前言
在安装
Spark之前,我们需要安装Scala语言的支持。在此我选择的是scala-2.11.12版本。jdk8也要保证已经安装好并且配置好环境变量
scala-2.11.12下载
为了方便,我先在我的hserver1主机上先安装,在scala官网下载scala-2.11.12.tgz并且上传到/root目录下,与我的Java目录相一致。
下载之后解压
tar -zxvf scala-2.11.12.tgz配置环境
在此需要打开/etc/profile文件进行配置
vim /etc/profile在文件的最后插入
export SCALA_HOME=/usr/scala-2.11.12
export PATH=$PATH:$SCALA_HOME/bin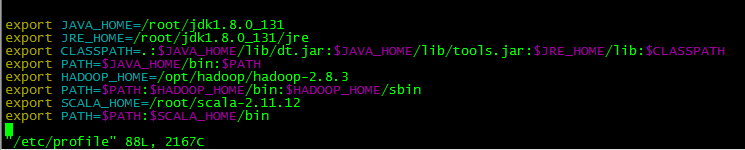
插入了之后要使得命令生效,需要的是:
source /etc/profile检测是否安装成功
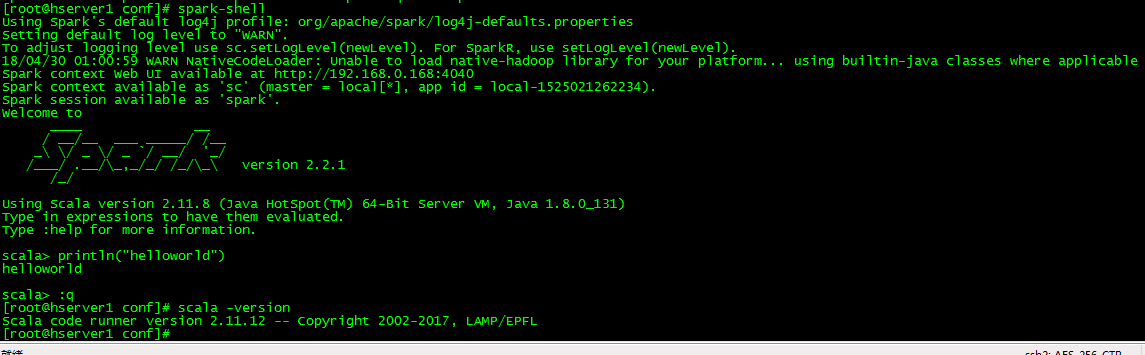
scala -version
配置其他Slave主机也安装scala
在此我用scp把scala-2.11.12.tgz传到另外两台hserver2和hserver3上完成另外两台机器的scala安装
Spark安装
把spark-2.2.1-bin-hadoop2.7.tgz上传到hserver1的root目录下并且tar -zxvf spark-2.2.1-bin-hadoop2.7.tgz 解压
修改/etc/profile
export SPARK_HOME=/opt/spark-2.2.1-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin
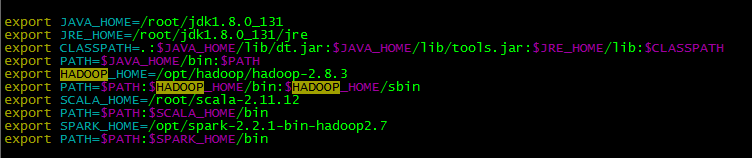
然后执行source /etc/profile
