Recycler
讲回收器之前,先说下对象池,即之前提过的ObjectPool。
public abstract class ObjectPool<T> { //通过对象创建接口和处理器关联,以便于创建的的对象内部可以调用处理器的方法,用来回收对象。
ObjectPool() { }
/**
* Get a {@link Object} from the {@link ObjectPool}. The returned {@link Object} may be created via
* {@link ObjectCreator#newObject(Handle)} if no pooled {@link Object} is ready to be reused.
*/
public abstract T get();//抽象方法,获取T类型的对象。
/**
* Handle for an pooled {@link Object} that will be used to notify the {@link ObjectPool} once it can
* reuse the pooled {@link Object} again.
* @param <T>
*/
public interface Handle<T> {//Handle回收处理器接口
/**
* Recycle the {@link Object} if possible and so make it ready to be reused.
*/
void recycle(T self);//回收方法,就是将要回收的对象传进去
}
/**
* Creates a new Object which references the given {@link Handle} and calls {@link Handle#recycle(Object)} once
* it can be re-used.
*
* @param <T> the type of the pooled object
*/
public interface ObjectCreator<T> {//对象创建接口,有个传入处理器的创建方法。
/**
* Creates an returns a new {@link Object} that can be used and later recycled via
* {@link Handle#recycle(Object)}.
*/
T newObject(Handle<T> handle);////创建一个新的T类型的对象,传入处理器作为参数
}
/**
* Creates a new {@link ObjectPool} which will use the given {@link ObjectCreator} to create the {@link Object}
* that should be pooled.
*/
public static <T> ObjectPool<T> newPool(final ObjectCreator<T> creator) { //提供给我们使用的方法,只需要传入一个对象创建器即可。
return new RecyclerObjectPool<T>(ObjectUtil.checkNotNull(creator, "creator"));
}
private static final class RecyclerObjectPool<T> extends ObjectPool<T> {//回收器对象池,实现了get方法,内部就是通过一个回收器来获得。同时构造方法传入一个对象创建实例,
private final Recycler<T> recycler;
RecyclerObjectPool(final ObjectCreator<T> creator) {
recycler = new Recycler<T>() {
@Override
protected T newObject(Handle<T> handle) {
return creator.newObject(handle);
}
};
}
@Override
public T get() {
return recycler.get();
}
}
}
Recycler 在 Netty 里面使用也是非常频繁的,我们直接看下 Netty 源码中 newObject 相关的引用,如下图所示。
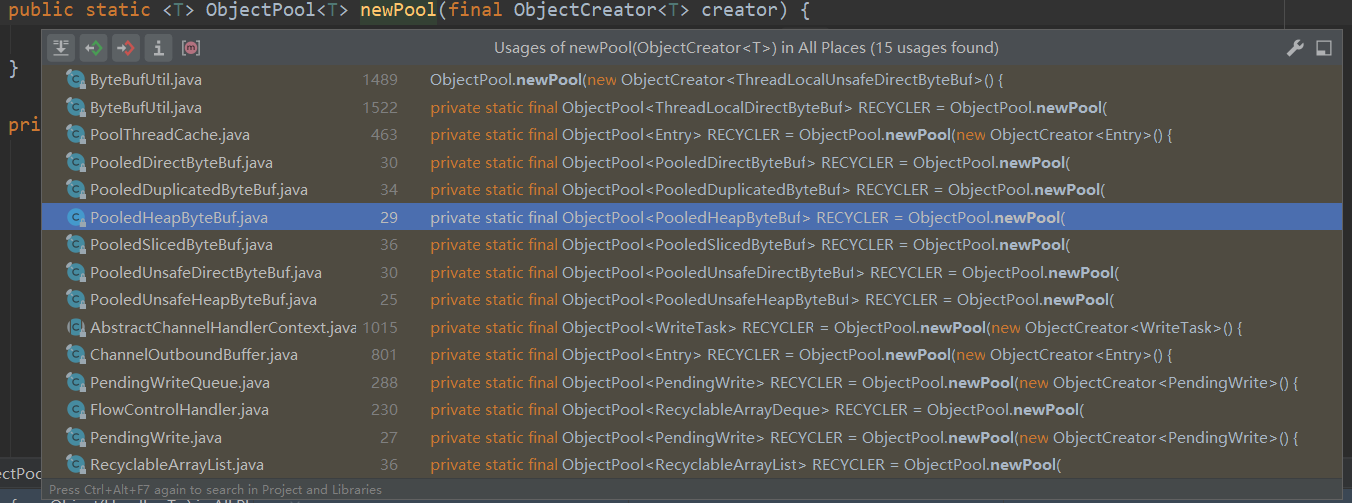
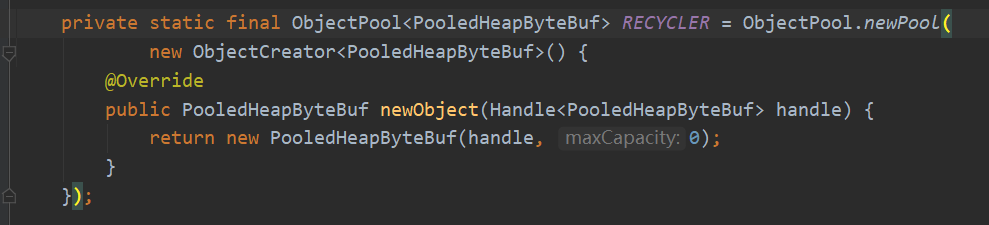
其中比较常用的有 PooledHeapByteBuf 和 PooledDirectByteBuf,分别对应的堆内存和堆外内存的池化实现。
照个例子
使用的时候只要:
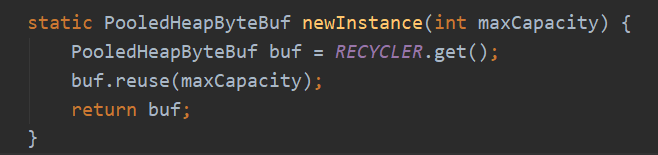
回收的时候有个处理器Handle,这个交给回收器去创建了,不用管:

对象池与内存池的都是为了提高 Netty 的并发处理能力,我们知道 Java 中频繁地创建和销毁对象的开销是很大的,所以很多人会将一些通用对象缓存起来,当需要某个对象时,优先从对象池中获取对象实例。通过重用对象,不仅避免频繁地创建和销毁所带来的性能损耗,而且对 JVM GC 是友好的,这就是对象池的作用。
Recycler
一些配置属性
private static final AtomicInteger ID_GENERATOR = new AtomicInteger(Integer.MIN_VALUE);//id生成器
private static final int OWN_THREAD_ID = ID_GENERATOR.getAndIncrement();//获取所属线程的id
private static final int DEFAULT_INITIAL_MAX_CAPACITY_PER_THREAD = 4 * 1024; // Use 4k instances as default.
private static final int DEFAULT_MAX_CAPACITY_PER_THREAD;//每个线程本地变量Stack最大容量,默认4096
private static final int INITIAL_CAPACITY;//Stack初始化容量,默认256
private static final int MAX_SHARED_CAPACITY_FACTOR;//最大共享容量因子,影响WeakOrderQueue的容量,默认2
private static final int MAX_DELAYED_QUEUES_PER_THREAD;//每个线程本地变量WeakHashMap的最大键值对个数,默认CPU核心数x2
private static final int LINK_CAPACITY;//链接中的数组容量,默认16
private static final int RATIO;//回收间隔,默认8
先来个demo
