4. 作业:
1). 扑克牌手动演练k均值聚类过程:>30张牌,3类
- 首先,选取扑克牌中的A~8,每个数字4张牌,总共32张牌。
- 选出A、2、3作为3种类别,所有的牌根据与3种类别的距离的规律进行聚类,距离最近为一类。
第一轮:聚类中心为A、2、3(新的聚类中心为A、2、5.5(用6表示))

- 接着从上述分类完毕的牌簇中求和取平均,作为新的中心,以此类推,进行聚类,直到新的聚类中心与上一轮的聚类中心一致才停止聚类求中心的过程。
第二轮:聚类中心为A、2、5.5(用6表示)(新的聚类中心为A、2.5(用3表示)、6)

第三轮:聚类中心为A、2.5(用3表示)、6(新的聚类中心为A、2.5(用3表示)、6)

- 综上所述,此例最后的聚类中心为A、2.5(用3表示)、6。



上面的流程图可以更加直观的看到聚类算法的计算原理。
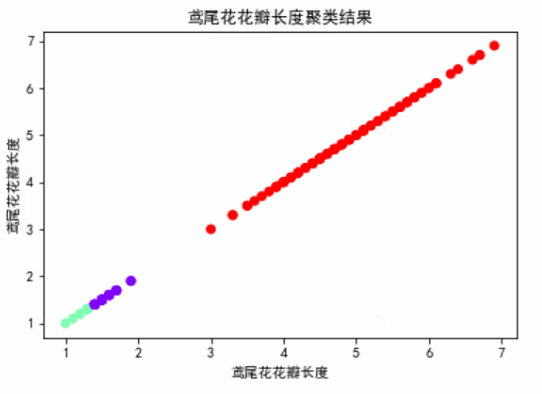
2). *自主编写K-means算法 ,以鸢尾花花瓣长度数据做聚类,并用散点图显示。(加分题)