然后进入/root/spark-2.2.1-bin-hadoop2.7/conf
cp slaves.template slaves
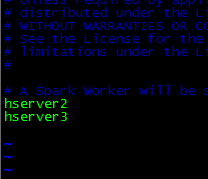
然后vim slaves加入两个从节点的host
hserver2
hserver3
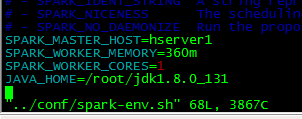
然后执行cp spark-env.sh.template spark-env.sh 并且修改这个文件
加入
SPARK_MASTER_HOST=hserver1
SPARK_WORKER_MEMORY=360m
SPARK_WORKER_CORES=1
JAVA_HOME=/root/jdk1.8.0_131
然后用scp把配置好的spark目录传到hserver2和hserver3从节点上
scp -r spark-2.2.1-bin-hadoop2.7 root@hserver2:/root
scp -r spark-2.2.1-bin-hadoop2.7 root@hserver3:/root
然后把hserver2和hserver3的/etc/profile修改成和hserver1一样
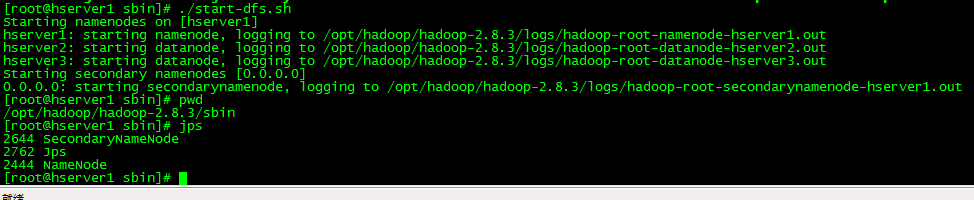
接下来先启动hdfs
进入/opt/hadoop/hadoop-2.8.3/sbin执行./start-dfs.sh
接下来进入/opt/spark-2.2.1-bin-hadoop2.7/sbin目录执行./start-all.sh启动spark

可以在hserver1看到Master进程在hserver2和hserver3看到Worker进程
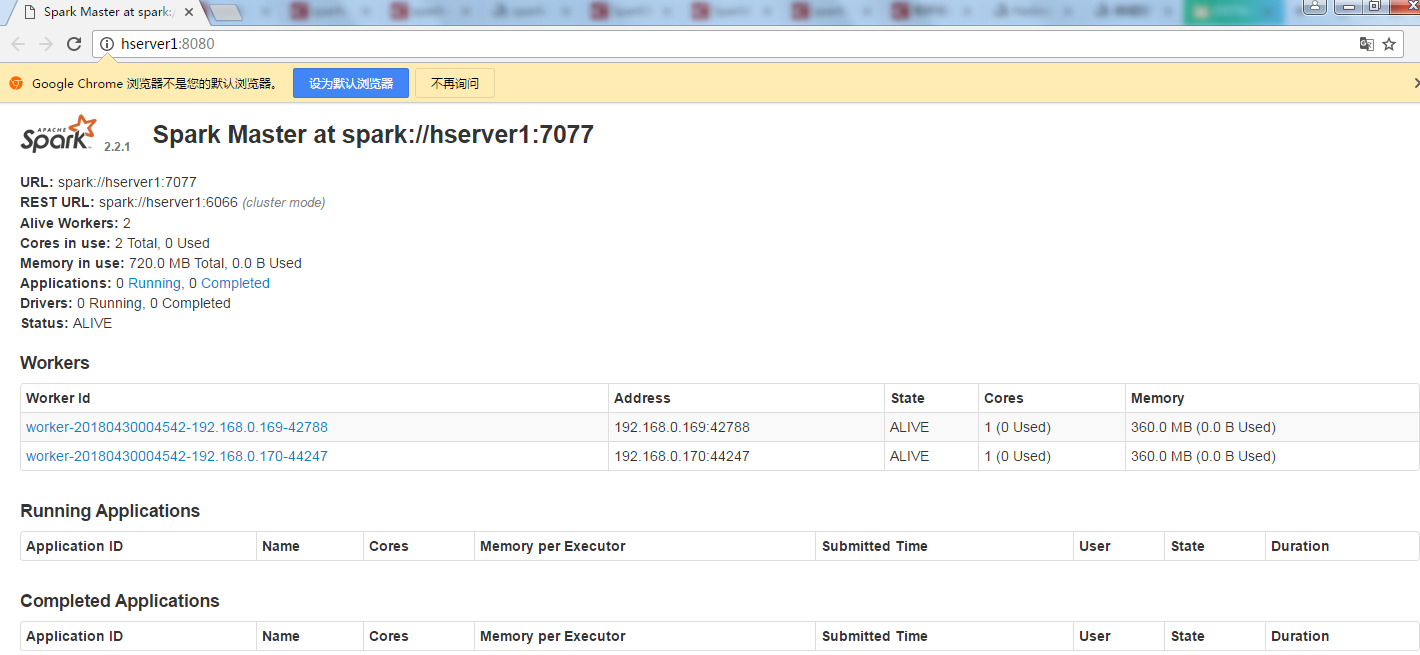
接下来访问hserver1:8080可以进入Spark的WebUI界面,可以看到2个Worker节点
还可以执行spark-shell