部分摘自:http://blog.csdn.net/u010342038/article/details/52997388
界面:
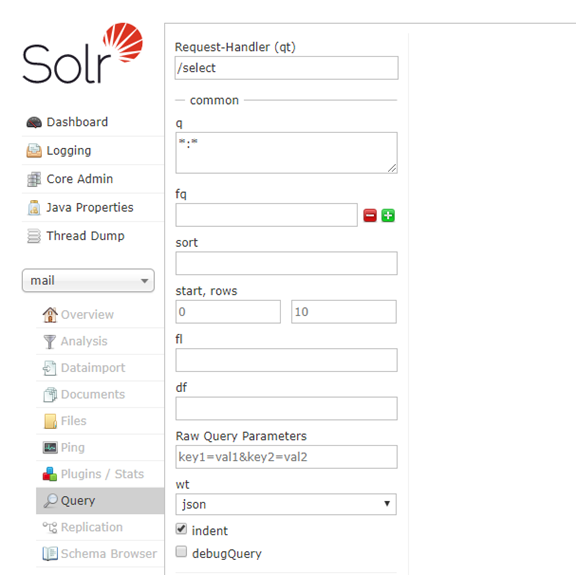
参数说明:
注意,以下是对所有的查询解析器都通用的参数。
defType :选择用来处理查询的查询分析器。
q (query)查询的关键字,此参数最为重要,例如,q=id:1,默认为q=*:*,
fq (filter query)过虑查询,提供一个可选的筛选器查询。返回在q查询符合结果中同时符合的fq条件的查询结果,例如:q=id:1&fq=sort:[1 TO 5],找关键字id为1 的,并且sort是1到5之间的。
sort 排序方式,例如id desc 表示按照 "id" 降序
start 返结果的第几条记录开始,一般分页用,默认0开始
rows 指定返回结果最多有多少条记录,默认值为 10,配合start实现分页
fl (field list) 指定返回哪些字段,用逗号或空格分隔,注意:字段区分大小写,例如,fl= id,title,sort
回
df (default field) 默认的查询字段,一般默认指定。
wt (writer type)指定输出格式,有 xml, json, php等
indent 返回的结果是否缩进,默认关闭,用 indent=true|on 开启,一般调试json,php,phps,ruby输出才有必要用这个参数。
version 查询语法的版本,建议不使用它,由服务器指定默认值。
详细参数说明
- defType
参数defType指定Solr执行主查询时使用的查询解析器。比如:defType=dismax。
如果没有指定defType,将默认使用标准个查询解析器。
- sort
参数sort指定查询结果升序或降序。这个参数可以作用于数字或字母内容。可以使用全消息或全大写。(比如,全是asc或ASC)。
Solr可以根据文档分值或其他被索引或使用DocValues(即,在schema.xml文件中使用multiValued="false"和docValues="true"或者indexed="true"的字段,如果没有启用DocValues,将使用检索数据)的单值字段值来进行排序。提供:
没有进行标记(即,字段没有analyzer,并且内容被解析进标记,致使排序不一致),或
使用分析器analyzer(比如KeywordTokenizer)且只产生一个检索词。
如果你向对一个需要进行标记便于检索的字段排序,可以在schema.xml文件中使用<copyField>指定复制字段。然后就可以查询该字段,在克隆字段上排序。
下面的表格将说明如果设置各种参数来对Solr响应进行排序:
|
示例 |
结果 |
|
如果没有指定参数sort,将根据打分降序排列。 |
|
|
score desc |
根据打分从高到底降序排列。 |
|
price asc |
根据字段price升序排列。 |
|
inStock desc, price asc |
根据字段inStock降序排列,然后根据字段price升序排列。 |
关于排序参数:
排序必须包含一个字段名(或打分),之后跟一个空白字符(在URL字符串中使用+或%20),之后跟排序方向(asc或desc)。
多种排序规则可以使用逗号隔开,使用这样的语法:sort=<field name>+<direction>,<field name>+<direction>],...
如果有多个排序条件,只有在第一个排序结果并列,第二个才生效。如果有第三个从句,只有当第一个和第二个都并列相同时,才生效。依次类推。
- start
该参数指定Solr查询响应展示内容的偏移量。默认值是0.换句话说,默认情况下,Solr返回的结果没有偏移,从头开始。设置一个值,比如3,Solr将跳过前面 几条数据,从指定偏移位置开始返回。你可以使用这种方式来分页。比如,如果参数rows设置为10,可以通过设置start为0来连续返回几页数据,然后使用相同的查询参数,设置start为10,再次查询,然后设置20.
