池化内存分配二
PoolChunk
poolChunk表示的内存池中一整块的内存(默认16M),也是内存池向java虚拟机申请和释放的最小单位,即内存池每次会向虚拟机申请一个PoolChunk内存来进行分配,并在PoolChunk空闲时将PoolChunk中的内存释放。
内存池对于内存的分配其最终分配的是内存所处的PoolChunk以及PoolChunk下的句柄handle。
- page:page是PoolChunk的分配的最小单位,默认的1个page的大小为8kB
- run:表示的是一个page的集合
- handle:句柄,用于表示poolChunk中一块内存的位置,大小,使用情况等信息,下面的图展示了一个handle的对应的位数的含义。可以看到一个handle其实是一个64为的数据,其前15位表示的是这个句柄所处的位置,在chunk中page偏移索引,即第几页,从0开始,然后15位表示的是这个句柄表示的是当前位置可分配多少页,isUsed表示这一段内存是否被使用,isSubpage表示的这一段内存是否用于subPage的分配,bitmapIdx表示的是这块内存在subPage中bitMap的第几个

PoolChunk的数据结构
final class PoolChunk<T> implements PoolChunkMetric { ... //所处的PoolArena final PoolArena<T> arena; //维护的内存块,用泛型区分是堆内存还是直接内存, //对于堆内存,它是一个byte数组,对于直接内存,它是(jvm)ByteBuffer, //但无论是哪种形式,其内存大小默认都是16M。 final T memory; //表示这个PoolChunk是没进行池化操作的,主要为Huge的size的内存分配 final boolean unpooled; final int offset; //存储的是有用的run中的第一个和最后一个Page的句柄 private final LongLongHashMap runsAvailMap;//管理所有有用的run,这个数组的索引是SizeClasses中page2PageIdx计算出来的idx //即sizeClass中每个size一个优先队列进行存储 private final LongPriorityQueue[] runsAvail;//管理这个poolchunk中所有的poolSubPage private final PoolSubpage<T>[] subpages; //一个page的大小 private final int pageSize; //pageSize需要左移多少位 private final int pageShifts; //这个chunk的大小 private final int chunkSize; //主要是对PooledByteBuf中频繁创建的ByteBuffer进行缓存,以避免由于频繁创建的对象导致频繁的GC private final Deque<ByteBuffer> cachedNioBuffers; //空闲的byte值 int freeBytes; //所处的PoolChunkList PoolChunkList<T> parent; //所处双向链表前一个PoolChunk PoolChunk<T> prev; //所处双向两边的后一个PoolChunk PoolChunk<T> next; }
上面的数据结构中主要是runsAvailMap,runsAvail,subPages和memory这4块数据,下面图描述了这几块数据具体存储的内容。
SizeClasses将sizeClasses表格中isMultipageSize为1的行取出可以组成一个新表格,这里称为Page表格,行数为40。
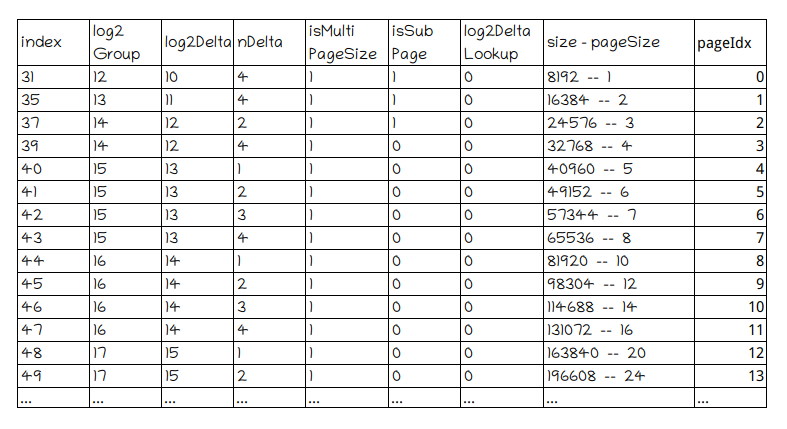
runsAvail是一个 LongPriorityQueue[] 数组,LongPriorityQueue 属于小顶堆,存储 long (非 Long)型的句柄值,通过 LongPriorityQueue.poll() 方法每次都能获取小顶堆内部的最小的 handle 值。这表示我们每次申请内存都是从最低位地址开始分配。runsAvail数组默认长度为40,所有存储在 LongPriorityQueue 对象的 handle 都表示一个可用的内存块 run。并且可分配pageSize大于等于(pageIdx=index)上的pageSize,小于(pageIdex=index+1)的pageSize。
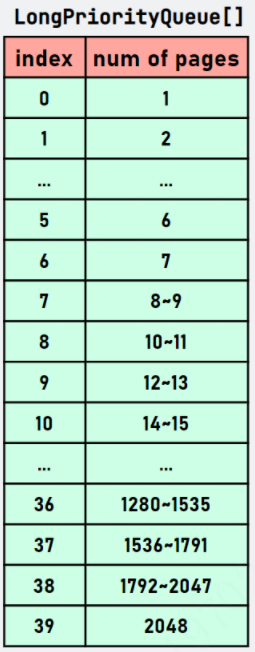
第一列对应的是 LongPriorityQueue 索引,对应Page表格的pageIdx,而第二列对应的是该 LongPriorityQueue 存储的 handle 能管理空闲的 page 的数量,对应Page表格的size-pageSize。比如当 index=1,存储的 handle 能管理的 page 数量为 1,index=8,存储的 handle 能管理空闲的 page 数量为 8 和 9。注意,这会有一个向上取整和向下取整的关系。当我们申请内存时会向上取整(值偏大),比如通过我需要 9 个 pages,通过 pages2pageIdx() 方法得到的 index=8。这样我们就可以从 index=8 的 LongPriorityQueue 开始向后找到第一个合适的 run 用于当前的内存分配,因为 index=8 以上的能够满足我 8 个 page 的内存申请请求。
