引言
关于java中的不常见模块,让我一下子想我也想不出来,所以我希望以后每次遇到的时候我就加一篇。上次有人建议我写全所有常用的Map,所以我研究了一晚上LinkedHashMap,把自己感悟到的解释给大家。在本篇博文中,我会用一个例子展现LinkedHashMap的运行和初始化情况,展示LinkedHashMap的数据存储情况,同时用JDK1.8中它的源代码解释给大家。其实,在以前的博文中我就已经粗略的介绍过了,关于缓存机制的实现:http://blog.csdn.net/u012403290/article/details/68926201中就涉及到了LinkedHashMap,不过今天我们会从源码解释它为什么可以实现LRU(最近最少使用)缓存。最后,笔者目前整理的一些blog针对面试都是超高频出现的。大家可以点击链接:http://blog.csdn.net/u012403290。
注意
我希望看这篇的文章的小伙伴如果没有了解过HashMap那么可以先看看我这篇文章:http://blog.csdn.net/u012403290/article/details/65442646,在这篇文章中我详细介绍了HashMap的底层实现和一些常见的成员变量。只有在对HashMap有一定的了解之后,才能很好的理解LinkedHashMap,因为它是继承HashMap实现的。所以对于加载因子,容量,桶的概念就不再赘述。
数据存储结构
我们已经知道HashMap是以散列表的形式存储数据的,LinkedHashMap继承了HashMap,所以LinkedHashMap其实也是散列表的结构,但是“linked”是它对HashMap功能的进一步增强,LinkedHashMap用双向链表的结构,把所有存储在HashMap中的数据连接起来。有人会说散列表不是已经有了链表的存储结构了嘛,为什么还要来个双向链表?桶(桶的概念就是数组的一个存储节点,比如说arr[0]是一个桶,arr[1]也是一个桶)中的链表和这个双向链表是两个概念,以下是我总结的区别:①桶中的链表是散列表结构的一部分;而双向链表是LinkedHashMap的额外引入;②桶中的链表只做数据存储,没有存储顺序的概念;双向链表的核心就是控制数据存储顺序(存储顺序是LinkedHashMap的核心);③桶中的链表产生是因为发生了hash碰撞,导致数据散落在一个桶中,用链表给予存储,所以这个链表控制了一个桶;双向链表是要串连所有的数据,也就是说有桶中的数据都是会被这个双向链表管理。
所以,我修改了HashMap的图片,大家参考下: 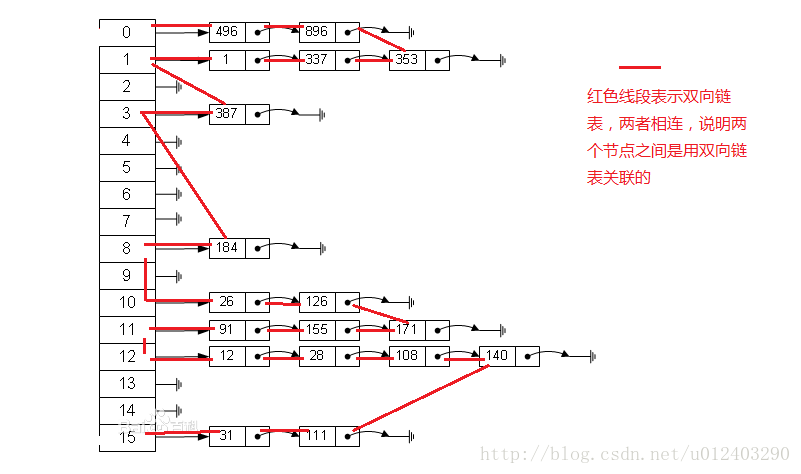
所以,简单来说就是LinkedHashMap相比于HashMap来说就是多了这些红色的双向链表而已。
两种演示
LinkedHashMap的核心就是存在存储顺序和可以实现LRU算法,所以下面我会用两个demo先来证明这两种情况:
①、放入到LinkedHashMap是有顺序的,会按照你放入的顺序存储:
package com.brickworkers;
import java.util.LinkedHashMap;
/**
* @author Brickworker
* Date:2017年4月12日下午12:46:25
* 关于类LinkedHashMapTest.java的描述:jdk1.8逐字逐句带你理解linkedHashMap
* Copyright (c) 2017, brcikworker All Rights Reserved.
