前言
- 数据驱动测试的核心就是数据与用例分离
- 数据保存可以使用 Excel,txt,数据库,html 等各种类型的文件
- .txt 文件操作使用内置的open()函数即可,操作可见文件操作
- 本篇博客介绍使用第三方插件 openpyxl 读取并操作 Excel 文件
安装插件
pip install openpyxl -i https://pypi.tuna.tsinghua.edu.cn/simple
步骤
- 打开工作簿: 使用
load_workbook(file_path),file_path 必须存在,工作簿的后缀必须是 .xlsx 结尾 - 实例化:
工作簿名['表单名']定位Excel中的表单 - 获取值: 使用
WorkSheet.cell(横坐标, 纵坐标)定位要操作的元素坐标,使用.value获取到对应坐标的值 - 修改值: 使用
WorkSheet.cell(x,y).value='up_value',将对应坐标的值修改为 up_value - 保存: 修改完Excel文件,一定要保存文件:使用
实例对象.save('表单名')保存文件
示例:
- 需求如下:
已有如下内容的excel文件,现要求将每行数据存入字典,key为表头,所有字典存入一个大列表中.

- 代码如下
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from openpyxl import load_workbook
class DoExcel:
# 1)初始化数据参数:
def __init__(self, file_path, sheet_name):
'''
每次调用函数就实例化文件
:param file_path: excel 文件路径
:param sheet_name: 表单名
'''
self.wb = load_workbook(file_path)
self.sheet = self.wb[sheet_name]
# _get_title 加_类似于私有函数, 只在内部调用
def _get_title(self):
'''
:return: title 获取表头 list,作为key
'''
title = []
# sheet.max_column 最大列
# sheet.cell(1, i).value 循环取出第一行的值,存入列表
for i in range(1, self.sheet.max_column + 1):
title.append(self.sheet.cell(1, i).value)
return title
def get_finally_data(self):
'''
:return: finally_data,list格式
'''
title = self._get_title()
finally_data = [] # 最终数据存入列表
for j in range(2, self.sheet.max_row+1): # 控制最大行
row_data = {} # 每一行数据存在字典中
for i in range(1, self.sheet.max_column+1): # 控制最大列
row_data[title[i-1]] = self.sheet.cell(j, i).value
## 分解::
# key = title[i-1] # 获取key值,注意 i-1
# value = self.sheet.cell(j, i).value
# row_data[key] = value
finally_data.append(row_data)
return finally_data
if __name__ == '__main__':
print(DoExcel('test_data.xlsx', 'parameter').get_finally_data())
- 执行结果
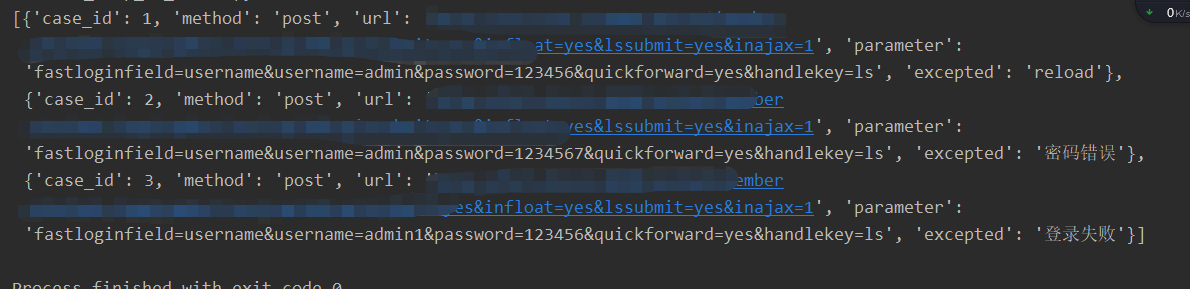
注意事项
- 不要直接在pycharm中新建一个Excel文件!!!
- 如果涉及到写入数据,一定不要打开Excel文件,否则报PermissionError
- 文件名一定要带后缀名,后缀必须是 .xlsx
- AttributeError:'WorkSheet' object has no attribute 'save' 表单没保存的属性,工作簿有
- 文件名大小写敏感
总结
- 上述代码仍有很多优化空间,如异常处理?回写数据处理?参数化如何处理等等
- 处理excel有很多插件,像python强大的数据分析工具pandas,但学会其中一种,达到你的需求即可.