1.手写数字数据集
- from sklearn.datasets import load_digits
- digits = load_digits()
2.图片数据预处理
- x:归一化MinMaxScaler()
- y:独热编码OneHotEncoder()或to_categorical
- 训练集测试集划分
- 张量结构
3.设计卷积神经网络结构
- 绘制模型结构图,并说明设计依据。

4.模型训练
- model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
- train_history = model.fit(x=X_train,y=y_train,validation_split=0.2, batch_size=300,epochs=10,verbose=2)
5.模型评价
- model.evaluate()
- 交叉表与交叉矩阵
- pandas.crosstab
- seaborn.heatmap
1 from sklearn.datasets import load_digits 2 from sklearn.model_selection import train_test_split 3 from sklearn.preprocessing import MinMaxScaler, OneHotEncoder 4 from tensorflow.keras.models import Sequential 5 from tensorflow.keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPool2D 6 import matplotlib.pyplot as plt 7 import numpy as np 8 import pandas as pd 9 import seaborn as sns 10 11 12 def create_dataset(): 13 digits = load_digits() 14 X_data = digits.data.astype(np.float32) 15 Y_data = digits.target.astype(np.float32).reshape(-1, 1) # 将Y_data变为一列 16 17 return X_data, Y_data 18 19 20 def process_data(X_data, Y_data): 21 # 将属性缩放到一个指定的最大和最小值(通常是1-0之间) 22 scaler = MinMaxScaler() 23 X_data = scaler.fit_transform(X_data) 24 print("MinMaxScaler_trans_X_data:") 25 print(X_data) 26 Y = OneHotEncoder().fit_transform(Y_data).todense() # 进行oe-hot编码 27 print("one-hot_Y:") 28 print(Y) 29 return X_data, Y 30 31 32 def split_dataset(X_data, Y): 33 # 转换为图片的格式(batch, height, width, channels) 34 X = X_data.reshape(-1, 8, 8, 1) 35 X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.2, random_state=0, stratify=Y) 