一、ES集群
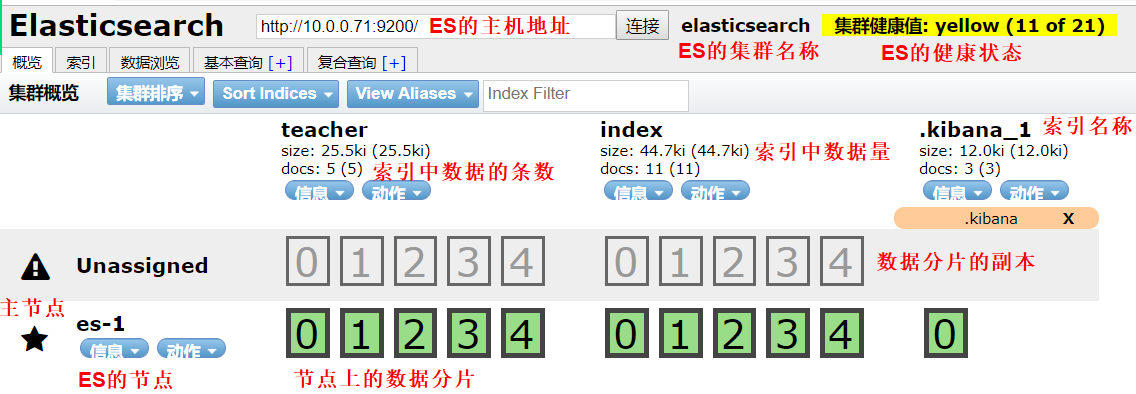
1.ES插件页面
1)集群状态
1.红色:数据不完整
2.黄色:数据完整,但是副本有问题
3.绿色:数据和副本全部都没有问题,集群状态正常
2)节点类型
1.主节点:负责调度分配数据存储
2.数据节点:负责储存由主机点传来的数据
3)分片
1.主分片:存储数据,负责读写数据
2.副本分片:主分片的备份,当主分片故障时,提供有问题的数据
二 、搭建集群
1)准备服务器
| 主机 |
IP |
| es01 |
10.0.0.71 |
| es02 |
10.0.0.72 |
| es03 |
10.0.0.73 |
2)时间同步
[root@es01 ~]# ntpdate time1.aliyun.com
[root@es02 ~]# ntpdate time1.aliyun.com
[root@es03 ~]# ntpdate time1.aliyun.com
3)安装java环境
[root@es01 ~]# scp jdk-8u181-linux-x64.rpm 172.16.1.72:/root/
[root@es01 ~]# scp jdk-8u181-linux-x64.rpm 172.16.1.73:/root/
[root@es01 ~]# yum localinstall -y jdk-8u181-linux-x64.rpm
[root@es02 ~]# yum localinstall -y jdk-8u181-linux-x64.rpm
[root@es03 ~]# yum localinstall -y jdk-8u181-linux-x64.rpm
4)安装ES
[root@es01 ~]# scp elasticsearch-6.6.0.rpm 172.16.1.72:/root
[root@es01 ~]# scp elasticsearch-6.6.0.rpm 172.16.1.73:/root
[root@es01 ~]# rpm -ivh elasticsearch-6.6.0.rpm
[root@es02 ~]# rpm -ivh elasticsearch-6.6.0.rpm
[root@es03 ~]# rpm -ivh elasticsearch-6.6.0.rpm
[root@es01 ~]# systemctl daemon-reload
[root@es02 ~]# systemctl daemon-reload
[root@es03 ~]# systemctl daemon-reload
5)配置ES
1>第一台机器的配置
[root@es01 ~]# grep '^[a-z]' /etc/elasticsearch/elasticsearch.yml
#集群的名称
cluster.name: es-cluster
node.name: es-1
path.data: /data/es/data
path.logs: /data/es/log
bootstrap.memory_lock: true
network.host: 10.0.0.71,127.0.0.1,172.16.1.71
http.port: 9200
#集群中的服务器ip地址
discovery.zen.ping.unicast.hosts: ["172.16.1.71", "172.16.1.72"]
#选举主节点时投票的机器数
discovery.zen.minimum_master_nodes: 2
2>第二台机器的配置
[root@es02 ~]# grep '^[a-z]' /etc/elasticsearch/elasticsearch.yml
cluster.name: es-cluster
node.name: es-2
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
bootstrap.memory_lock: true
network.host: 172.16.1.72,10.0.0.72,127.0.0.1
http.port: 9200
discovery.zen.ping.unicast.hosts: ["172.16.1.72", "172.16.1.73"]
discovery.zen.minimum_master_nodes: 2
3>第三台机器的配置
[root@es03 ~]# grep '^[a-z]' /etc/elasticsearch/elasticsearch.yml
cluster.name: es-cluster
node.name: es-3
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
bootstrap.memory_lock: true
network.host: 172.16.1.73,10.0.0.73,127.0.0.1
http.port: 9200
discovery.zen.ping.unicast.hosts: ["172.16.1.73", "172.16.1.71"]
discovery.zen.minimum_master_nodes: 2
4>三台机器都修改启动脚本
[root@es02 ~]# vim /usr/lib/systemd/system/elasticsearch.service
[Service]
... ...
LimitMEMLOCK=infinity
6)启动三台ES
[root@es01 ~]# systemctl start elasticsearch
[root@es01 ~]# netstat -lntp | grep java