public class UserCache { private static final Recycler<User> userRecycler = new Recycler<User>() { @Override protected User newObject(Handle<User> handle) { return new User(handle); } }; static final class User { private String name; private Recycler.Handle<User> handle; public void setName(String name) { this.name = name; } public String getName() { return name; } public User(Recycler.Handle<User> handle) { this.handle = handle; } public void recycle() { handle.recycle(this); } } public static void main(String[] args) { User user1 = userRecycler.get(); // 1、从对象池获取 User 对象 user1.setName("hello"); // 2、设置 User 对象的属性 user1.recycle(); // 3、回收对象到对象池 User user2 = userRecycler.get(); // 4、从对象池获取对象
new Thread(() -> user2.recycle()).start();
System.out.println(user2.getName());
System.out.println(user1 == user2); } }
输出结果
hello true
代码示例中定义了对象池实例 userRecycler,其中实现了 newObject() 方法,如果对象池没有可用的对象,会调用该方法新建对象。此外需要创建 Recycler.Handle 对象与 User 对象进行绑定,这样我们就可以通过 userRecycler.get() 从对象池中获取 User 对象,如果对象不再使用,通过调用 User 类实现的 recycle() 方法即可完成回收对象到对象池。
每个线程独立存取数据
多线程中每个线程都可能会有创建对象,释放对象,当他们创建的时候,首先会从当前线程本地变量中获取,这样做避免了多线程之间的竞争问题。每个线程都拥有一个特殊的栈Stack,一般情况下就是从Stack中获取,回收也是放这个里面回收,Stack内部是一个数组,用索引记录,存取非常快。如果栈中没有对象,新建一个全新对象即可。为了安全起见,我们需要设定栈的大小以及阈值。回收对象时需要判断已回收对象数量是否超过阈值,如果超出则丢弃,避免池化对象过多造成内存浪费。
private final FastThreadLocal<Stack<T>> threadLocal = new FastThreadLocal<Stack<T>>() { @Override protected Stack<T> initialValue() { return new Stack<T>(Recycler.this, Thread.currentThread(), maxCapacityPerThread, maxSharedCapacityFactor, interval, maxDelayedQueuesPerThread, delayedQueueInterval); } @Override protected void onRemoval(Stack<T> value) { // Let us remove the WeakOrderQueue from the WeakHashMap directly if its safe to remove some overhead if (value.threadRef.get() == Thread.currentThread()) { if (DELAYED_RECYCLED.isSet()) { DELAYED_RECYCLED.get().remove(value); } } } };
以上设计有个问题就是异线程回收(对象 A 本是线程 Thread_1 创建以及回收,但是在 Thread_2 调用回收方法,这种情况就属于异线程回收)。
针对以上问题,我们使用map来处理。
private static final FastThreadLocal<Map<Stack<?>, WeakOrderQueue>> DELAYED_RECYCLED = new FastThreadLocal<Map<Stack<?>, WeakOrderQueue>>() { @Override protected Map<Stack<?>, WeakOrderQueue> initialValue() { return new WeakHashMap<Stack<?>, WeakOrderQueue>();//弱键回收,键如果只有弱引用,可以被GC回收,然后将整个键值对回收 } };
FastThreadLocal 使用Map<Stack<?>, WeakOrderQueue> ,具体类型是WeakHashMap<Stack<?>,WeakOrderQueue>,他的键是弱引用,而且他是以键的引用地址来判断是不是同一个键。他将Stack和WeakOrderQueue对应起来了。
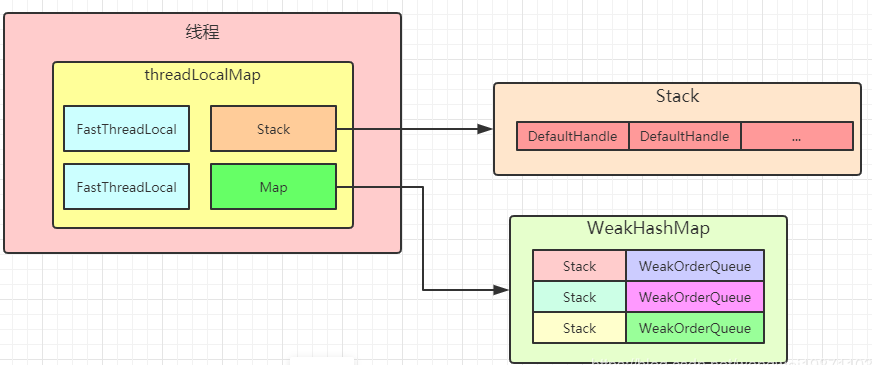
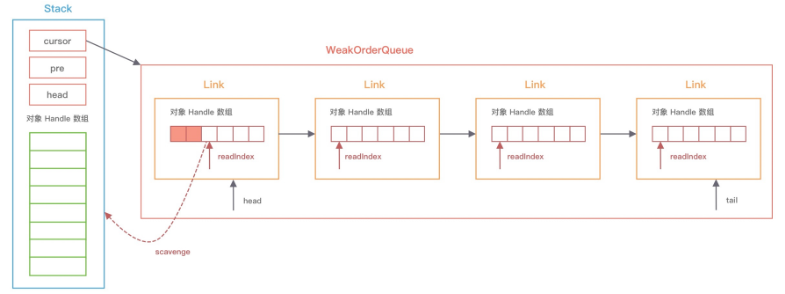
WeakOrderQueue 是一个队列,这个队列里面也可以放回收的对象,区分当前线程是不是Stack的拥有线程,如果是,就直接放回到Stack中,如果不是,就放入对应的WeakOrderQueue中,前面说了Stack和WeakOrderQueue有对应关系。而且多个线程中都可能有同一个Stack的不同WeakOrderQueue。他们之间是用单链表连起来的。
WeakOrderQueue内部使用Link类型的链表连接起来的,Link内部也是数组。
Stack构造方法
Stack(Recycler<T> parent, Thread thread, int maxCapacity, int maxSharedCapacityFactor, int interval, int maxDelayedQueues, int delayedQueueInterval) { this.parent = parent;//Stack是被哪个「Recycler」创建的 threadRef = new WeakReference<Thread>(thread);//所属线程的弱引用 this.maxCapacity = maxCapacity;//最大容量,默认4096 availableSharedCapacity = new AtomicInteger(max(maxCapacity / maxSharedCapacityFactor, LINK_CAPACITY));//共享容量,也就是其他线程中的WeakOrderQueue中的最大容量的总和 2048 elements = new DefaultHandle[min(INITIAL_CAPACITY, maxCapacity)];//存放对象的数组,默认256大小 this.interval = interval;//回收间隔 this.delayedQueueInterval = delayedQueueInterval;// 间隔计数器,第一个会被回收 handleRecycleCount = interval; // Start at interval so the first one will be recycled. this.maxDelayedQueues = maxDelayedQueues;//关联的WeakOrderQueue最大个数,默认16 }
