本节内容
1. 函数基本语法及特性
2. 参数与局部变量
3. 返回值
嵌套函数
4.递归
5.匿名函数
6.函数式编程介绍
7.高阶函数
8.内置函数
温故知新
1. 集合
主要作用:
- 去重
- 关系测试, 交集\差集\并集\反向(对称)差集
2. 元组
只读列表,只有count, index 2 个方法
作用:如果一些数据不想被人修改, 可以存成元组,比如身份证列表
3. 字典
key-value对
- 特性:
- 无顺序
- 去重
- 查询速度快,比列表快多了
- 比list占用内存多
为什么会查询速度会快呢?因为他是hash类型的,那什么是hash呢?
哈希算法将任意长度的二进制值映射为较短的固定长度的二进制值,这个小的二进制值称为哈希值。哈希值是一段数据唯一且极其紧凑的数值表示形式。如果散列一段明文而且哪怕只更改该段落的一个字母,随后的哈希都将产生不同的值。要找到散列为同一个值的两个不同的输入,在计算上是不可能的,所以数据的哈希值可以检验数据的完整性。一般用于快速查找和加密算法
dict会把所有的key变成hash 表,然后将这个表进行排序,这样,你通过data[key]去查data字典中一个key的时候,python会先把这个key hash成一个数字,然后拿这个数字到hash表中看没有这个数字, 如果有,拿到这个key在hash表中的索引,拿到这个索引去与此key对应的value的内存地址那取值就可以了。
上面依然没回答这样做查找一个数据为什么会比列表快,对不对? 呵呵,等我课上揭晓。
4. 字符编码
先说python2
- py2里默认编码是ascii
- 文件开头那个编码声明是告诉解释这个代码的程序 以什么编码格式 把这段代码读入到内存,因为到了内存里,这段代码其实是以bytes二进制格式存的,不过即使是2进制流,也可以按不同的编码格式转成2进制流,你懂么?
- 如果在文件头声明了#_*_coding:utf-8*_,就可以写中文了, 不声明的话,python在处理这段代码时按ascii,显然会出错, 加了这个声明后,里面的代码就全是utf-8格式了
- 在有#_*_coding:utf-8*_的情况下,你在声明变量如果写成name=u"大保健",那这个字符就是unicode格式,不加这个u,那你声明的字符串就是utf-8格式
- utf-8 to gbk怎么转,utf8先decode成unicode,再encode成gbk
再说python3
- py3里默认文件编码就是utf-8,所以可以直接写中文,也不需要文件头声明编码了,干的漂亮
- 你声明的变量默认是unicode编码,不是utf-8, 因为默认即是unicode了(不像在py2里,你想直接声明成unicode还得在变量前加个u), 此时你想转成gbk的话,直接your_str.encode("gbk")即可以
- 但py3里,你在your_str.encode("gbk")时,感觉好像还加了一个动作,就是就是encode的数据变成了bytes里,我擦,这是怎么个情况,因为在py3里,str and bytes做了明确的区分,你可以理解为bytes就是2进制流,你会说,我看到的不是010101这样的2进制呀, 那是因为python为了让你能对数据进行操作而在内存级别又帮你做了一层封装,否则让你直接看到一堆2进制,你能看出哪个字符对应哪段2进制么?什么?自己换算,得了吧,你连超过2位数的数字加减运算都费劲,还还是省省心吧。
- 那你说,在py2里好像也有bytes呀,是的,不过py2里的bytes只是对str做了个别名(python2里的str就是bytes, py3里的str是unicode),没有像py3一样给你显示的多出来一层封装,但其实其内部还是封装了的。 这么讲吧, 无论是2还是三, 从硬盘到内存,数据格式都是 010101二进制到-->b'xe4xbdxa0xe5xa5xbd' bytes类型-->按照指定编码转成你能看懂的文字
编码应用比较多的场景应该是爬虫了,互联网上很多网站用的编码格式很杂,虽然整体趋向都变成utf-8,但现在还是很杂,所以爬网页时就需要你进行各种编码的转换,不过生活正在变美好,期待一个不需要转码的世界。
最后,编码is a piece of fucking shit, noboby likes it.
1.函数基本语法及特性
背景提要
现在老板让你写一个监控程序,监控服务器的系统状况,当cpu\memory\disk等指标的使用量超过阀值时即发邮件报警,你掏空了所有的知识量,写出了以下代码
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
while True: if cpu利用率 > 90%: #发送邮件提醒 连接邮箱服务器 发送邮件 关闭连接 if 硬盘使用空间 > 90%: #发送邮件提醒 连接邮箱服务器 发送邮件 关闭连接 if 内存占用 > 80%: #发送邮件提醒 连接邮箱服务器 发送邮件 关闭连接 |
上面的代码实现了功能,但即使是邻居老王也看出了端倪,老王亲切的摸了下你家儿子的脸蛋,说,你这个重复代码太多了,每次报警都要重写一段发邮件的代码,太low了,这样干存在2个问题:
- 代码重复过多,一个劲的copy and paste不符合高端程序员的气质
- 如果日后需要修改发邮件的这段代码,比如加入群发功能,那你就需要在所有用到这段代码的地方都修改一遍
你觉得老王说的对,你也不想写重复代码,但又不知道怎么搞,老王好像看出了你的心思,此时他抱起你儿子,笑着说,其实很简单,只需要把重复的代码提取出来,放在一个公共的地方,起个名字,以后谁想用这段代码,就通过这个名字调用就行了,如下
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
def 发送邮件(内容) #发送邮件提醒 连接邮箱服务器 发送邮件 关闭连接 while True: if cpu利用率 > 90%: 发送邮件('CPU报警') if 硬盘使用空间 > 90%: 发送邮件('硬盘报警') if 内存占用 > 80%: 发送邮件('内存报警') |
你看着老王写的代码,气势恢宏、磅礴大气,代码里透露着一股内敛的傲气,心想,老王这个人真是不一般,突然对他的背景更感兴趣了,问老王,这些花式玩法你都是怎么知道的? 老王亲了一口你儿子,捋了捋不存在的胡子,淡淡的讲,“老夫,年少时,师从京西沙河淫魔银角大王 ”, 你一听“银角大王”这几个字,不由的娇躯一震,心想,真nb,怪不得代码写的这么6, 这“银角大王”当年在江湖上可是数得着的响当当的名字,只可惜后期纵欲过度,卒于公元2016年, 真是可惜了,只留下其哥哥孤守当年兄弟俩一起打下来的江山。 此时你看着的老王离开的身影,感觉你儿子跟他越来越像了。。。
函数是什么?
函数一词来源于数学,但编程中的「函数」概念,与数学中的函数是有很大不同的,具体区别,我们后面会讲,编程中的函数在英文中也有很多不同的叫法。在BASIC中叫做subroutine(子过程或子程序),在Pascal中叫做procedure(过程)和function,在C中只有function,在Java里面叫做method。
定义: 函数是指将一组语句的集合通过一个名字(函数名)封装起来,要想执行这个函数,只需调用其函数名即可
特性:
- 减少重复代码
- 使程序变的可扩展
- 使程序变得易维护
语法定义
|
1
2
3
4
|
def sayhi():#函数名 print("Hello, I'm nobody!")sayhi() #调用函数 |
可以带参数
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
#下面这段代码a,b = 5,8c = a**bprint(c)#改成用函数写def calc(x,y): res = x**y return res #返回函数执行结果c = calc(a,b) #结果赋值给c变量print(c) |
2.函数参数与局部变量
形参变量只有在被调用时才分配内存单元,在调用结束时,即刻释放所分配的内存单元。因此,形参只在函数内部有效。函数调用结束返回主调用函数后则不能再使用该形参变量
实参可以是常量、变量、表达式、函数等,无论实参是何种类型的量,在进行函数调用时,它们都必须有确定的值,以便把这些值传送给形参。因此应预先用赋值,输入等办法使参数获得确定值
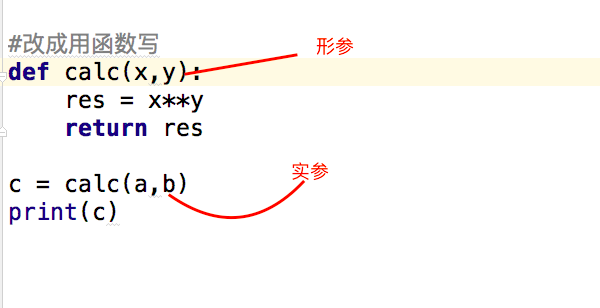
默认参数
看下面代码
|
1
2
3
4
5
6
7
8
9
10
|
def stu_register(name,age,country,course): print("----注册学生信息------") print("姓名:",name) print("age:",age) print("国籍:",country) print("课程:",course)stu_register("王山炮",22,"CN","python_devops")stu_register("张叫春",21,"CN","linux")stu_register("刘老根",25,"CN","linux") |
发现 country 这个参数 基本都 是"CN", 就像我们在网站上注册用户,像国籍这种信息,你不填写,默认就会是 中国, 这就是通过默认参数实现的,把country变成默认参数非常简单
|
1
|
def stu_register(name,age,course,country="CN"): |
这样,这个参数在调用时不指定,那默认就是CN,指定了的话,就用你指定的值。
另外,你可能注意到了,在把country变成默认参数后,我同时把它的位置移到了最后面,为什么呢?
关键参数
正常情况下,给函数传参数要按顺序,不想按顺序就可以用关键参数,只需指定参数名即可,但记住一个要求就是,关键参数必须放在位置参数之后。
|
1
|
stu_register(age=22,name='alex',course="python",) |
非固定参数
若你的函数在定义时不确定用户想传入多少个参数,就可以使用非固定参数
|
1
2
3
4
5
6
7
8
9
10
|
def stu_register(name,age,*args): # *args 会把多传入的参数变成一个元组形式 print(name,age,args)stu_register("Alex",22)#输出#Alex 22 () #后面这个()就是args,只是因为没传值,所以为空stu_register("Jack",32,"CN","Python")#输出# Jack 32 ('CN', 'Python') |
还可以有一个**kwargs
|
1
2
3
4
5
6
7
8
9
10
|
def stu_register(name,age,*args,**kwargs): # *kwargs 会把多传入的参数变成一个dict形式 print(name,age,args,kwargs)stu_register("Alex",22)#输出#Alex 22 () {}#后面这个{}就是kwargs,只是因为没传值,所以为空stu_register("Jack",32,"CN","Python",sex="Male",province="ShanDong")#输出# Jack 32 ('CN', 'Python') {'province': 'ShanDong', 'sex': 'Male'} |
局部变量
|
1
2
3
4
5
6
7
8
9
10
11
|
name = "Alex Li"def change_name(name): print("before change:",name) name = "金角大王,一个有Tesla的男人" print("after change", name)change_name(name)print("在外面看看name改了么?",name) |
输出
|
1
2
3
|
before change: Alex Liafter change 金角大王,一个有Tesla的男人在外面看看name改了么? Alex Li |
全局与局部变量
3.返回值
要想获取函数的执行结果,就可以用return语句把结果返回
注意:
- 函数在执行过程中只要遇到return语句,就会停止执行并返回结果,so 也可以理解为 return 语句代表着函数的结束
- 如果未在函数中指定return,那这个函数的返回值为None
强行插入知识点: 嵌套函数
看上面的标题的意思是,函数还能套函数?of course
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
name = "Alex"def change_name(): name = "Alex2" def change_name2(): name = "Alex3" print("第3层打印",name) change_name2() #调用内层函数 print("第2层打印",name)change_name()print("最外层打印",name) |
此时,在最外层调用change_name2()会出现什么效果?
没错, 出错了, 为什么呢?
嵌套函数的用法会了,但它有什么用呢?下节课揭晓。。。
4. 递归
在函数内部,可以调用其他函数。如果一个函数在内部调用自身本身,这个函数就是递归函数。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
def calc(n): print(n) if int(n/2) ==0: return n return calc(int(n/2))calc(10)输出:10521 |
递归特性:
1. 必须有一个明确的结束条件
2. 每次进入更深一层递归时,问题规模相比上次递归都应有所减少
3. 递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出)
堆栈扫盲http://www.cnblogs.com/lln7777/archive/2012/03/14/2396164.html
递归函数实际应用案例,二分查找
5. 匿名函数
匿名函数就是不需要显式的指定函数
|
1
2
3
4
5
6
7
8
|
#这段代码def calc(n): return n**nprint(calc(10))#换成匿名函数calc = lambda n:n**nprint(calc(10)) |
你也许会说,用上这个东西没感觉有毛方便呀, 。。。。呵呵,如果是这么用,确实没毛线改进,不过匿名函数主要是和其它函数搭配使用的呢,如下
|
1
2
3
|
res = map(lambda x:x**2,[1,5,7,4,8])for i in res: print(i) |
输出
1
25
49
16
64
6.函数式编程介绍
函数是Python内建支持的一种封装,我们通过把大段代码拆成函数,通过一层一层的函数调用,就可以把复杂任务分解成简单的任务,这种分解可以称之为面向过程的程序设计。函数就是面向过程的程序设计的基本单元。
函数式编程中的函数这个术语不是指计算机中的函数(实际上是Subroutine),而是指数学中的函数,即自变量的映射。也就是说一个函数的值仅决定于函数参数的值,不依赖其他状态。比如sqrt(x)函数计算x的平方根,只要x不变,不论什么时候调用,调用几次,值都是不变的。
Python对函数式编程提供部分支持。由于Python允许使用变量,因此,Python不是纯函数式编程语言。
一、定义
简单说,"函数式编程"是一种"编程范式"(programming paradigm),也就是如何编写程序的方法论。
主要思想是把运算过程尽量写成一系列嵌套的函数调用。举例来说,现在有这样一个数学表达式:
(1 + 2) * 3 - 4
传统的过程式编程,可能这样写:
var a = 1 + 2;
var b = a * 3;
var c = b - 4;
函数式编程要求使用函数,我们可以把运算过程定义为不同的函数,然后写成下面这样:
var result = subtract(multiply(add(1,2), 3), 4);
这段代码再演进以下,可以变成这样
add(1,2).multiply(3).subtract(4)
这基本就是自然语言的表达了。再看下面的代码,大家应该一眼就能明白它的意思吧:
merge([1,2],[3,4]).sort().search("2")
因此,函数式编程的代码更容易理解。
要想学好函数式编程,不要玩py,玩Erlang,Haskell, 好了,我只会这么多了。。。
7.高阶函数
变量可以指向函数,函数的参数能接收变量,那么一个函数就可以接收另一个函数作为参数,这种函数就称之为高阶函数。
|
1
2
3
4
5
6
|
def add(x,y,f): return f(x) + f(y)res = add(3,-6,abs)print(res) |
8. 内置参数

内置参数详解 https://docs.python.org/3/library/functions.html?highlight=built#ascii
 几个内置方法用法提醒
几个内置方法用法提醒
本节作业
有以下员工信息表
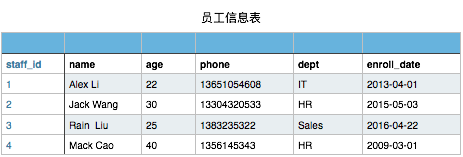
当然此表你在文件存储时可以这样表示
|
1
|
1,Alex Li,22,13651054608,IT,2013-04-01 |
现需要对这个员工信息文件,实现增删改查操作
- 可进行模糊查询,语法至少支持下面3种:
- select name,age from staff_table where age > 22
- select * from staff_table where dept = "IT"
- select * from staff_table where enroll_date like "2013"
- 查到的信息,打印后,最后面还要显示查到的条数
- 可创建新员工纪录,以phone做唯一键,staff_id需自增
- 可删除指定员工信息纪录,输入员工id,即可删除
- 可修改员工信息,语法如下:
- UPDATE staff_table SET dept="Market" WHERE where dept = "IT"