- rows
可以使用参数rows来进行分页查询。这个参数指定了一次查询最大返回文档的数目。默认值是10.就是说,默认一次查询返回10个文档数据。
- fq
参数fq可以定义一个限制返回文档父集,不影响评分。通过指定参数fq将缓存主查询,用来提高复杂查询速度。当之后使用相同的过滤器,将会命中缓存,缓存中的结果立即返回。
使用参数fq时,需要注意:
参数fq可以在一个查询中指定多次。只有每个参数实例的交集才能返回。在下面的例子中,只有popularity大于10且section是0的才能返回。fq=popularity:[10 TO *]&fq=section:0
过滤查询可以包含复杂的布尔查询。上面的例子也可以使用两个从句一个fq实现:fq=+popularity:[10 TO *] +section:0。
每个过滤查询的文档集都是独立缓存的。一次,关于签名的例子:使用一个fq两个从句,和使用两个分开的fq将不想同(了解调整高速缓存大小和确保过滤缓存,看配置Solr实例)。
对所有参数:在URL中特殊字符需要进行转移为十六进制。在线工具http://meyerweb.com/eric/tools/dencoder/可以提供这种转码。
- fl
参数fl限制响应信息中包含的字段列表。该字段需要在索引时被存储。
字段列表可以通过空格或逗号分割。字符串"score"可以被用来指明特定查询的每个文档的分数作为字段返回。通配符"*"表示文档的所有字段。可以添加伪字段、函数、transformers作为字段返回。
下表是如果使用fl的基础示例:
|
字段 |
结果 |
|
id name price |
只返回id, name, 和 price |
|
id,name,price |
只返回id, name, 和 price |
|
id name, price |
只返回id, name, 和 price |
|
id score |
只返回id和score |
|
* |
返回文档所有字段。这是参数fl默认值。 |
|
* score |
返回文档所有字段,以及每个文档的分值。 |
Function Values
函数可以为结果中每一个文档计算结果,并返回伪字段:fl=id,title,product(price,popularity)。
Document Transformers
Document Transformers可以用来修改查询结果中的每一个文件的返回信息:fl=id,title,[explain]。
Field Name Aliases
可以指定字段、函数、transformer的显示名,比如:fl=id,sales_price:price,secret_sauce:prod(price,popularity),why_score:[explain style=nl],
"response":{"numFound":2,"start":0,"docs":[
{
"id":"6H500F0",
"secret_sauce":2100.0,
"sales_price":350.0,
"why_score":{
"match":true,
"value":1.052226,
"description":"weight(features:cache in 2) [DefaultSimilarity], result of:",
"details":[{
...
- debug
参数debug可以指定多次,并支持以下参数:
debug=query: 至返回查询的调试信息
debug=timing: 返回查询执行时间的调试信息
debug=results: 返回结果分值的调试信息
debug=all: 返回所有的调试信息(也可以使用debug=true)
为了向后兼容,debugQuery=true可以使用debug=all替代。
默认查询不包括调试信息。
- explainOther
参数explainOther指定Lucene查询来标记文档集。如果非空,本次查询将返回调试信息,以及主查询(指定q参数)查询文档集的解释信息。比如:q=supervillians&debugQuery=on&explainOther=id:juggernaut。
上面的查询允许你检查最佳匹配的分值解释信息,可以与id:juggernaut进行比较,可以知道为什么不是你期望的排名。
默认参数为空,没有额外解释信息返回。
- timeAllowed
This parameter specifies the amount of time, in milliseconds, allowed for a search to complete. If this time expires before the search is complete, any partial results will be returned.
此参数指定允许搜索完成的时间,以毫秒为单位。如果处理超时,只返回部分信息。
- omitHeader
This parameter may be set to either true or false.
该参数可以设置为true或false。
如果设置为true,返回结果中不包含header数据。header数据包括请求信息,比如请求完成时间。默认是false。
- wt
指定用于格式化响应结果的请求writer。详细信息查看Response Writers。
- cache=false
Solr默认缓存所有的查询、过滤查询结果。为了禁用缓存,设置参数cache=false。
还可以使用cost选项来控制非缓存的过滤查询。这允许你能够指定低耗非缓存过滤,而不是高耗非缓存过滤器。
对于高耗过滤器,如果cache=false,cost>=100,查询实现了PostFilter,在匹配主查询和其他过滤查询之后,一个收集器将被请求来进行查询和过滤文档。可以有多个后置过滤器,可以根据cost配置。
比如:
// normal function range query used as a filter, all matching documents
// generated up front and cached
fq={!frange l=10 u=100}mul(popularity,price)
// function range query run in parallel with the main query like a traditional
// lucene filter
fq={!frange l=10 u=100 cache=false}mul(popularity,price)
// function range query checked after each document that already matches the query
// and all other filters. Good for really expensive function queries.