WeakReference<Thread> threadRef ,我们将线程存储在一个 WeakReference 中,否则我们可能是唯一一个在线程死亡后仍然持有对线程本身的强引用的引用,因为 DefaultHandle 将持有对栈的引用。最大的问题是,如果我们不使用 WeakReference,那么如果用户在某个地方存储了对 DefaultHandle 的引用,并且永远不会清除这个引用(或者不能及时清除它) ,那么 Thread 可能根本不能被收集。
DefaultHandle
这个就是处理器,实现了Handle接口,主要是处理回收的,主要的方法就是recycle,主要的代码贴出来了,其实就是入栈:
private static final class DefaultHandle<T> implements Handle<T> { int lastRecycledId;// 上次回收此Handle的RecycleId int recycleId;// 创建此Handle的RecycleId。和 lastRecycledId 配合使用进行重复回收检测 boolean hasBeenRecycled;// 该对象是否被回收过 Stack<?> stack;// 创建「DefaultHandle」的Stack对象 Object value;// 待回收对象 DefaultHandle(Stack<?> stack) { this.stack = stack; } @Override public void recycle(Object object) {//回收此「Handle」所持有的对象「value」 if (object != value) { throw new IllegalArgumentException("object does not belong to handle"); } Stack<?> stack = this.stack; if (lastRecycledId != recycleId || stack == null) { throw new IllegalStateException("recycled already"); } stack.push(this); } }
DefaultHandler 包装待回收对象,同时也添加了部分信息。比如用于重复回收检测的 recycledId 和 lastRecycleId。lastRecycleId 用来存储最后一次回收对象的线程ID,recycledId 用来存 Recycler ID,这个值是通过 Recycler 全局变量 ID_GENERATOR 创建,每当回收一个 DefaultHandle 对象(该对象内部包装我们真正的回收对象),都会从 Recycler 对象中获得唯一 ID 值,一开始 recycledId 和 lastRecycledId 相等。后续通过判断两个值是否相等从而得出是否存在重复回收对象的现象并抛出异常。
回收操作
public void recycle(Object object) { if (object != value) { throw new IllegalArgumentException("object does not belong to handle"); } Stack<?> stack = this.stack; if (lastRecycledId != recycleId || stack == null) { throw new IllegalStateException("recycled already"); } stack.push(this); }
push
当前线程是否是Stack所属线程,如果是,就放入elements数组中。否则就放入另一个线程的本地变量WeakHashMap中,以创建<Stack<?>, WeakOrderQueue>键值对,主要还是创建WeakOrderQueue,然后将WeakOrderQueue加入Stack的单链表中,这样使得多个其他线程的WeakOrderQueue和所属线程的Stack有关联。WeakOrderQueue里面创建Link链接对象,将回收对象放入Link对象的elements数组中。而且数组的操作全部使用额外的索引,只需要移动索引进行操作,不需要因为增加删除元素而移动数组元素,所以性能非常高,而且无论Stack还是WeakOrderQueue内部还有间隔回收的限制,不是说放进来就要的,有一定个数间隔的,默认间隔是8,也就是除了第一次直接回收,后面每来9个,回收1个,比如来了10个,只有第1个和第10个被回收,中间8个全部不管,等着GC去回收了。
void push(DefaultHandle<?> item) { Thread currentThread = Thread.currentThread(); if (threadRef.get() == currentThread) {//属于栈的线程,直接入栈 // The current Thread is the thread that belongs to the Stack, we can try to push the object now. pushNow(item); } else { // The current Thread is not the one that belongs to the Stack // (or the Thread that belonged to the Stack was collected already), we need to signal that the push // happens later. pushLater(item, currentThread);//不属于栈的线程或者属于栈的但是被回收得到线程,需要后面入栈,先放进WeakOrderQueue } }
pushNow
当前线程是Stack的所属线程
首先判断是否回收过,然后记录回收信息,判断回收的数量有没超过限制,或者是不是丢弃,根据回收间隔。然后看elements数组是否需要扩容,每次扩容到两倍,但是不超过最大容量默认4096。最后把对象放入指定索引的位置。