36 print(X_train.shape, X_test.shape, y_train.shape, y_test.shape) 37 return X_train, X_test, y_train, y_test 38 39 40 def digits_model(X_train): 41 """ 构建模型 """ 42 model = Sequential() 43 44 ks = (3, 3) 45 input_shape = X_train.shape[1:] 46 47 # 一层卷积 48 model.add(Conv2D(filters=64, kernel_size=ks, padding='same', input_shape=input_shape, activation='relu')) 49 # 池化层1 50 model.add(MaxPool2D(pool_size=(2, 2))) 51 model.add(Dropout(0.2)) 52 # 二层卷积 53 model.add(Conv2D(filters=64, kernel_size=ks, padding='same', activation='relu')) 54 # 池化层2 55 model.add(MaxPool2D(pool_size=(2, 2))) 56 model.add(Dropout(0.2)) 57 58 model.add(Conv2D(filters=64, kernel_size=ks, padding='same', activation='relu')) 59 model.add(Conv2D(filters=128, kernel_size=ks, padding='same', activation='relu')) 60 model.add(MaxPool2D(pool_size=(2, 2))) 61 model.add(Dropout(0.2)) 62 63 model.add(Flatten()) # 平坦层 64 model.add(Dense(128, activation='relu')) # 全连接层 65 model.add(Dropout(0.2)) 66 model.add(Dense(10, activation='softmax')) # 激活函数 67 68 print(model.summary()) 69 70 return model 71 72 73 def train_model(model, X_train, y_train): 74 """ 训练模型 """ 75 model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) 76 train_history = model.fit(x=X_train, y=y_train, validation_split=0.2, batch_size=256, epochs=10, verbose=2) 77 return train_history 78 79 80 def score_model(model, X_test, y_test): 81 """ 评估模型 """ 82 return print(model.evaluate(X_test, y_test)[1]) 83 84 85 def test_model(model, X_test): 86 """ 测试模型 """ 87 y_pre = model.predict_classes(X_test) 