*/
public class LinkedHashMapTest {
public static void main(String[] args) {
LinkedHashMap<Integer, Integer> map = new LinkedHashMap<Integer, Integer>();
for (int i = 0; i < 10; i++) {//按顺序放入1~9
map.put(i, i);
}
System.out.println("原数据:"+map.toString());
map.get(3);
System.out.println("查询存在的某一个:"+map.toString());
map.put(4, 4);
System.out.println("插入已存在的某一个:"+map.toString()); //直接调用已存在的toString方法,不然自己需要用迭代器实现
map.put(10, 10);
System.out.println("插入一个原本没存在的:"+map.toString());
}
//输出结果
// 原数据:{0=0, 1=1, 2=2, 3=3, 4=4, 5=5, 6=6, 7=7, 8=8, 9=9}
// 查询存在的某一个:{0=0, 1=1, 2=2, 3=3, 4=4, 5=5, 6=6, 7=7, 8=8, 9=9}
// 插入已存在的某一个:{0=0, 1=1, 2=2, 3=3, 4=4, 5=5, 6=6, 7=7, 8=8, 9=9}
// 插入一个原本没存在的:{0=0, 1=1, 2=2, 3=3, 4=4, 5=5, 6=6, 7=7, 8=8, 9=9, 10=10}
}
观察以上代码,其实它是符合先进先出的规则的,不管你怎么查询插入已存在的数据,不会对排序造成影响,如果有新插入的数据将会放在最尾部。
②了解,启用LRU规则的LinkedHashMap,启动这个规则需要在构造LinkedHashMap的时候,调用三个参数的构造器,这个构造器源码如下:
/**
* Constructs an empty <tt>LinkedHashMap</tt> instance with the
* specified initial capacity, load factor and ordering mode.
*
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @param accessOrder the ordering mode - <tt>true</tt> for
* access-order, <tt>false</tt> for insertion-order
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;//是否开启LRU规则
}第三个参数accessOrder就是用于控制LRU规则的。
如下就是我写的demo:
package com.brickworkers;
import java.util.LinkedHashMap;
/**
* @author Brickworker
* Date:2017年4月12日下午12:46:25
* 关于类LinkedHashMapTest.java的描述:jdk1.8逐字逐句带你理解linkedHashMap
* Copyright (c) 2017, brcikworker All Rights Reserved.
*/
public class LinkedHashMapTest {
public static void main(String[] args) {
LinkedHashMap<Integer, Integer> map = new LinkedHashMap<Integer, Integer>(20, 0.75f, true);
for (int i = 0; i < 10; i++) {//按顺序放入1~9
map.put(i, i);
}
System.out.println("原数据:"+map.toString());
map.get(3);
System.out.println("查询存在的某一个:"+map.toString());
map.put(4, 4);
System.out.println("插入已存在的某一个:"+map.toString()); //直接调用已存在的toString方法,不然自己需要用迭代器实现
map.put(10, 10);
System.out.println("插入一个原本没存在的:"+map.toString());
}
//输出结果
// 原数据:{0=0, 1=1, 2=2, 3=3, 4=4, 5=5, 6=6, 7=7, 8=8, 9=9}
// 查询存在的某一个:{0=0, 1=1, 2=2, 4=4, 5=5, 6=6, 7=7, 8=8, 9=9, 3=3} //被访问(get)的3放到了最后面
// 插入已存在的某一个:{0=0, 1=1, 2=2, 5=5, 6=6, 7=7, 8=8, 9=9, 3=3, 4=4}//被访问(put)的4放到了最后面
// 插入一个原本没存在的:{0=0, 1=1, 2=2, 5=5, 6=6, 7=7, 8=8, 9=9, 3=3, 4=4, 10=10}//新增一个放到最后面
}从上面可以看出,每当我get或者put一个已存在的数据,就会把这个数据放到双向链表的尾部,put一个新的数据也会放到双向链表的尾部。
逐字逐句底层源码
接下来我们通过源码深入学习LinkedHash,同时解答上述出现的有趣的事情。
①分析LinkedHashMap的类名和继承关系:
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>
{从这里我们可以看出LinkedHashMap是继承了HashMap并实现了Map接口的,所以它和HashMap的关系肯定不一般。
②分析LinkedHashMap的构造函数:
//1
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
//2
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
//3
public LinkedHashMap() {
super();
accessOrder = false;
}
//4
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super();
accessOrder = false;
putMapEntries(m, false);
}
//5
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}它具有5个构造函数,可以设置容量和加载因子,且在默认情况下是不开启LRU规则的。同时它还以用具有继承K,V关系的map进行初始化。
③分析双向链表
/**
* HashMap.Node subclass for normal LinkedHashMap entries.
*/
static class Entry<K,V> extends HashMap.Node<K,V> {
//前后指针
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
/**
* The head (eldest) of the doubly linked list.
*/
transient LinkedHashMap.Entry<K,V> head;//双向链表头节点(最老)
/**
* The tail (youngest) of the doubly linked list.