private void pushNow(DefaultHandle<?> item) { if ((item.recycleId | item.lastRecycledId) != 0) {//尝试过回收 throw new IllegalStateException("recycled already"); } item.recycleId = item.lastRecycledId = OWN_THREAD_ID;//记录定义的线程ID int size = this.size;//已有对象数量 if (size >= maxCapacity || dropHandle(item)) { // Hit the maximum capacity or should drop - drop the possibly youngest object. return; } if (size == elements.length) {//要扩容了 每次x2 直到maxCapacity elements = Arrays.copyOf(elements, min(size << 1, maxCapacity)); } elements[size] = item; this.size = size + 1; }
dropHandle
间隔回收,两次回收之间隔8个对象。可通过 io.netty.recycler.ratio 配置
boolean dropHandle(DefaultHandle<?> handle) { if (!handle.hasBeenRecycled) {//没被回收过 if (handleRecycleCount < interval) {//回收次数小于间隔数,丢弃 handleRecycleCount++;//回收次数+1 // Drop the object. return true; } handleRecycleCount = 0;//重新置0 handle.hasBeenRecycled = true;//被回收了 } return false; }
pushLater
当前线程不是Stack的所属线程
private void pushLater(DefaultHandle<?> item, Thread thread) { if (maxDelayedQueues == 0) { // We don't support recycling across threads and should just drop the item on the floor. return; } // we don't want to have a ref to the queue as the value in our weak map // so we null it out; to ensure there are no races with restoring it later // we impose a memory ordering here (no-op on x86) Map<Stack<?>, WeakOrderQueue> delayedRecycled = DELAYED_RECYCLED.get();//每个线程都会有自己的map WeakOrderQueue queue = delayedRecycled.get(this);//获取对应的WeakOrderQueue if (queue == null) {//不存在尝试创建一个放入map if (delayedRecycled.size() >= maxDelayedQueues) {//数量大于阈值 放一个假WeakOrderQueue,WeakOrderQueue.DUMMY 表示当前线程无法再帮助该 Stack 回收对象 // Add a dummy queue so we know we should drop the object delayedRecycled.put(this, WeakOrderQueue.DUMMY); return; } // Check if we already reached the maximum number of delayed queues and if we can allocate at all. if ((queue = newWeakOrderQueue(thread)) == null) {//创建一个队列,如果要分配的容量(16)不够的话就丢弃对象 // drop object return; } delayedRecycled.put(this, queue);//放入map里 } else if (queue == WeakOrderQueue.DUMMY) {//如果是假的,就丢弃 // drop object return; } queue.add(item);//放入WeakOrderQueue }
首先我们会获取线程本地变量WeakHashMap<Stack<?>, WeakOrderQueue>,然后根据Stack获取WeakOrderQueue 。
- 如果获取不到,说明还没有这个Stack关联的WeakOrderQueue被创建。尝试创建,但是如果WeakHashMap键值对数量超过限制了,就放一个假的WeakOrderQueue,其实就是一个空的队列,DUMMY。否则的话就尝试创建一个,如果还有分配的容量的话,就创建,并和Stack一起放入WeakHashMap中,不行的话就丢弃对象。
- 如果获取的是DUMMY 的话,说明WeakHashMap放满了,就丢弃。
- 如果获取到了且不是DUMMY就尝试放队列里。
newWeakOrderQueue创建队列
private WeakOrderQueue newWeakOrderQueue(Thread thread) { return WeakOrderQueue.newQueue(this, thread); } static WeakOrderQueue newQueue(Stack<?> stack, Thread thread) { // We allocated a Link so reserve the space if (!Head.reserveSpaceForLink(stack.availableSharedCapacity)) { return null; } final WeakOrderQueue queue = new WeakOrderQueue(stack, thread); // Done outside of the constructor to ensure WeakOrderQueue.this does not escape the constructor and so // may be accessed while its still constructed. stack.setHead(queue); return queue; }
stack.setHead(queue) 设置头结点
因为需要跟Stack有关联,所以会跟Stack的head结点形成一个单链表,头插法,而且这里用方法同步,主要是多线程可能同时回收,所以需要同步。
synchronized void setHead(WeakOrderQueue queue) { queue.setNext(head); head = queue; }
Head
首先先介绍下Head类,他管理着里面所有的链接Link的创建和回收。内部还有一个Link的连接,其实是单链表的表头,所有的Link都会被串起来,还有一个容量availableSharedCapacity,后续的分配和回收都会用到。
private static final class Head { private final AtomicInteger availableSharedCapacity;//可用容量 Link link; Head(AtomicInteger availableSharedCapacity) { this.availableSharedCapacity = availableSharedCapacity; } /** * Reclaim all used space and also unlink the nodes to prevent GC nepotism. */ void reclaimAllSpaceAndUnlink() { Link head = link; link = null; int reclaimSpace = 0; while (head != null) { reclaimSpace += LINK_CAPACITY; Link next = head.next; // Unlink to help GC and guard against GC nepotism. head.next = null; head = next; } if (reclaimSpace > 0) { reclaimSpace(reclaimSpace); } } private void reclaimSpace(int space) { availableSharedCapacity.addAndGet(space); } void relink(Link link) { reclaimSpace(LINK_CAPACITY); this.link = link; } /** * Creates a new {@link} and returns it if we can reserve enough space for it, otherwise it * returns {@code null}. */ Link newLink() { return reserveSpaceForLink(availableSharedCapacity) ? new Link() : null; } static boolean reserveSpaceForLink(AtomicInteger availableSharedCapacity) { for (;;) { int available = availableSharedCapacity.get(); if (available < LINK_CAPACITY) {//可分配容量小于16,分配失败 return false; } if (availableSharedCapacity.compareAndSet(available, available - LINK_CAPACITY)) { return true; } } } }
Link具体存对象
本身就是原子对象,可以计数,这个在后面放入对象的时候会用到。这个里面其实就是一个数组,用来存对象,默认容量是16,还有一个next指向下一个,至于readIndex就是获取对象的时候用,这个跟netty自定义的ByteBuf的读索引类似,表示下一个可获取对象的索引。
static final class Link extends AtomicInteger { final DefaultHandle<?>[] elements = new DefaultHandle[LINK_CAPACITY]; int readIndex;//读索引,表示下一个可获取对象的索引 Link next;//下一个 }

Head.reserveSpaceForLink为Link申请空间
传进来的参数是stack.availableSharedCapacity也就是2048,说明可以申请的容量是跟这个参数相关的,最多2048个。也就是说**每个Stack在其他线程中的回收对象最多是2048个。**每次分配16个,如果容量小于16个了,就不分配了,因此可能导致WeakOrderQueue创建失败,丢弃对象。
WeakOrderQueue构造方法
创建一个链接Link,然后给创建一个Head,并传入availableSharedCapacity引用,根据这个availableSharedCapacity来进行后续Link的分配和回收的。然后还有个队尾的引用,同时也存在回收间隔,跟Stack一样,默认是8。WorkOrderQueue 内部链表是由 Head和 tail节点组成的。 队内数据并非立即对其他线程可见,采用最终一致性思想。不需要进行保证立即可见,只需要保证最终可见就好了。
private WeakOrderQueue(Stack<?> stack, Thread thread) { super(thread); tail = new Link();//创建链接,分配LINK_CAPACITY个DefaultHandle类型的数组 // Its important that we not store the Stack itself in the WeakOrderQueue as the Stack also is used in // the WeakHashMap as key. So just store the enclosed AtomicInteger which should allow to have the // Stack itself GCed. head = new Head(stack.availableSharedCapacity);//Head节点管理「Link」对象的创建。内部next指向下一个「Link」节点,构成链表结构 head.link = tail;//数据存储节点 interval = stack.delayedQueueInterval; handleRecycleCount = interval; // Start at interval so the first one will be recycled. 已丢弃回收对象数量 }
WeakOrderQueue#add
这个也是间隔回收的,从队尾的Link 开始,看是否满了,如果满了就重新创建一个Link加入链表,然后在elements对应索引位置放入对象,Link本身就是AtomicInteger,可以进行索引的改变。
WeakOrderQueue 是本地线程缓存的私有变量,线程对自己 WeakOrderQueue 写入并不需要加锁,Link 节点的写索引(writeIndex)、读索引(readIndex)也不存在并发问题,但存在数据可见性的问题,这个可见性是指对回收线程可见,因为回收线程需要通过 writeIndex 确定终止序号,源码还有一个关于 volatile 延迟更新写索引的用法。相当于回收线程只管读,至于从哪里读是由异线程告诉你(通过writeIndex),如果它延迟更新,相当于延迟告诉你,数据也并没有冲突或丢失,你可以从其他线程的 WeakOrderQueue 链表中获取,不必吊死在这一棵树上,等你下次来的时候就可以看到了,这样就提升了写入时的性能。
void add(DefaultHandle<?> handle) { handle.lastRecycledId = id;//记录上次回收的线程id // While we also enforce the recycling ratio when we transfer objects from the WeakOrderQueue to the Stack // we better should enforce it as well early. Missing to do so may let the WeakOrderQueue grow very fast // without control if (handleRecycleCount < interval) {//回收次数小于间隔,就丢弃对象,为了不让队列增长过快 handleRecycleCount++; // Drop the item to prevent recycling to aggressive. return; } handleRecycleCount = 0; Link tail = this.tail; int writeIndex; if ((writeIndex = tail.get()) == LINK_CAPACITY) {// 写指针到达Link节点的末尾,需要申请一个新的Link节点 Link link = head.newLink();//创建新的链接,如果创建不成功,就返回null,丢弃对象 可能会超出availableSharedCapacity大小导致创建失败 if (link == null) { // Drop it. return; } // We allocate a Link so reserve the space this.tail = tail = tail.next = link;//加入链表 writeIndex = tail.get(); } tail.elements[writeIndex] = handle;//放入对象 handle.stack = null;//放进queue里就没有栈了,DefaultHandle的handle置为空,因为有可能这个Stack会被回收掉,如果这里存在强引用,会导致Stack对象不能回收,后面待Stack回收时会重新设置 // we lazy set to ensure that setting stack to null appears before we unnull it in the owning thread; // this also means we guarantee visibility of an element in the queue if we see the index updated tail.lazySet(writeIndex + 1);//不需要立即可见,这里都是单线程操作 }
handle.stack = null;
对象被添加到 Link 之后,handle 的 stack 属性被赋值为 null,而在取出对象的时候,handle 的 stack 属性又再次被赋值回来,为什么这么做呢,岂不是很麻烦?如果 Stack 不再使用,期望被 GC 回收,发现 handle 中还持有 Stack 的引用,那么就无法被 GC 回收,从而造成内存泄漏。
handle 的 stack 属性被赋值为 null
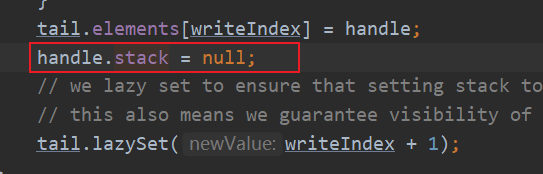
handle 的 stack 属性又再次被赋值回来

tail.lazySet(writeIndex + 1);
延迟更新索引(索引被更新,队列元素才可见), 这是volatile高级用法,由于存在多个生产者一个消费者,所以不需要在更新WeakOrderQueue 立即可见,它可以从其他WeakOrderQueue队列中获取回收对象。使用lazySet保持最终可见性,但会存在延迟, 这有利于提升写入时的性能(本质是减少内存屏障的开销)。
head.newLink创建链接
其实就是前面讲过的申请空间,创建Link。如果成功就创建一个链接返回,否则就返回null。
Link newLink() { return reserveSpaceForLink(availableSharedCapacity) ? new Link() : null; }
RECYCLER.get()
public final T get() { if (maxCapacityPerThread == 0) {//如果不启用,就给一个空实现处理器 return newObject((Handle<T>) NOOP_HANDLE); } Stack<T> stack = threadLocal.get();//获取栈,不存在就初始化一个 DefaultHandle<T> handle = stack.pop();//弹出一个处理器 if (handle == null) {//处理器不存在就创建一个,再创建一个值 handle = stack.newHandle(); handle.value = newObject(handle); } return (T) handle.value; }
通过线程本地变量获取Stack,如果没获取到,就会初始化一个,也就是:
protected Stack<T> initialValue() { return new Stack<T>(Recycler.this, Thread.currentThread(), maxCapacityPerThread, maxSharedCapacityFactor, interval, maxDelayedQueuesPerThread, delayedQueueInterval); }
stack.pop()
获取Stack后,就开始调用pop来获取。
DefaultHandle<T> pop() { int size = this.size; if (size == 0) {//没有了就清理尝试从队列中转过来 if (!scavenge()) {//清理队列失败 return null; } size = this.size;//设置个数 if (size <= 0) { // double check, avoid races return null; } } size --; DefaultHandle ret = elements[size]; elements[size] = null; // As we already set the element[size] to null we also need to store the updated size before we do // any validation. Otherwise we may see a null value when later try to pop again without a new element // added before. this.size = size;//更新数量 if (ret.lastRecycledId != ret.recycleId) { throw new IllegalStateException("recycled multiple times"); } ret.recycleId = 0; ret.lastRecycledId = 0; return ret; }