88 return y_pre 89 90 91 def crossrtab_matrix(y_test, y_pre): 92 """ 93 交叉表、交叉矩阵 94 查看预测数据与原数据对比 95 """ 96 y_test = np.argmax(y_test, axis=1).reshape(-1) 97 y_test = np.array(y_test)[0] 98 # print(y_test) 99 # print(type(y_test)) 100 # print('================') 101 # print(type(y_pre)) 102 crosstab = pd.crosstab(y_test, y_pre, rownames=['labels'], colnames=['predict']) 103 matrix = pd.DataFrame(crosstab) 104 sns.heatmap(matrix, annot=True, cmap="RdPu", linewidths=0.2, linecolor='pink') 105 plt.show() 106 107 108 def show_train_history(train_history, train, validation): 109 plt.plot(train_history.history[train]) 110 plt.plot(train_history.history[validation]) 111 plt.title("Train History") 112 plt.ylabel("train") 113 plt.xlabel("epoch") 114 plt.legend(['train', 'validation'], loc='upper left') 115 plt.show() 116 117 118 if __name__ == '__main__': 119 X_data, Y_data = create_dataset() 120 X_data, Y = process_data(X_data, Y_data) 121 X_train, X_test, y_train, y_test = split_dataset(X_data, Y) 122 model = digits_model(X_train) 123 train_history = train_model(model, X_train, y_train) 124 score_model(model, X_test, y_test) 125 y_pre = test_model(model, X_test) 126 crossrtab_matrix(y_test, y_pre) 127 show_train_history(train_history, 'accuracy', 'val_accuracy') # 准确率 128 show_train_history(train_history, 'loss', 'val_loss') # 损失率
运行结果如下:
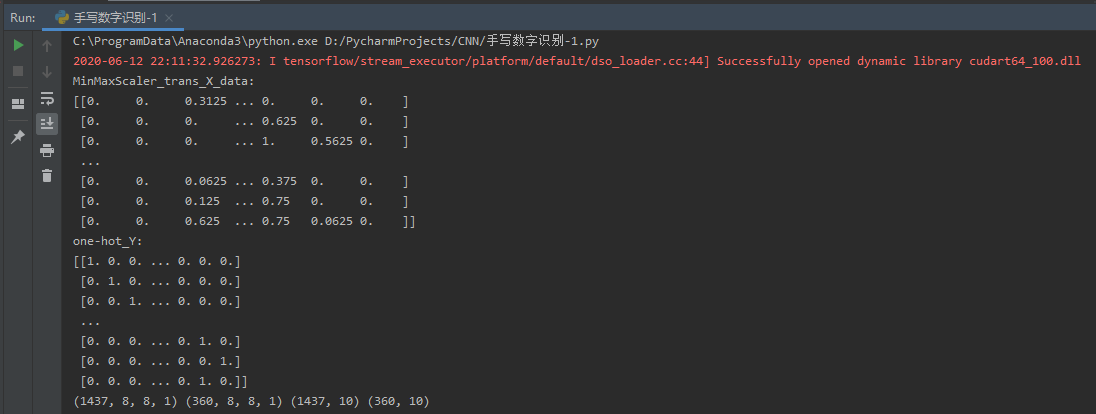
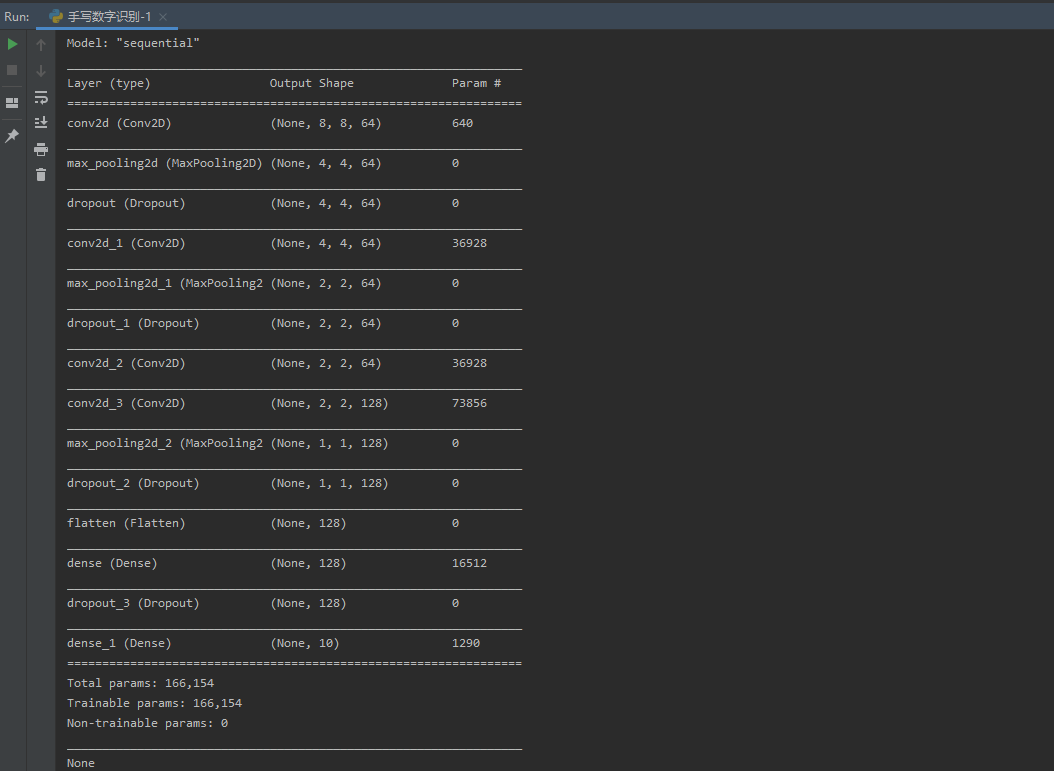
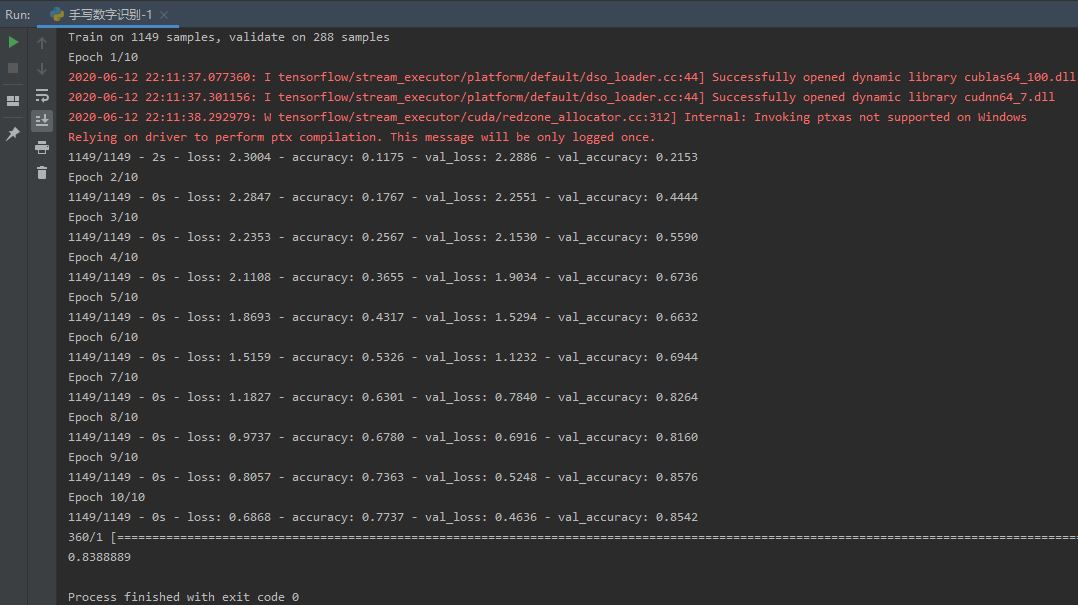
可视化展示数据训练参数最佳结果:


由上图可知,当轮数epochs为10时,损失率以及准确率达到最佳。
交叉矩阵结果:
