基本介绍
问题
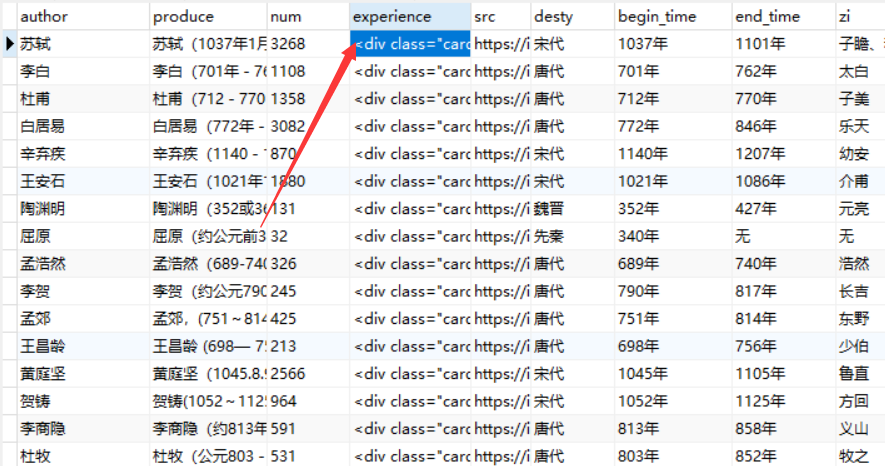
之前爬取诗人生平时,只爬取了对应的文字,导致在进行可视化时,缺少二级标题,导致无法进行有效的展示。
解决方案:从新爬取,这回将对应的格式也爬取下来
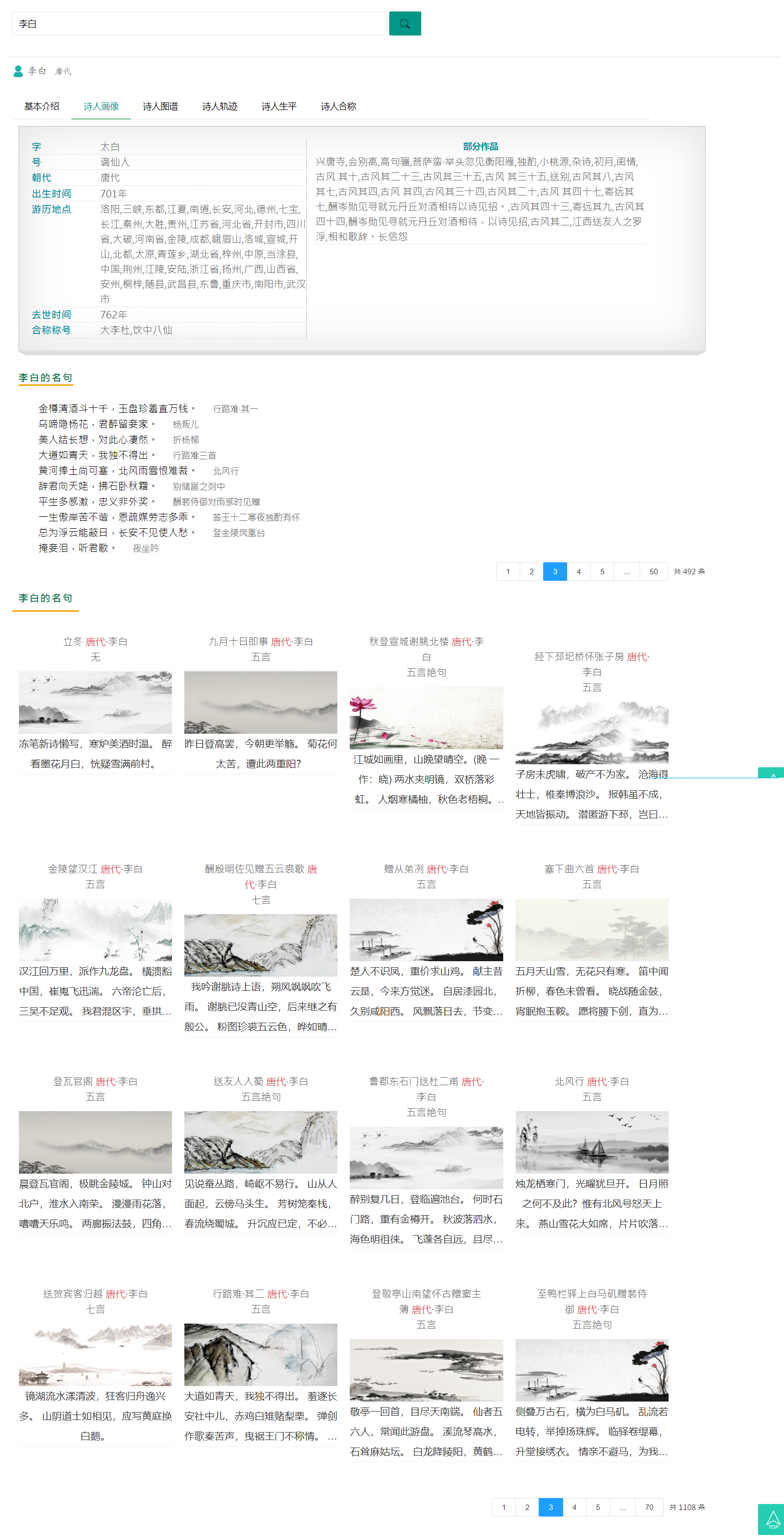
展示效果

诗人画像
名人名句
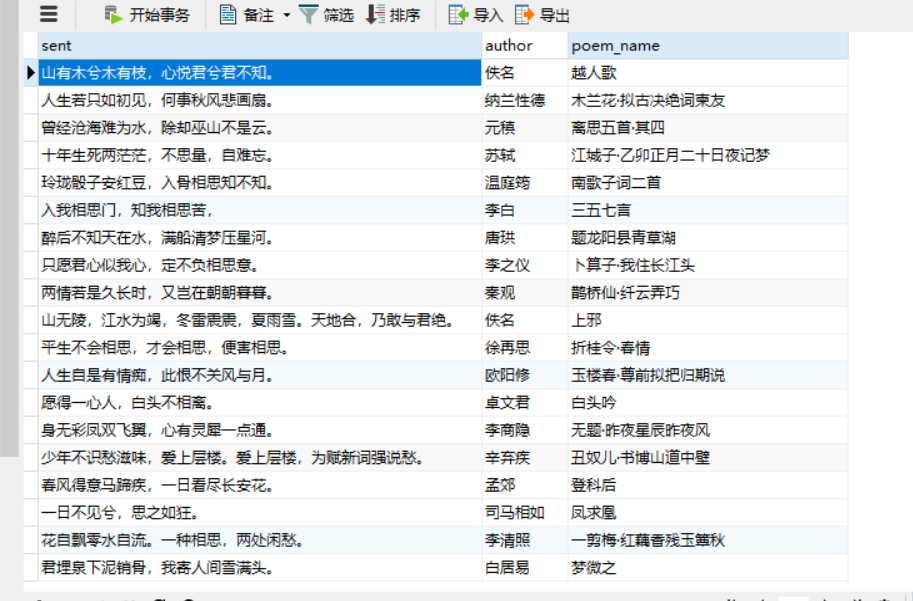
需要加载一个名人名句模块,之前未爬取,爬取对其进行补充
import requests
from bs4 import BeautifulSoup
from lxml import etree
import re
headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}#创建头部信息
pom_list=[]
k=1
#2010
for i in range(1,2010):
url='https://www.xungushici.com/authors/p-'+str(i)
r=requests.get(url,headers=headers)
content=r.content.decode('utf-8')
soup = BeautifulSoup(content, 'html.parser')
hed=soup.find('div',class_='col col-sm-12 col-lg-9')
list=hed.find_all('div',class_="card mt-3")
origin_url='https://www.xungushici.com'
for it in list:
content = {}
# 1.1获取单页所有诗集
title = it.find('h4', class_='card-title')
poemauthor=title.find_all('a')[1].text
#print(poemauthor)
href=title.find_all('a')[1]['href']
#对应的诗人个人详情页面
real_href = origin_url + href
#进入诗人详情页面
r2=requests.get(real_href,headers=headers)
content2=r2.content.decode('utf-8')
soup2 = BeautifulSoup(content2, 'html.parser')
ul=soup2.find('ul',class_='nav nav-tabs bg-primary')
if ul!=None:
list_li=ul.find_all('li',class_='nav-item')
exp = ""
for it in list_li:
if it.a.text=="人物生平" or it.a.text=="人物" or it.a.text=="生平":
urlsp=origin_url+it.a['href']
r3 = requests.get(urlsp, headers=headers)
content3 = r3.content.decode('utf-8')
soup3 = BeautifulSoup(content3, 'html.parser')
list_p=soup3.select('body > div.container > div > div.col.col-sm-12.col-lg-9 > div:nth-child(3) > div.card > div.card-body')
exp=str(list_p[0])
#print(exp)
#print(list_p[0])
# for it in list_p:
# exp=it.get_text().replace('\n','').replace('\t','').replace('\r','')
content['author']=poemauthor
content['experience'] = exp
pom_list.append(content)
else:
content['author'] = poemauthor
content['experience'] = "无"
pom_list.append(content)
print("第"+str(k)+"个")
k=k+1
import xlwt
xl = xlwt.Workbook()
# 调用对象的add_sheet方法
sheet1 = xl.add_sheet('sheet1', cell_overwrite_ok=True)
sheet1.write(0,0,"author")
sheet1.write(0,3,'experience')
for i in range(0,len(pom_list)):
sheet1.write(i+1,0,pom_list[i]['author'])
sheet1.write(i+1, 3, pom_list[i]['experience'])
xl.save("author_new.xlsx")
存储形式:
游历地点&合称称号
游历地点:通过neo4j数据库读取作者的事件节点,中所包含的地点信息,然后和标准的古今地名对照表进行对比,保留该表中包含的地名。
合称称号:也是基于neo4j数据库找寻作者的称号
部分作品:也是基于neo4j数据库找作者的30个作品,用作展示
def read_where():
data=pd.read_excel('static/data/gu_jin_lng_lat.xlsx')
gu_name=list(data.get('gu_name'))
return gu_name
def travel_poem(name):
gu_name=read_where()
data = graph.run(
'match data=(p:author{name:'+"'"+name+"'"+'})-[r:`事迹`]->(a:things) return a.where_name,a.date,a.name').data()
ans=[]
for it in data:
where_name = it.get('a.where_name')
date = it.get('a.date')
things_name = it.get('a.name')
where_list=str(where_name).split(',')
for it in where_list:
if it in gu_name:
ans.append(it)
print(date+" "+things_name+" "+it)
ans=list(set(ans))
ans=",".join(ans)
return ans
def common_name(name):
data = graph.run(
'match data=(p:author{name:'+"'"+name+"'"+'})-[r:`合称`]->(a:common_name) return a.name').data()
ans = []
for it in data:
name = it.get('a.name')
ans.append(name)
ans=",".join(ans)
return ans
def zuopin(name):
data = graph.run(
'match data=(p:author{name:' + "'" + name + "'" + '})-[r:`写作`]->(a:poem) return a.name limit 30').data()
ans = []
for it in data:
name = it.get('a.name')
ans.append(name)
ans = ",".join(ans)
print(ans)
return ans
展示效果