这里可以分两中情况,一种是Stack中没有对象的情况,另一种是有对象的情况。
Stack有对象的情况
有对象,就直接将size减1,size其实就是一个索引,又能表示数量,默认是0,放入一个加1,取出一个减1,这样就不需要去移动数组,效率高,然后按照size索引取出elements中的DefaultHandle对象,设置对象的回收属性,返回 。这个是比较简单的情况。
Stack没有对象的情况
scavenge清理
进行WeakOrderQueue的清理,即将WeakOrderQueue里的对象转移到Stack中。
private boolean scavenge() { // continue an existing scavenge, if any if (scavengeSome()) { return true; } // reset our scavenge cursor // 如果迁移失败,就会重置 cursor 指针到 head 节点 prev = null; cursor = head; return false; }
scavengeSome
- 如果以前没有清理过或者没有要清理的了,cursor 为null,然后尝试开始从head清理。如果head也为null,说明没有WeakOrderQueue,直接返回false清理失败,否则cursor就是head,即可以从head开始清理。
- 如果以前有清理过,获取到prev,即上一个WeakOrderQueue,便于后面删除结点保持链表不断链。
然后开始尝试将cursor中的对象转移到Stack中。
- 如果转移成功直接返回true。
- 如果发现cursor的引用线程不存在了,如果cursor还有有对象的话,全部转移到Stack中,并设置转移成功标志true。如果prev存在的话,就把cursor空间释放,并且从链表中删除。
- 如果cursor的引用线程还存在,就把prev指向cursor。
最后cursor指向下一个WeakOrderQueue。
如果发现cursor不为空,且没有转移成功过,就再进行转移,直到cursor为空,或者转移成功为止。
最后设置prev和cursor。
private boolean scavengeSome() { WeakOrderQueue prev; WeakOrderQueue cursor = this.cursor;// cursor 指针指向当前 WeakorderQueueu 链表的读取位置 if (cursor == null) {// 如果 cursor 指针为 null, 则是第一次从 WeakorderQueueu 链表中获取对象 prev = null; cursor = head; if (cursor == null) { return false; } } else { prev = this.prev; } boolean success = false; do { // 不断循环从 WeakOrderQueue 链表中找到一个可用的对象实例 if (cursor.transfer(this)) {//每次转移一个链接的量,由于有间隔,一般就只有2个转移 success = true; break; } WeakOrderQueue next = cursor.getNext();//只有上一个转移完了,才会获取下一个队列 if (cursor.get() == null) {//关联线程被回收为null了 // If the thread associated with the queue is gone, unlink it, after // performing a volatile read to confirm there is no data left to collect. // We never unlink the first queue, as we don't want to synchronize on updating the head. if (cursor.hasFinalData()) {//还有对象 for (;;) { if (cursor.transfer(this)) {//把队列中的所有链接全部转移完为止 success = true; } else { break; } } } if (prev != null) {//如果cursor的前一个队列prev存在 // Ensure we reclaim all space before dropping the WeakOrderQueue to be GC'ed. cursor.reclaimAllSpaceAndUnlink();//释放cursor结点空间,以便进行GC之前收回所有空间。 prev.setNext(next);//从单链表中删除cursor结点,prev的next指向cursor的下一个,第一个head是不释放的 } } else { prev = cursor;//prev保存前一个,用来链接删除结点的时候链接下一个结点,保持不断链 } cursor = next;//游标指向下一个队列 } while (cursor != null && !success);//下一个队列不为空,且没有成功转移过 this.prev = prev; this.cursor = cursor; return success; }
WeakOrderQueue的transfer转移
简单的来说就是从WeakOrderQueue的head中的链接link开始遍历,把link中的element数组的所有对象转移给Stack的element数组。其中readIndex表示下一个能转移的数组索引,如果readIndex=LINK_CAPACITY即表示转移完了。
- 如果发现link已经转移完,又是最后一个link,就直接返回false,否则就把他的空间释放了,head的link指向下一个。
- 之后还会判断一次,新获取的下一个Link是否有可以转移的对象,如果没有就直接返回false了。
- 如果还能转移,就计算转换后的Stack中预期有多少对象,如果elements不够放的话就进行扩容。如果扩容了还不行的话,说明满了,就返回false了。
- 如果可以放的话,就开始转移,从Link的elements转移到Stack的elements,也不是每一个都会转过去,这里也有个回收间隔,也是间隔8个,也即所有16个对象只能转2个过去,其实就是回收的比较少,大部分都是丢弃的。如果这个Link所有对象都转移完了,且他的下一个不为null,就将head的link指向下一个。
- 最后判断是否有对象转移,如果有就给Stack设置新size并返回true,否则就false,因为转移有间隔,不一定能有对象转移过去的。
boolean transfer(Stack<?> dst) { Link head = this.head.link;// 获取链表的头结点 if (head == null) {// 头结点为空,表示没有数据,直接返回 return false; } if (head.readIndex == LINK_CAPACITY) {// LINK_CAPACITY表示一个Link节点的容量大小,默认值: 16 判断读指针「readIndex」是否到达边界了,如果到达边界且指向下一个节点为NULL if (head.next == null) { return false; } head = head.next; this.head.relink(head);// 更新头结点,指向next } final int srcStart = head.readIndex;// srcStart: 表示可读起点 int srcEnd = head.get();// 表示自从创建开始已经添加个数 final int srcSize = srcEnd - srcStart;// 两者相减,表示当前可回收对象数量 if (srcSize == 0) { return false; } final int dstSize = dst.size; final int expectedCapacity = dstSize + srcSize; if (expectedCapacity > dst.elements.length) {// 超出「Stack」数组长度需要扩容 final int actualCapacity = dst.increaseCapacity(expectedCapacity);//对「Stack」数组扩容,实际扩容规则按「Stack」规则计算的,所以扩容后的实际容量 不一定与期望容量相等,有可能不扩容 srcEnd = min(srcStart + actualCapacity - dstSize, srcEnd);// 根据「Stack」实际容量最终确定回收终点索引 } if (srcStart != srcEnd) {// 循环遍历并复制 final DefaultHandle[] srcElems = head.elements; final DefaultHandle[] dstElems = dst.elements; int newDstSize = dstSize; for (int i = srcStart; i < srcEnd; i++) { DefaultHandle<?> element = srcElems[i]; if (element.recycleId == 0) { element.recycleId = element.lastRecycledId; } else if (element.recycleId != element.lastRecycledId) {// 简单做一下重复回收判断,如果现值不相等,表示创建线程和回收线程并非同一个线程 抛出异常 throw new IllegalStateException("recycled already"); } srcElems[i] = null; if (dst.dropHandle(element)) {// 本次回收需要按照一定比例丢弃对象,并不是全盘接收 // Drop the object. continue; } element.stack = dst;// 不需要丢弃,复制回收对象到Stack目标数组中 dstElems[newDstSize ++] = element; } if (srcEnd == LINK_CAPACITY && head.next != null) { // Add capacity back as the Link is GCed. this.head.relink(head.next);// 当前的Link的对象已经跑了一遍回收,且所指向的下一个节点不为NULL 更新head指向下一个Link节点,当前的Link需要被GC } head.readIndex = srcEnd; if (dst.size == newDstSize) {// 再次判断目标数组是否写入新数据 return false; } dst.size = newDstSize;// 更新目标Stack的已使用容量大小的值 return true; } else { // The destination stack is full already. return false; } }
Head的relink重链接到下一个
void relink(Link link) { reclaimSpace(LINK_CAPACITY); this.link = link; }
private void reclaimSpace(int space) {
availableSharedCapacity.addAndGet(space);
}
WeakOrderQueue的hasFinalData是否还有数据
这个很简单,即最后一个Link是否还有可以转移的。
boolean hasFinalData() { return tail.readIndex != tail.get(); }
WeakOrderQueue的reclaimAllSpaceAndUnlink释放所有空间,并从链表中删除
这个操作就是当所在的线程被回收了,所有的对象也释放了,但是因为有Stack的单链表还引用着,还不能释放,所以要释放剩余的Link,并从单链表中删除。
void reclaimAllSpaceAndUnlink() { head.reclaimAllSpaceAndUnlink(); this.next = null; }
Head的reclaimAllSpaceAndUnlink释放所有空间
其实就是从head的Link开始,删除到最后,把空间回收了。
void reclaimAllSpaceAndUnlink() { Link head = link; link = null; int reclaimSpace = 0; while (head != null) { reclaimSpace += LINK_CAPACITY; Link next = head.next; // Unlink to help GC and guard against GC nepotism. head.next = null; head = next; } if (reclaimSpace > 0) { reclaimSpace(reclaimSpace); } }
Stack的increaseCapacity扩容
扩容两倍,不超过最大限制,把数组元素都复制过去。
int increaseCapacity(int expectedCapacity) { int newCapacity = elements.length; int maxCapacity = this.maxCapacity; do { newCapacity <<= 1; } while (newCapacity < expectedCapacity && newCapacity < maxCapacity); newCapacity = min(newCapacity, maxCapacity); if (newCapacity != elements.length) { elements = Arrays.copyOf(elements, newCapacity); } return newCapacity; }