借助于高分辨率图像提升低分辨率图像的识别性能。
论文地址:https://arxiv.org/pdf/1908.10027v1.pdf
目前无开源代码
创新点:
1、在模型上在胶囊网络的基础上添加了卷积层,可进行很低分辨率图像的识别;
2、提出了两个损失函数指导VLR(very low resolution)图像识别模型;
3、实验验证了模型的优点。
创新点分析:
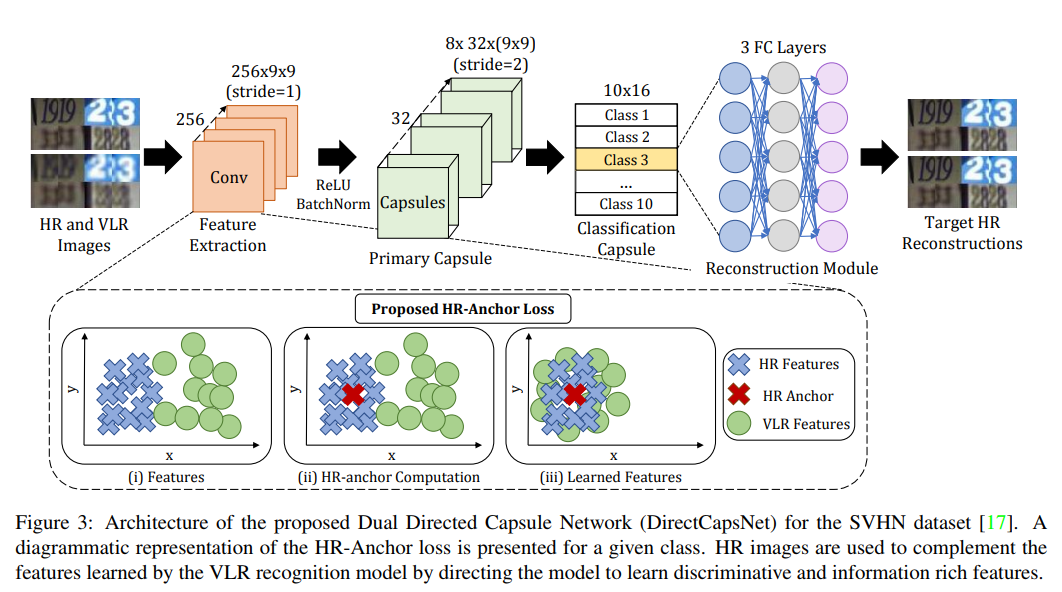
图1
1、第一个创新点分析
如图1 所示,该网路前面是capsule网络,后面加了3个全连接层,这3个全连接层也叫作 reconstruction module,其作用是在网络中编码实例参数参数,从而能解释输入图像,也即重建输入。
2、第二个创新点分析
HR-anchor loss,其公式为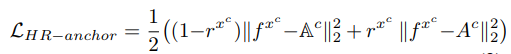 ,rxc 是一个二值变量,当输入样本是高分辨图片时,取值1,当输入是低分率图像时,取值为0,。两个Ac都表示类别c的HR-anchor,某个类别的HR-anchor是高分辨率样本中属于该类别的平均特征向量,第一个带空白的Ac 是一个恒定状态,(高分辨率样本中计算得到的),fxc 是卷积特征,两者相减表示此时低分辨部分被激活,且fxc会更加逼近第一个Ac,如图1所示。第二个Ac是参数,当输入高分辨率图像时,第二部分被激活,fxc和高分辨率特征图的anchor都会被更新。如此,使低分率图特征更加逼近高分辨率特征,学习到更具有分辨性的特征。
,rxc 是一个二值变量,当输入样本是高分辨图片时,取值1,当输入是低分率图像时,取值为0,。两个Ac都表示类别c的HR-anchor,某个类别的HR-anchor是高分辨率样本中属于该类别的平均特征向量,第一个带空白的Ac 是一个恒定状态,(高分辨率样本中计算得到的),fxc 是卷积特征,两者相减表示此时低分辨部分被激活,且fxc会更加逼近第一个Ac,如图1所示。第二个Ac是参数,当输入高分辨率图像时,第二部分被激活,fxc和高分辨率特征图的anchor都会被更新。如此,使低分率图特征更加逼近高分辨率特征,学习到更具有分辨性的特征。
targed reconstruction loss,其公式为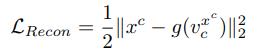 ,函数g()表示的是重建网络,即创新点1,因为认为高分辨图像和其对应的低分辨率图像的实例参数应该类似,所以提出了该损失函数,xc是类别为c的输入图像x,vcxc是对输入为xc的胶囊分类的第c类输出。在输入高分辨率图像时,xc处被替换为hrxc,表示对应的高分辨率输入图像。
,函数g()表示的是重建网络,即创新点1,因为认为高分辨图像和其对应的低分辨率图像的实例参数应该类似,所以提出了该损失函数,xc是类别为c的输入图像x,vcxc是对输入为xc的胶囊分类的第c类输出。在输入高分辨率图像时,xc处被替换为hrxc,表示对应的高分辨率输入图像。
补充
整个网络的损失函数为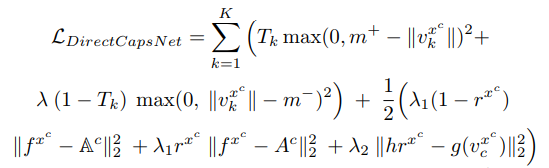 ,其中第一项是margin loss ,有论文有类似的用法,不再解释了,它的目的是增加类内的相似性,减少类间的相似性。K是总类别数。
,其中第一项是margin loss ,有论文有类似的用法,不再解释了,它的目的是增加类内的相似性,减少类间的相似性。K是总类别数。