*/
transient LinkedHashMap.Entry<K,V> tail;//双向列表尾节点(最新)用一个静态内部类Entry表示双向链表,实现了HashMap中的Node内部类。before和after表示前后指针。我们在使用LinkedHashMap有序就是因此产生。
④分析LRU规则实现,最近访问放在双向链表最后面
void afterNodeAccess(Node<K,V> e) { // 把当前节点e放到双向链表尾部
LinkedHashMap.Entry<K,V> last;
//accessOrder就是我们前面说的LRU控制,当它为true,同时e对象不是尾节点(如果访问尾节点就不需要设置,该方法就是把节点放置到尾节点)
if (accessOrder && (last = tail) != e) {
//用a和b分别记录该节点前面和后面的节点
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
//释放当前节点与后节点的关系
p.after = null;
//如果当前节点的前节点是空,
if (b == null)
//那么头节点就设置为a
head = a;
else
//如果b不为null,那么b的后节点指向a
b.after = a;
//如果a节点不为空
if (a != null)
//a的后节点指向b
a.before = b;
else
//如果a为空,那么b就是尾节点
last = b;
//如果尾节点为空
if (last == null)
//那么p为头节点
head = p;
else {
//否则就把p放到双向链表最尾处
p.before = last;
last.after = p;
}
//设置尾节点为P
tail = p;
//LinkedHashMap对象操作次数+1
++modCount;
}
}afterNodeAccess方法就是如何支持LRU规则的,如果在accessOrder为true的时候,节点调用这个函数,就会把该节点放置到最后面。put,get等都会调用这个函数来调整顺序,我手画了一张图来表示这个函数干了些什么:
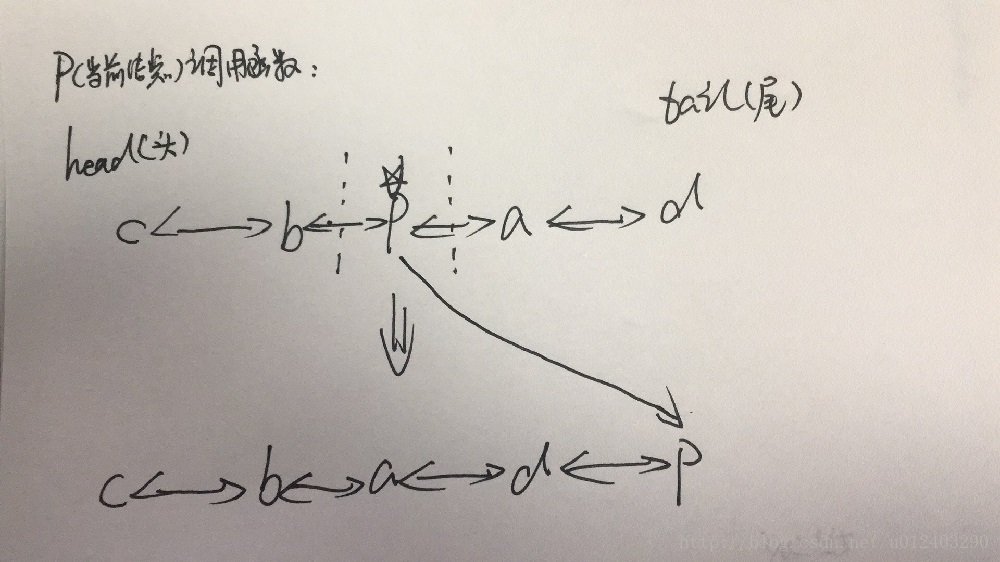
我们看看get方法中是否调用了此函数,以下是LinkedHashMap重写了HashMap的get方法:
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)//如果启用了LRU规则
afterNodeAccess(e);//那么把该节点移到双向链表最后面
return e.value;
}那么有些小伙伴就问了,那么put方法里面调用了嘛?肯定调用了,但是你不一定找得到,因为LinkedHashMap压根没有重写put方法,每次用LinkedHashMap的put方法的时候,其实你调用的都是HashMap的put方法。那为什么它也会执行afterNodeAccess()方法呢,因为这个方法HashMap就是存在的,但是没有实现,LinkedHashMap重写了afterNodeAccess()这个方法。下面给出HashMap的put局部方法:
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);//把当前节点移动到双向链表最尾处
return oldValue;
}其实这个方法在很多的调用都有,这里就不一一解释了。同时,LinkedHashMap对于红黑树的节点移动处理也有专门的方法,这里就不再深入讲解了,方式也是差不多。
⑤分析一个LinkedHashMap自带的移除最头(最老)数据的方法
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}LinkedHashMap有一个自带的移除最老数据的方法,但是这个方法永远是返回false,但是如果我们要实现,可以在继承的时候重写这个方法,给定一个条件就可以控制存储在LinkedHashMap中的最老数据何时删除。具体的在我以前博文多种方式实现缓存机制中有写过。触发这个删除机制,一般是在PUT一个数据进入的时候,但是LinkedHashMap并没有重写Put方法如何实现呢?在LinekdHashMap中,这个方法被包含在afterNodeInsertion()方法之中,而这个方法是重写了HashMap的,但是HashMap中并没有去实现它,所以在put的时候就会触发删除这个机制。
尾记
技术是不断前进的,或许在JDK1.8的时候我写的这些是有用的,但是下一个版本出来就不一定了。比如说前面几个版本中,LinkedHashMap是一个循环的双向链表,而且需要用init()方法进行初始化,但是后来都被移除了,以下是部分原本的linkedHashMap源码:
void init() {
header = new Entry<K,V>(-1, null, null, null);
header.before = header.after = header; //循环的双向链表
} 所以,在日常的学习中,尤其是技术,要与时俱进,在查询某个技术点的时候,千万要注意版本号,不一样的版本之间可能是天差地别的。
转载:https://blog.csdn.net/u012403290/article/details/70143443?locationNum=14&fps=1