很久前就想开始学习记录本文阅读笔记,一直在整理它的代码,拖到现在。
《摘要》
Long-range dependencies can capture useful contextual information to benefit visual understanding problems.
“大(长)范围的依赖关系可以捕捉到有用的内容信息帮助视频理解问题”,这是作者的论据。
接着提出作者的工作成果CCNet可以包含元素周围的相关信息。CCNet的特点是:
1、GPU memory friendly. Compared with the non-local block, the recurrent criss-cross attention module requires 11× less GPU memory usage.阡陌注意力模块与使用non-local模块比,GPU内存减少11倍。
2、High computational efficiency. The recurrent criss-cross attention significantly reduces FLOPs by about 85% of the nonlocal block in computing long-range dependencies。 阡陌注意力模块与non-local模块比,计算量减少85%
3、The state-of-the-art performance。实验效果好,分别在Cityscapes, ADE20K, and instance segmentation benchmark COCO上进行了实验。
开源代码地址:https://github.com/speedinghzl/CCNet
《介绍》
语义分割是计算机视觉的一个基础研究任务,是给图像中的每个像素分类。该任务在过去几年内一直被研究,现在已经运用到自动驾驶、虚拟现实和图像编辑中。
然后从自己的优势出发进行分类讲解。先讲基于FCN(fully convolutional network)改进的一些算法框架的缺点,they are inherently limited to local receptive fields and short-range contextual information,然后再讲进行长依赖关系捕捉的一些算法方法s及各自的不足,从而引出CCNet算法。方法有:
1、atrous spatial pyramid pooling module with multiscale dilation convolutions for contextual information aggregation
2、PSPNet with pyramid pooling module to capture contextual information
不足有:
1、dilated convolution based methods collect information from a few surrounding pixels and can not generate dense contextual information
2、pooling based methods aggregate contextual information in a non-adaptive manner and the homogeneous contextual information is adopted by all image pixels 同构上下文信息
进行产生密集、点与点上下文信息,方法有:
1、aggregate contextual information for each position via a predicted attention map
2、utilizes a self-attention mechanism [10, 29], which enable a single feature from any position to perceive features of all the other positions,
以上两种方法在效率及降低复杂度欠优化。有没有一种方法可以事半功倍呢?于是提出了criss-cross attention module十字交叉注意力模块,这个东西把算法复杂度从O((H×W)×(H×W)) 降到了 O((H×W)×(H+W−1)),基本上相当于加快了(HxW)/(H+W-1)倍,而且显存友好
作者总结CCNet的优点是:
1、We propose a novel criss-cross attention module in this work, which can be leveraged to capture contextual information from long-range dependencies in a more efficient and effective way
2、We propose a CCNet by taking advantages of two recurrent criss-cross attention modules, achieving leading performance on segmentation-based benchmarks, including Cityscapes, ADE20K and MSCOCO.
《相关工作》
从语义分割和注意力模型两方面进行介绍。
语义分割:从FCN以来,算法的发展以及其中的细节改变,可以看算法原文。
注意力模型:以几种算法为例,分别说明注意力的做法。有:
1、enhanced the representational power of the network by modeling channel-wise relationships in an attention mechanism.
2、use several attention masks to fuse feature maps or predictions from different branches.
3、applied a self-attention model on machine translation.
4、proposed the non-local module to generate the huge attention map by calculating the correlation matrix between each spatial point in the feature map, then the attention guided dense contextual information aggregation.
5、utilized self-attention mechanism to harvest the contextual information.
6、learned an attention map to aggregate contextual information for each individual point adaptively and specifically.
本文的不同之处在于不generate huge attention map to record the relationship for each pixel-pair in feature map。
《方法》
首先介绍网络结构,其次介绍cca module(criss-cross attention module which captures long-range contextual information in horizontal and vertical direction),最后介绍捕捉密集的、全局上下文的recurrent criss-cross attention module.
网络结构
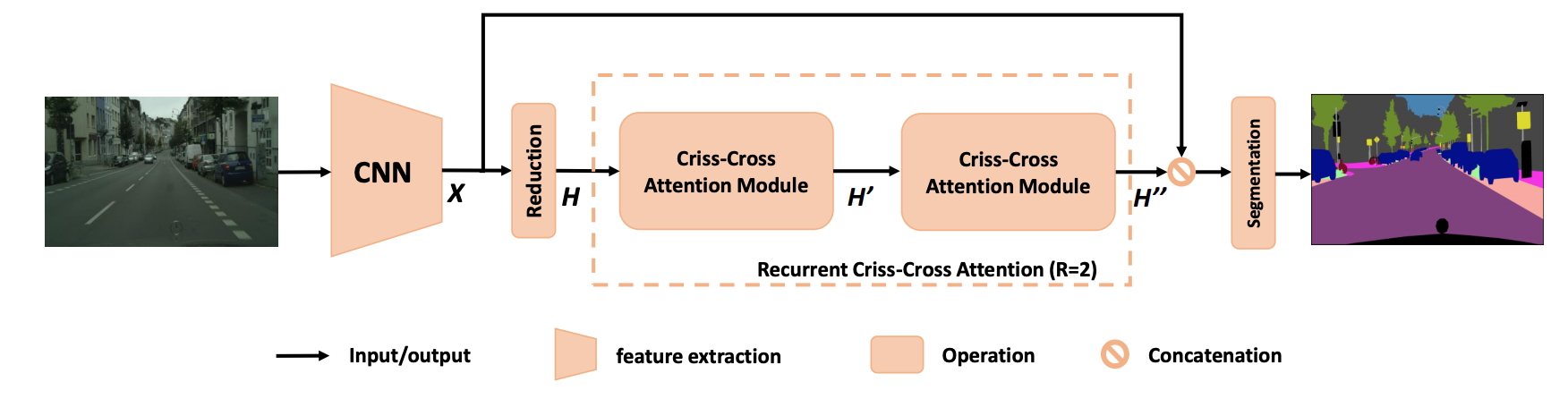
其中的x是特征,reduction模块是进行降维,criss-cross Attention Module是集成大范围的(水平、垂直)内容信息。循环两次可以得到全局的内容信息。
criss-cross attention (CCA) module工作原理如图所示
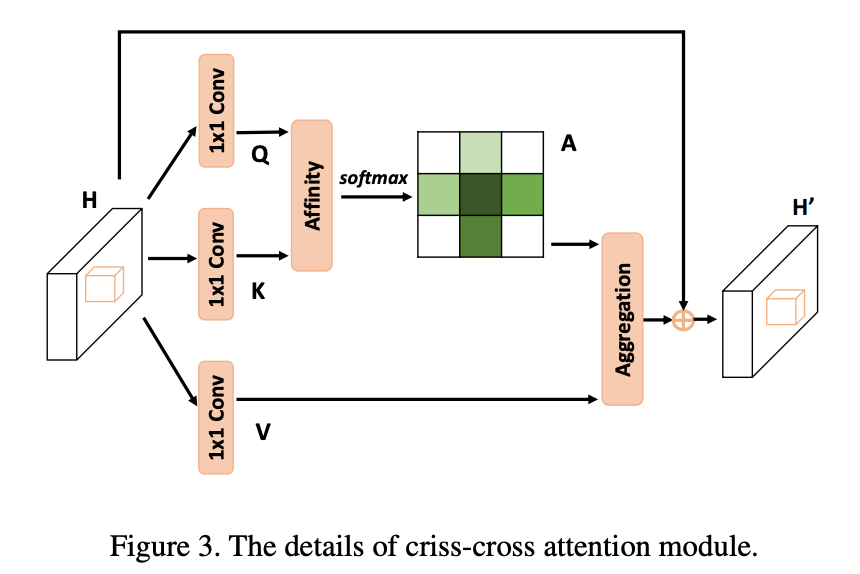
已知特征图H ∈ R C×W×H, CCA模块首先在H的两个卷积层上使用1 × 1 卷积核分别生成特征图 Q 和 K, {Q, K} ∈ R C0×W×H. C0是特征图的通道数,比C小,操作起到维数减小的作用。得到K和Q之后,进一步通过Affinity操作产生注意力特征图(attention maps) A,A ∈ R (H+W−1)×W×H。Affinity具体做法是:
在特征图Q空间维度上的每个小方格u ,可以从特征图K上,对应方格u所在的行和列,得到一个向量Qu ∈ R C1,进一步得到Qu的集合欧姆u,欧姆u的通道数是(H+W-1)*C1,u所在的行和列的(除了u)方格数是H+W-1,欧姆u的第i个元素欧姆iu的通道数是C1,Affinity操作是:
di,u ∈ D ,D ∈ R (H+W−1)×W×H
同样在H上用1x1卷积层可以得到特征图V,V ∈ R C×W×H,A相对于V上的每一个方格u,与V上对应的向量进行乘积等操作就是Aggregation operation。
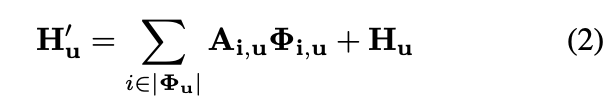
H1 ∈ R C×W×H。之后的部分理解就简单了。
《实验》
略
《总结》
略