fq={!frange l=10 u=100 cache=false cost=100}mul(popularity,price)
logParamsList
默认情况下,Solr日志记录所有请求参数。从4.7版本开始,可以设置参数来限制哪些参数被记录。这有助于记录你认为比较重要的参数。比如,你可以定义:logParamsList=q,fq。只有q和fq参数会被记录。
如果不希望记录任何参数,你可以给参数logParamsList赋空值(比如:logParamsList=)。
检索运算符
|
参数 |
描述 |
|
: |
指定要查找的字段,比如:title:"The Right Way" AND text:go |
|
? |
匹配单一字符,比如:te?t匹配test/text |
|
* |
匹配0或多个字符,比如:tes*匹配test/testing/tester 注意使用*开头的匹配会导致性能问题 |
|
~ |
基于编辑距离的模糊查询,比如:roam~匹配roams/foam/foams/roam. roam~1(指定距离必须是1)匹配roams/foam,但不会匹配foams |
|
~n |
邻近查询,查找相隔一定距离的单词,比如:"jakarta apache"~10(相隔10个单词) |
|
to |
范围查询,{}不包含边界,[]包含边界,比如:title:{Aida TO Carmen} |
|
^ |
加权因子,比如:jakarta^4 apache 查找结果中jakarta更相关 注意基本权重是1,如果小于1那么会被惩罚,大于1是加大。 |
|
^= |
指定查询语句的score得分为常量,比如:(description:blue OR color:blue)^=1.0 text:shoes |
|
AND(&&) |
运算符两边的查询词同时出现 比如:"jakarta apache" AND "Apache Lucene" 注意这里的AND和OR必须为大写 |
|
OR |
运算符两边的查询词至少一个出现, 默认运算符,比如 "jakarta apache" jakarta 等价于 "jakarta apache" OR jakarta |
|
NOT(!) |
运算符后面的查询词不出现,比如"jakarta apache" NOT "Apache Lucene" |
|
+ |
运算符后面的查询词出现(known as the "required" operator),比如+jakarta lucene查询必须包含jakarta,而lucene可以出现可不出现 |
|
- |
不能包含运算符后面的查询词 "jakarta apache" -"Apache Lucene" |
|
[] |
包含范围边界 |
|
{} |
不包含范围边界 |
注意:使用+和-比AND更加明了,建议使用这个。
短语查询:如"zjf xhj"将引号内的内容作为一个整体。
注意:通配符*和?不支持短语查询()
转义字符
+ - && || ! ( ) { } [ ] ^ " ~ * ? : /
这些字符在solr中具有特殊的含义,如果要使用这么字符本身含义,需要利用反斜杠进行转义,比如: (1+1):2
子查询语句
(jakarta OR apache) AND website 查询jakarta或apache出现,并且website必须出现 title:(+return +"pink panther") 查询title中包含return和"pink panther"
关于AND和OR的用法:
假如有这两条数据:

第1条id为1,第2条id为2,。
content:zjf hello代表content:zjf OR hello 这里的hello并不是在content中查找,而是在默认搜索字段上查找的。
content:zjf content:hello 代表content中有zjf或者hello关键字,等于:content:(zjf hello)
大部分情况下我们在一个字段上进行检索,所以会设置默认搜索字段。所以AND和OR的一般使用场景是zjf AND xhj这种。
短语查询:当我们输入 zjf xhj的时候,是一种或的关系,如果我们需要检索"zjf xhj"整体,那么就需要用引号括起来。
使用soloJ的方式:
String params = "(title:笔记 OR content:笔记) AND catalog_id:2";
SolrQuery query = new SolrQuery();
query.setQuery(params);
设置默认查询字段的两种方式:
schema.xml中defaultSearchField和solrconfig.xml中df属性都是默认搜索字段的意思,不过后者只针对"/select"请求。优先级是solrconfig.xml的df高于schema.xml的defaultSearchField。
solrconfig中的例子:
<requestHandler name="/select" class="solr.SearchHandler">
<!-- default values for query parameters can be specified, these
will be overridden by parameters in the request
-->
<lst name="defaults">
<str name="echoParams">explicit</str>
<int name="rows">10</int>
<str name="df">text</str>
</lst>
</requestHandler>
也可以在http请求中加入df参数控制本次请求的的默认搜索字段
|
字段名称 |
字段含义 |
|
|
indexed |
如果该字段是要做查询的,需要将其设置为indexed,进行索引,以便能够根据该字段进行查询。 但是与具体分词手段无关,如果涉及到如果分词,需要使用type属性 |
|
|
stored |
在solr查询结果中能够正常返回,如果一个字段stored=false,则查询结果不会包括该字段。 |
也就是说,只有配置了indexed=true的列才可以查询,只有配置stored=true的列才可以返回结果。
q和fq的顺序:
fq有可能从缓存中获取,所以一般是先执行fq,然后将fq结果和q一起传给lucene去检索数据。