当我们把一个 run 拆分成两部分后,另一部分用于当前内存申请,而另一部分还需要写回 LongPriorityQueue 对象中。但选择哪个对象还是取决于 run 所管理的 page 数量,这时会通过 pages2pageIdxFloor() 方法向下取整(值偏小)获得 index,再把 run 的 handle 信息写入 LongPriorityQueue[index] 对象中。
如runsAvail[11]上的handle的size可分配pageSize可能为16 ~ 19,
假如runsAvail[11]上handle的size为18,如果该handle分配了7个page,剩下的11个page,这时要将该handle移动runsAvail[8](当然,handle的信息要调整)。
这时如果要找分配6个page,就可以从runsAvail[5]开始查找runsAvail数组,如果前面runsAvail[5]~runsAvail[7]都没有handle,就找到了runsAvail[8]。
分配6个page之后,剩下的5个page,handle移动runsAvail[4]。
runsAvailMap的数据结构是LongLongHashMap,LongLongHashMap是特殊的存储 long 原型的 HashMap,底层采用线性探测法。Netty 使用 LongLongHashMap 存储某个 run 的首页偏移量和句柄值的映射关系、最后一页偏移量和句柄值的映射关系。这么存储的原因为了在向前、向后合并的过程中能通过 pageOffset 偏移量获取句柄值,进而判断是否可以进行向前合并操作。
long handle
jemalloc4 的 handle 的含义与 jemalloc3 不同,具体如下图所示:
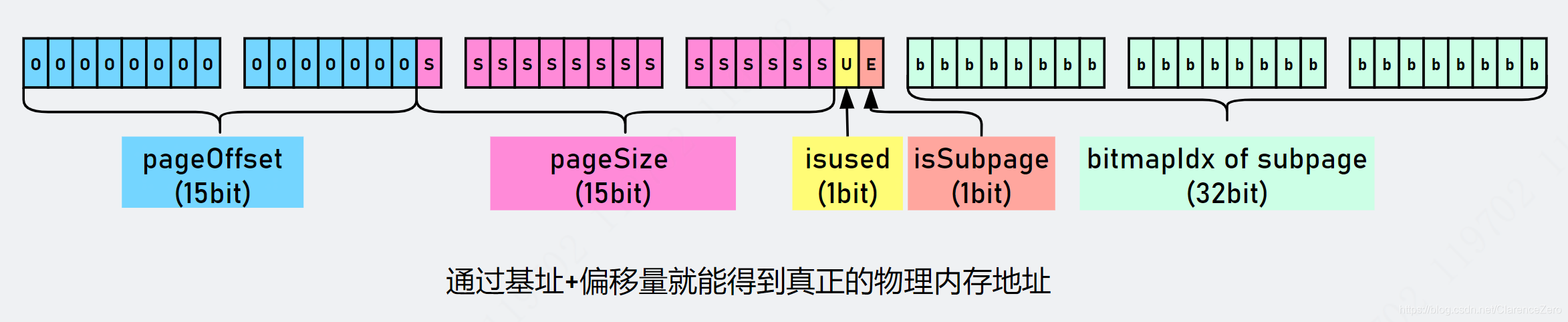
主要的区别是重新定义了高 32 位的含义。我们知道 PoolChunk 默认向 JVM 申请个 16MB 的大的内存块,并拆分成 2048 个 page。可以想象为每个 page 进行标号,从 0 开始一直到 2047。通过 pageOffset + pageSize 就能定位某一个 run 区域,它是由 pageSize 个 page 组成的,起始的 page 为 pageOffset。对 ByteBuffer 对象而言,内部会有一个 long 型的 memoryAddress 绝对地址,因此可以通过绝对地址+偏移量定位任意 page 的实际地址。
我们之前说过,run 表示的是由若干个 page 组成的内存块。而 isUsed 则是标记当前 run 的使用状态。isSubpage 表示当前 run 是否用于 Small 级别内存分配。后 32 位表示 bitmap 的索引信息,与 jemalloc3 表示的含义一样。
run 是由若干个连续的 page 组成的内存块的代称,可以被 long 型的 handle 表示。随着内存块的分配和回收,PoolChunk 会管理着若干个不连续的 run。
其中memory部分绿色表示已经分配了的页,空白的表示还没被分配的页,青色部分表示的被分配为subPage的页。
可以看到runsAvailMap存储的是runOffset->handle之间的键值对,并且其存储的是空闲块的第一页和最后一页的句柄。runsAvail则是维护的一个优先队列数组,其数组的索引其实是size对应的sizeIdx,可以看到空闲页都为2页的三块内存的句柄都存在了一个优先队列中,而空闲页为5页的内存则存在另一个对应位置的优先队列中。对应LongPriorityQueue数组中index为1时num of page 为2,index为4时num of page 为5。subPages则数一个PoolSubPage数组,其数组的索引为page的runOffset,存储的是以这个offset开始的PoolSubPage对象

下面图描述了对上面那幅图进行了一次3个page的分配操作后对应的内存的数据结构,其中红色表示的是这次分配的内存,可以看到原来在5kB的内存数据到2kB中,并且存储在runsAvaliMap中的对应的key也由原来的12移到了现在的15

PoolChunk.allocate
核心的内存分配是在 PoolChunk 完成。PoolChunk.allocate可以完成 Small&Normal 两种级别的内存分配,它是根据 sizeIdx 采用不同的分配策略。这个方法会有两条支路,一条是分配 Small 规格内存块,一条是分配 Normal 规格内存块。可以看到这个allocate方法其实就是将subPage的分配委托给allocateSubpage方法,对于不是subPage的分配委托给了allocateRun进行操作。
boolean allocate(PooledByteBuf<T> buf, int reqCapacity, int sizeIdx, PoolThreadCache cache) { final long handle;//long型的handle表示分配成功的内存块的句柄值 if (sizeIdx <= arena.smallMaxSizeIdx) {//这里的sizeIdx表示的是sizeClass的size2sizeIdx计算的对应的sizeIdx,这里的smallMaxSizeIdx表示的是最大的subPage的对应的索引,默认值38 // small handle = allocateSubpage(sizeIdx);// 这种size则以subPage的形式进行分配 if (handle < 0) { return false; } assert isSubpage(handle); } else { // normal // runSize must be multiple of pageSize int runSize = arena.sizeIdx2size(sizeIdx); handle = allocateRun(runSize);//利用allocateRun分配多个整的page if (handle < 0) { return false; } } //尝试从cachedNioBuffers缓存中获取ByteBuffer对象,一个PoolChunk下的所有的这些ByteBuffer,并在ByteBuf对象初始化时使用 ByteBuffer nioBuffer = cachedNioBuffers != null? cachedNioBuffers.pollLast() : null; initBuf(buf, nioBuffer, handle, reqCapacity, cache);//初始化ByteBuf对象 return true; }
分配 Normal 级别内存块
PoolChunk.allocateRun
allocateRun是分配多个page操作,其主要操作是从runAvail中找到最接近当前需要分配的size的内存块,然后将其进行切分出需要分配的内存块,并将剩下的空闲块再存到runAvail和runsAvailMap中。
private long allocateRun(int runSize) { //计算所需的page数量 int pages = runSize >> pageShifts; //根据page的数量计算对应的pageIdx //因为runAvail这个数组用的则是这个idx为索引的 //pages2pageIdx方法会将申请内存大小对齐为上述Page表格中的一个size。 //例如申请172032字节(21个page)的内存块,pages2pageIdx方法计算结果为13,实际分配196608(24个page)的内存块。 int pageIdx = arena.pages2pageIdx(pages); //这里的runsAvail保证的是runsAvail和runsAvailMap数据的同步 synchronized (runsAvail) { //从当前的pageIdx开始遍历runsAvail,从ranAvail中找到最近的能进行此次分配idx索引 int queueIdx = runFirstBestFit(pageIdx); if (queueIdx == -1) { return -1; } //从这个索引中获取对应的run的数据,即为能进行此次分配的空闲段 PriorityQueue<Long> queue = runsAvail[queueIdx]; long handle = queue.poll(); assert !isUsed(handle); //从runsAvail和runsAvailMap中移除这个handle removeAvailRun(queue, handle); if (handle != -1) { //将这一块内存进行切分,剩余空闲的内存继续存储到ranAvail和runsAvailMap中 handle = splitLargeRun(handle, pages); } //更新freeBytes,减少可用内存字节数 freeBytes -= runSize(pageShifts, handle); return handle; } }
runFirstBestFit
从pageIdx开始搜索 runsAvail 小顶堆数组寻找最合适的 run 用于此次内存分配。它很简单,从 pageIdx 不断遍历寻找即可
// 从pageIdx开始搜索最合适的run用于内存分配 private int runFirstBestFit(int pageIdx) { if (freeBytes == chunkSize) { return arena.nPSizes - 1; } // 比较简单,从pageIdx向后遍历,找到queue!=null且不为空的LongPriorityQueue for (int i = pageIdx; i < arena.nPSizes; i++) { LongPriorityQueue queue = runsAvail[i]; if (queue != null && !queue.isEmpty()) { return i; } } return -1; }
splitLargeRun
根据所需要的页的数量计算各种所需要的信息,然后通过 toRunHandle() 方法生成 handle 句柄值并返回。其中,有一个比较重要步骤的是更新那两个重要的数据结构。
private long splitLargeRun(long handle, int needPages) { assert needPages > 0; // 从handle中获取run管理的空闲的page数量 int totalPages = runPages(handle); assert needPages <= totalPages; //分配后剩余page数 int remPages = totalPages - needPages; if (remPages > 0) {//如果还有剩余,需要重新生成run(由handle具象化)并写入两个重要的数据结构中, 一个是 LongLongHashMap runsAvailMap,另一个是 LongPriorityQueue[] runsAvail; int runOffset = runOffset(handle);//获取偏移量 // keep track of trailing unused pages for later use //计算剩余page开始偏移量 剩余空闲页偏移量=旧的偏移量+分配页数 int availOffset = runOffset + needPages; //根据偏移量、页数量以及isUsed状态生成新的句柄变量,这个变量表示一个全新未使用的run long availRun = toRunHandle(availOffset, remPages, 0); //将availRun插入到runsAvail,runsAvailMap中 insertAvailRun(availOffset, remPages, availRun); // not avail 生成用于此次分配的句柄变量 return toRunHandle(runOffset, needPages, 1); } //mark it as used 恰好满足,只需把handle的isUsed标志位置为1 handle |= 1L << IS_USED_SHIFT; return handle; }
PoolChunk.insertAvailRun
从 runsAvail 数组中选择合适的 LongPriorityQueue 并写入。
private void insertAvailRun(int runOffset, int pages, long handle) { // 将句柄信息写入对应的小顶堆 // 根据页数量向下取整,获得「pageIdxFloor」,这个值即将写入对应runsAvail数组索引的值 int pageIdxFloor = arena.pages2pageIdxFloor(pages); LongPriorityQueue queue = runsAvail[pageIdxFloor]; queue.offer(handle); // 将首页和末页的偏移量和句柄值记录在runsAvailMap对象,待合并run时使用 insertAvailRun0(runOffset, handle); if (pages > 1) { // 当页数量超过1时才会记录末页的偏移量和句柄值 insertAvailRun0(lastPage(runOffset, pages), handle); } } private void insertAvailRun0(int runOffset, long handle) { long pre = runsAvailMap.put(runOffset, handle); assert pre == -1; } private void insertAvailRun0(int runOffset, long handle) { long pre = runsAvailMap.put(runOffset, handle); assert pre == -1; }
jemalloc4 的算法思想,相对于 jemalloc3 而言存储的信息变得更少了,而且分配也变得更快速。jemalloc3 需要对二叉树进行搜索,虽然位运算加快了一点,但是源码阅读非常吃力,而 jemalloc4 算法思想足够简单,分配 Normal 主要步骤是搜索合适的 run,然后对 run 进行拆分并重新生成两个(如何恰好满足就直接修改 isUsed 标志位即可)handle,一个用于当前内存申请,另一个重新写入 runAvails 和 runsAvailMap。这样就完成一次 Normal 级别内存申请。
分配 Small 级别内存块
jemalloc4 把 Small 级别的内存范围扩大了,现在的 Small 内存范围是 [16Byte, 28KB] ,而之前最多也就不能超过 8KB。优点是除了减少内存碎片外,还方便内存管理。之前jemalloc3 只是等分其中的一个 page。而 jemalloc4 是等分 N 个 page,其中 N>=1。这个 N 的取值是拆分规格值和 pageSize 的最小公倍数再除以 pageSize。比如申请内存大小为 16Byte,则只需要等分 1 个page,而申请内存大小为 28KB,需要等分 7 个 page,因为它 28KB=28672 和 pageSize=8192 的最小公倍数为 57344(57344/8192=7)。这样会有2个28K,先将此次分配的 PoolSubpage 节点与 smallSubpagePools[38] 对应的 head 节点连接成双向链表,这个下标怎么来的,因为28K的idx是38,分配的 PoolSubpage 的 numAvail 可用内存数为2,在获得handle的过程中,会减掉1,如果可用内存数等于0,则 smallSubpagePools[38] 对应的 head 节点的next置为null,说明相应大小的内存没有多余的。如果可用内存数等于大于0,则不变。28k的还是维持原状,如果申请的是8K,因为刚好能整除,可用内存为1,减去1,则为0。下次再申请同样的内存,就需要重新分配了,而28K的因为可用内存最开始为2,减去1,还是大于0。所以下次申请28K还有多余,就可以直接多出来的部分。这样就能满足类型 28KB 这种不是 2 的次幂的内存大小。对于如何管理 subpage 还是和 jemalloc3 没有太大的区别,还是构建一个 PoolSubpage 对象用于管理 Small 级别规格的内存块,它的底层内部还是通过 long[] 数组记录每一等分的使用状况。
将例子改为
ByteBuf buffer = ByteBufAllocator.DEFAULT.heapBuffer(28*1024);
ByteBuf buffer1 = ByteBufAllocator.DEFAULT.heapBuffer(28*1024);
PoolArena.allocate
private void allocate(PoolThreadCache cache, PooledByteBuf<T> buf, final int reqCapacity) { final int sizeIdx = size2SizeIdx(reqCapacity);//20480对应 SizeClasses表格中 id36 if (sizeIdx <= smallMaxSizeIdx) {//38 tcacheAllocateSmall(cache, buf, reqCapacity, sizeIdx); } else if (sizeIdx < nSizes) {//76 tcacheAllocateNormal(cache, buf, reqCapacity, sizeIdx); } else { int normCapacity = directMemoryCacheAlignment > 0 ? normalizeSize(reqCapacity) : reqCapacity; // Huge allocations are never served via the cache so just call allocateHuge allocateHuge(buf, normCapacity); } }
PoolArena.tcacheAllocateSmall
private void tcacheAllocateSmall(PoolThreadCache cache, PooledByteBuf<T> buf, final int reqCapacity, final int sizeIdx) { if (cache.allocateSmall(this, buf, reqCapacity, sizeIdx)) {//从缓存中取,开始为false // was able to allocate out of the cache so move on return; } /** * Synchronize on the head. This is needed as {@link PoolChunk#allocateSubpage(int)} and * {@link PoolChunk#free(long)} may modify the doubly linked list as well. */ final PoolSubpage<T> head = smallSubpagePools[sizeIdx]; final boolean needsNormalAllocation; synchronized (head) { final PoolSubpage<T> s = head.next; needsNormalAllocation = s == head; if (!needsNormalAllocation) { assert s.doNotDestroy && s.elemSize == sizeIdx2size(sizeIdx); long handle = s.allocate(); assert handle >= 0; s.chunk.initBufWithSubpage(buf, null, handle, reqCapacity, cache); } } if (needsNormalAllocation) { synchronized (this) { allocateNormal(buf, reqCapacity, sizeIdx, cache); } } incSmallAllocation(); }
第一次申请内存时会直接调用 allocateNormal(buf, reqCapacity, sizeIdx, cache); head.next 还是 head,没有多余内存。第二次申请内存时,因为第一次申请的PoolSubpage可用内存大于0,head.next关联了第一次申请的 PoolSubpage,head.next 不是 head,直接调用initBufWithSubpage。第一次调用前面步骤还是和normal一样,到allocate方法就和 normal不一样,调用了 allocateSubpage(sizeIdx)。normal调用了 allocateRun(runSize)方法,在上文说明过。
PoolChunk.allocateSubpage
这是 PoolChunk 关于 Small 规格内存分配的核心逻辑,重点是前面所说的找到申请的 size 和 pageSize 的最小公倍数,这样就能调用 allocateRun() 方法分配若干个 page,然后创建 PoolSubpage 对象,最后委托 PoolSubpage 进行等分操作。
private long allocateSubpage(int sizeIdx) { // 从「PoolArena」获取索引对应的「PoolSubpage」。 // 在「SizeClasses」中划分为 Small 级别的一共有 39 个, // 所以在 PoolArena#smallSubpagePools数组长度也为39,数组索引与sizeIdx一一对应 PoolSubpage<T> head = arena.findSubpagePoolHead(sizeIdx); // PoolSubpage 链表是共享变量,需要加锁 synchronized (head) { // 获取申请的size和pageSize的最小公倍数 int runSize = calculateRunSize(sizeIdx); // 申请若干个page,runSize是pageSize的整数倍 long runHandle = allocateRun(runSize); if (runHandle < 0) { // 分配失败 return -1; } // 实例化「PoolSubpage」对象 int runOffset = runOffset(runHandle);//内存块在将这块内存分为大小相等的以elmSize的subPage中的偏移量,或者说起始地址 assert subpages[runOffset] == null; int elemSize = arena.sizeIdx2size(sizeIdx);//需要的内存大小 PoolSubpage<T> subpage = new PoolSubpage<T>(head, this, pageShifts, runOffset, runSize(pageShifts, runHandle), elemSize); //runSize(pageShifts, runHandle) //申请的size和pageSize的最小公倍数 // 由PoolChunk记录新创建的PoolSubpage,数组索引值是首页的偏移量,这个值是唯一的,也是记录在句柄值中 // 因此,在归还内存时会通过句柄值找到对应的PoolSubpge对象 subpages[runOffset] = subpage; // 委托PoolSubpage分配内存 return subpage.allocate(); } }
PoolSubpage
属性
final PoolChunk<T> chunk; private final int pageShifts; private final int runOffset;//chunk中的偏移 private final int runSize;//申请的size和pageSize的最小公倍数 private final long[] bitmap;//位图数组,描述某一尺寸内存的状态 每一位都可以表示是该内存否可用了 1表示不可用 0表示可用 PoolSubpage<T> prev; PoolSubpage<T> next; boolean doNotDestroy;//是否销毁 int elemSize;//所需内存大小 private int maxNumElems;//最大可分配的内存数 private int bitmapLength;//实际用到的位图数 private int nextAvail;//下一个可用的位图索引 private int numAvail;//可用内存的个数
构造函数
PoolSubpage其实不会实际分配内存,只是做了分配内存的记录,记录一个页中哪些分配完了,哪些可以分配,
PoolSubpage(PoolSubpage<T> head, PoolChunk<T> chunk, int pageShifts, int runOffset, int runSize, int elemSize) { this.chunk = chunk;//所在块 this.pageShifts = pageShifts;//8192就是位移13位,所以pageShifts是13 this.runOffset = runOffset;//chunk中的偏移 this.runSize = runSize;//申请的size和pageSize的最小公倍数 this.elemSize = elemSize;//分割的内存尺寸大小 bitmap = new long[runSize >>> 6 + LOG2_QUANTUM]; // runSize / 64 / QUANTUM 64位的位图数组,描述某一尺寸内存的状态 每一位都可以表示是该内存否可用了 1表示不可用 0表示可用 doNotDestroy = true; if (elemSize != 0) { maxNumElems = numAvail = runSize / elemSize;//最小公倍数 nextAvail = 0; bitmapLength = maxNumElems >>> 6;//实际需要用的到的long类型的位图的个数,每个位图有64位,取整 if ((maxNumElems & 63) != 0) {//有余数就多一个 bitmapLength ++; } for (int i = 0; i < bitmapLength; i ++) {//实际用到的位图数 bitmap[i] = 0;//初始化位图 } } addToPool(head);//将当前子页加到head的后面,是个双向循环链表 }
bitmap = new long[runSize >>> 6 + LOG2_QUANTUM]; 这里解释下:这里其实是4+6,4是表示16是2的4次方,6表示64是2的6次方,即用申请的size和pageSize的最小公倍数除以16除以64,这里的意思就是以最小的尺寸16B来计算,能分几个16B大小的内存,然后用位图表示这个内存是否被用需要1位,如果用long类型的位图就是64位,所以除以64,就知道需要多少个64位的位图来表示这些16B的内存的状态。拿上面的例子说明,申请内存大小为 28KB, 28KB=28672 和 pageSize=8192 的最小公倍数为 57344,算出来需要56这样的位图,所以位图数组长度是56。
PoolSubpage.addToPool(head)
将当前子页加到head的后面,是个双向循环链表。
private void addToPool(PoolSubpage<T> head) { assert prev == null && next == null; prev = head; next = head.next; next.prev = this; head.next = this; }
后续如果有相同尺寸的请求,都会在这个子页里分配,直到子页满了后,会从链表中删除。就像上面的例子,第一次申请了28K,系统提供57344,会有3.5个page多出来,多的部分就添加到此head后面,第二次申请的时候直接从这里分配,如果没有多余的内存,就将next只为null。
subpages[runOffset] = subpage子页创建后就被添加到了子页数组里,后续添加的PoolSubpage都会添加进head形成的双向循环链表中。
PoolSubpage.allocate()
对子页可分配的内存做了记录并分配了位图的一位,并返回一个64位的句柄handle
long allocate() { if (numAvail == 0 || !doNotDestroy) {//没有可用的容量或者要销毁 return -1; } //获取下一个可用的位图索引,不是位图数组 final int bitmapIdx = getNextAvail(); int q = bitmapIdx >>> 6;//获取所在的位图在数组中的索引 int r = bitmapIdx & 63;//获取64余数,0-63 位图中的索引信息 也就是第几位要设置为1 assert (bitmap[q] >>> r & 1) == 0;//根据位图索引获取这个位图中的位置是0表示可用 bitmap[q] |= 1L << r;//将可用的位图索引设置为1,即不可用 if (-- numAvail == 0) {//如果没有可用了,就从链表中删除。上面的例子,28K分配57344,numAvail是2,减掉1,还是不等于0,就不会进行removeFromPool();但是如果申请的是8K,刚好倍数够,减掉1,等于0,就执行removeFromPool(); removeFromPool(); } return toHandle(bitmapIdx); }
getNextAvail
这个就是获取下一个位图的索引bitmapIdx ,这里的索引是32位是由两部分组成的:
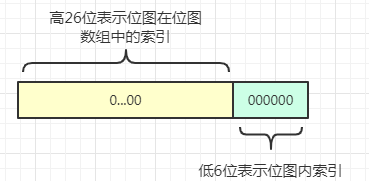
this.nextAvail最开始是0,会直接返回0,并且把this.nextAvail设置为-1,这样第二次就要进行findNextAvail了,这样确实第一次就不需要运算了,用一个判断来提升性能。
private int getNextAvail() { int nextAvail = this.nextAvail; if (nextAvail >= 0) { this.nextAvail = -1; return nextAvail;//第一次直接返回,后面就要findNextAvail } return findNextAvail();//-1表示要找 }
findNextAvail
bitmapLength就是实际上用到的位图数,所以不需要整个位图数据来遍历,只需要遍历bitmapLength个位图。
把每个位图取出来按位取反,如果不为0,说明没取反前还有位置有0存在,这个位图还能用,否则就说明所有位都是1了,取反就等于0,不可用了,如果还能用,就要看用哪一位findNextAvail0,默认是从低位开始的。如果都不能用就返回-1。
private int findNextAvail() { final long[] bitmap = this.bitmap; final int bitmapLength = this.bitmapLength; for (int i = 0; i < bitmapLength; i ++) { long bits = bitmap[i]; if (~bits != 0) { return findNextAvail0(i, bits); } } return -1; }
findNextAvail0
这里是真正使用位图的时候,先看传入参数,传入的i其实就是位图所在位图数组的索引,bits就是位图本身。首先会有i << 6,这个就是先求出bitmapIdx的26位高位的值baseVal ,就是位图索引对应的值,然后遍历位图,j表示的就是位图里的第j位,也就是bitmapIdx的低6位,而且是从低位开始判断,取值是0-63。然后(bits & 1)取出最低位,如果是0,表示可用分配,然后就将baseVal | j,表示高26位和低6位合并了,这样才算是完整的bitmapIdx。而且这样计算出来的bitmapIdx刚好也是已经分配的内存数-1,所以最后还要和最大可分配数比较,小于才能分配,因为等于就已经超出最大可分配数maxNumElems ,因为bitmapIdx是从0开始的,最大应该是maxNumElems -1。如果低位不可分配就将位图右移一位,也就是取出第二位继续判断。
private int findNextAvail0(int i, long bits) { final int maxNumElems = this.maxNumElems;//最大可分配数 final int baseVal = i << 6;//要分配的起始索引,根据第i个位图,如果是0表示0-63进行分配 1表示64-127分配 //遍历位图的每一位,从最低位开始遍历,0表示没有过 for (int j = 0; j < 64; j ++) {//j表示位图里第j位,从低位到高位0-63 if ((bits & 1) == 0) {//取出最低位,为0表示可用 int val = baseVal | j;//加上位置序号j后的新的索引值,比如开始是0,第一个+0索引就是0,然后+1,索引1,类似最后索引是baseVal+63 if (val < maxNumElems) {//如果索引没到最大可分配数就返回,其实最大索引就是maxNumElems-1 return val; } else { break;//等于就不行了,跳出循环 } } bits >>>= 1;//位图右移,即从低位往高位 } return -1; }
举个例子,比如我申请的内存是32B,那么总共需要的位图应该是8k/32/64=4个,最大可分配数maxNumElems=8k/32=256,这里的这4个位图,每一个刚好对应一个内存分配,总共256个。现在32B的内存来了,首先拿出第0个位图,也就是i=0,发现可用,于是就开始0<<<6=0,高26位全是0了,再看位图的64位情况,发现底0位就可以用,与是就返回了,这个bitmapIdx就是0。同样的,假设第0个位图用满了,如果我又来了一个32B,那就需要用第1个位图,最后返回的bitmapIdx就是1000000。
我们继续,看看返回后做了什么。
首先是bitmapIdx >>> 6,得到高26位,获取位图在位图数组的索引。
然后bitmapIdx & 63,得到低6位,,获取位图内部索引。
最后进行设置bitmap[q] |= 1L << r,将这个位图内部索引所对应的值设置为1,表示不可用了。
removeFromPool
如果发现可用的内存数量numAvail是0了,就会将这个页从双向循环链表中删除。上面的例子,28K分配57344,numAvail是2,减掉1,还是不等于0,就不会进行removeFromPool();但是如果申请的是8K,刚好倍数够,减掉1,等于0,就执行removeFromPool();导致smallSubpagePools数组对应下标的 next 节点为空。
private void removeFromPool() { assert prev != null && next != null; prev.next = next; next.prev = prev; next = null; prev = null; }
toHandle
private long toHandle(int bitmapIdx) {
int pages = runSize >> pageShifts;
return (long) runOffset << RUN_OFFSET_SHIFT
| (long) pages << SIZE_SHIFT
| 1L << IS_USED_SHIFT
| 1L << IS_SUBPAGE_SHIFT
| bitmapIdx;
}
PoolChunk的initBuf
void initBuf(PooledByteBuf<T> buf, ByteBuffer nioBuffer, long handle, int reqCapacity, PoolThreadCache threadCache) { if (isRun(handle)) {//判断是否是Subpage,否进入 buf.init(this, nioBuffer, handle, runOffset(handle) << pageShifts, reqCapacity, runSize(pageShifts, handle), arena.parent.threadCache()); } else {//是进入 initBufWithSubpage(buf, nioBuffer, handle, reqCapacity, threadCache); } }
PoolChunk的initBufWithSubpage
这里直接拿Subpage讲,因为不是Subpage也是调用了相同的buf.init方法,只是参数不一样。
void initBufWithSubpage(PooledByteBuf<T> buf, ByteBuffer nioBuffer, long handle, int reqCapacity, PoolThreadCache threadCache) { int runOffset = runOffset(handle);//偏移值 int bitmapIdx = bitmapIdx(handle);//获取低32位的handle,即id PoolSubpage<T> s = subpages[runOffset];//获取对应的子页 assert s.doNotDestroy; assert reqCapacity <= s.elemSize;//请求容量不会大于规范后的 buf.init(this, nioBuffer, handle, (runOffset << pageShifts) + bitmapIdx * s.elemSize + offset,//块的偏移地址+页的偏移地址+缓存行的偏移地址(默认0) reqCapacity, s.elemSize, threadCache); }
PooledByteBuf的init
最终会调用到init0:
private void init0(PoolChunk<T> chunk, ByteBuffer nioBuffer, long handle, int offset, int length, int maxLength, PoolThreadCache cache) { assert handle >= 0; assert chunk != null; this.chunk = chunk;//哪个块 memory = chunk.memory;//字节数组,或者内存地址 tmpNioBuf = nioBuffer;//缓存的buffer allocator = chunk.arena.parent;//分配器 this.cache = cache;//线程缓存 this.handle = handle;//句柄 this.offset = offset;//缓存行偏移 this.length = length;//申请的内存大小 this.maxLength = maxLength;//规范化后的内存大小 }
至此分配成功了