataFrame = binarizer.transform(df)
println(s"Binarizer output with Threshold = ${binarizer.getThreshold}")
binarizedDataFrame.show()
}
}