1 ''' 2 编写K-means算法 ,以鸢尾花花瓣长度(petal length)数据做聚类,并用散点图显示。 3 ''' 4 from sklearn.datasets import load_iris 5 import numpy as np 6 7 # 导入鸢尾花数据 8 iris_data = load_iris() 9 # iris_data.keys() 10 # iris_data.feature_names 11 n = len(iris_data.data) 12 data = iris_data.data[:, 2].reshape(n, 1) 13 k = 3 14 distance_matrix = np.zeros([n, k + 1]) # 初始化距离矩阵 15 # 选中心 16 center = data[1:k+1, :] # 选择前k个样本作为初始类中心 17 # print("初始的聚类中心为: ", center) 18 center_new = np.zeros([k, 1]) 19 20 while True: 21 for i in range(n): # 求距离,此处用欧氏距离求取 22 for j in range(k): 23 distance_matrix[i, j] = np.sqrt(sum((data[i, :] - center[j, :])**2)) 24 distance_matrix[i, k] = np.argmin(distance_matrix[i, :k]) 25 for i in range(k): 26 index = distance_matrix[:, k] == i # 求类别为k的样本的索引 27 center_new[i, :] = data[index, :].mean(axis=0) # 取k类别的样本的属性值的均值,作为新的聚类中心 28 if(np.all(center == center_new)): # 当不再出现新的聚类中心,则停止计算过程,否则新的聚类中心将代替原先的聚类中心 29 break 30 else: 31 center = center_new 32 33 34 # print("最后的聚类中心为: ", center_new) 35 # 散点图 36 %matplotlib inline 37 import matplotlib.pyplot as plt 38 39 plt.scatter(iris_data.data[:, 2], iris_data.data[:, 2], c=distance_matrix[:, k], cmap='rainbow') 40 plt.title("鸢尾花花瓣长度聚类结果") 41 plt.xlabel("鸢尾花花瓣长度") 42 plt.ylabel("鸢尾花花瓣长度") 43 plt.show()
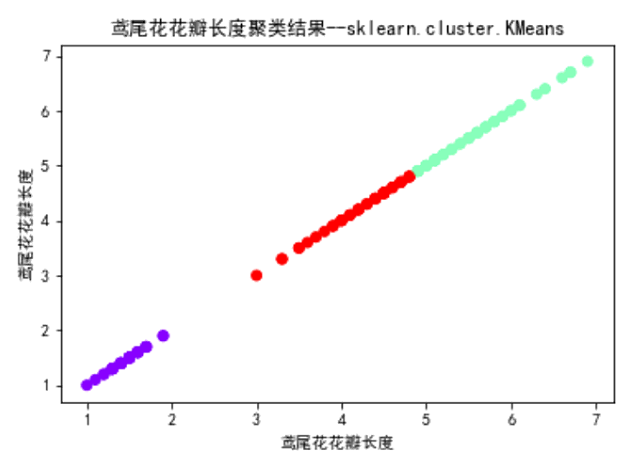
3). 用sklearn.cluster.KMeans,鸢尾花花瓣长度数据做聚类,并用散点图显示.
1 ''' 2 用sklearn.cluster.KMeans,鸢尾花花瓣长度数据做聚类,并用散点图显示 3 ''' 4 from sklearn.datasets import load_iris 5 from sklearn.cluster import KMeans 6 import matplotlib.pyplot as plt 7 %matplotlib inline 8 9 10 iris_data = load_iris() # 加载数据集 11 data = iris_data.data[:, 2].reshape(-1, 1) # 取鸢尾花的花瓣长度数据 12 13 kmeans_model = KMeans(n_clusters=3) # 构建模型 14 kmeans_model.fit(data) # 训练模型 15 y_pre = kmeans_model.predict(data) # 测试模型 16 center = kmeans_model.cluster_centers_# 聚类中心 17 plt.scatter(data[:, 0], data[:, 0], c=y_pre, cmap='rainbow') 18 plt.title("鸢尾花花瓣长度聚类结果--sklearn.cluster.KMeans") 19 plt.xlabel("鸢尾花花瓣长度") 20 plt.ylabel("鸢尾花花瓣长度") 21 plt.show()
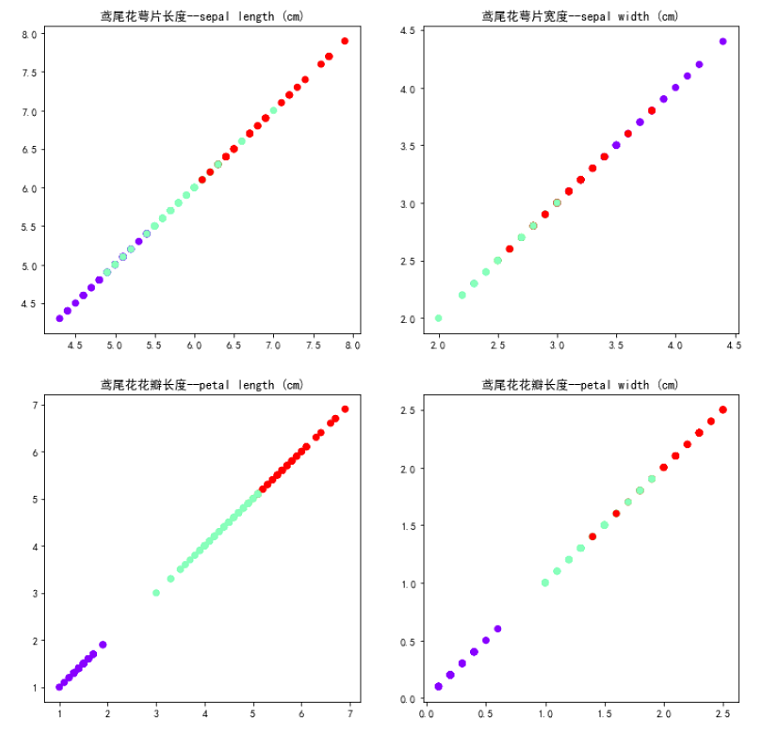
4). 鸢尾花完整数据做聚类并用散点图显示.
1 ''' 2 鸢尾花完整数据做聚类并用散点图显示. 3 ''' 4 from sklearn.datasets import load_iris 5 from sklearn.cluster import KMeans 6 import matplotlib.pyplot as plt 7 %matplotlib inline 8 9 iris_data = load_iris() # 加载数据集 10 data = iris_data.data # 取鸢尾花的花瓣长度数据 11 12 kmeans_model = KMeans(n_clusters=3) # 构建模型 13 kmeans_model.fit(data) # 训练模型 14 y_pre = kmeans_model.predict(data) # 测试模型 15 center = kmeans_model.cluster_centers_# 聚类中心 16 fig, axes = plt.subplots(2, 2, figsize=(12, 12)) 17 axes[0][0].set_title("鸢尾花萼片长度--sepal length (cm)") 18 axes[0][0].scatter(data[:, 0], data[:, 0], c=y_pre, cmap='rainbow') 19 axes[0][1].set_title("鸢尾花萼片宽度--sepal width (cm)") 20 axes[0][1].scatter(data[:, 1], data[:, 1], c=y_pre, cmap='rainbow') 21 axes[1][0].set_title("鸢尾花花瓣长度--petal length (cm)") 22 axes[1][0].scatter(data[:, 2], data[:, 2], c=y_pre, cmap='rainbow') 23 axes[1][1].set_title("鸢尾花花瓣长度--petal width (cm)") 24 axes[1][1].scatter(data[:, 3], data[:, 3], c=y_pre, cmap='rainbow') 25 plt.show()
5).想想k均值算法中以用来做什么?
k均值聚类算法顾名思义就是用来分类的,比如常见的图像分割(压缩)、文档分类、客户群体分类等等。。。
客户细分不限于银行业务,还可应用于电信、电商、体育、广告、销售等等领域;
文档聚类是更加常见的应用,加入现在我有多个文档需要分类,将同种类型的文档集中放置,那么久可以利用聚类算法的特点对这些文档进行分组归类;
图像分割是将图像中的相似像素聚集在一起创建不同的簇;
推荐引擎的话运用在多个方面,比如向好友推荐其喜欢的类似的歌曲等。