朝代年号标准化
朝代年号来源
代码
import requests
from bs4 import BeautifulSoup
from lxml import etree
import re
headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}#创建头部信息
url='http://www.360doc.com/content/15/0610/22/8378385_477251847.shtml'
r=requests.get(url,headers=headers)
content=r.content.decode('utf-8')
soup = BeautifulSoup(content, 'html.parser')
table=soup.find('table',class_='MsoNormalTable')
tr_list=table.tbody.find_all('tr')
desty_all=[]
for i in range(2,len(tr_list)):
tr=tr_list[i]
d_list=tr.find_all('p',class_='MsoNormal')
list=[]
for it in d_list:
text=str(it.text)
if bool(re.search(r'\d', str(it.text))) == True:
text=str(it.text).replace('\xa0','').replace('公元','').replace('年','')
list.append(text)
desty_all.append(list)
# print(desty_all)
#
import xlwt
xl = xlwt.Workbook()
# 调用对象的add_sheet方法
sheet1 = xl.add_sheet('sheet1', cell_overwrite_ok=True)
sheet1.write(0,0,"emperor")
sheet1.write(0,1,'year_hao')
sheet1.write(0,2,'time')
for i in range(0,len(desty_all)):
sheet1.write(i+1,0,desty_all[i][0])
sheet1.write(i+1, 1, desty_all[i][1])
sheet1.write(i + 1, 2, desty_all[i][2])
xl.save("qing_desty.xlsx")
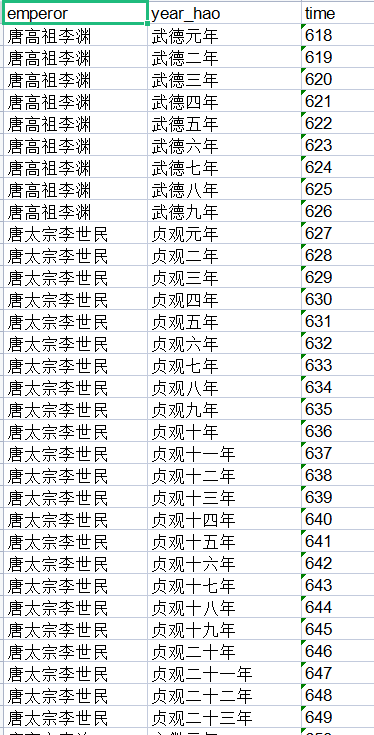
结果

诗词时间提取
设计提取手段

从这两个字段里提取出对应的时间关键词,优先从背景提取,背景中提取不到后在选择appear
采用pyhanlp里的rcf实体识别,找出包含的“数量词”,“时间词”,提出后还需要找到包含数字的时间词,作为本诗的作诗时间
代码
import re
from pyhanlp import *
import pandas as pd
#人名“nr“
#地名“ns”
#机构名“nt”
def demo_CRF_lexical_analyzer(text):
CRFnewSegment = HanLP.newSegment("crf")
term_list = CRFnewSegment.seg(text)
ans=[]
for it in term_list:
if str(it.nature)=='t' or str(it.nature)=='m':
ans.append(str(it.word))
print(ans)
return ans
from xlrd import open_workbook
from xlutils.copy import copy
#将分类结果重新写入原excel中
def write_to(data,file):
print(len(data))
xl =open_workbook(file)
excel = copy(xl)
sheet1 = excel.get_sheet(0)
sheet1.write(0, 9, "data")
for i in range(0, len(data)):
sheet1.write(i + 1, 9, data[i])
excel.save(file)
pome_time=[]
file='./data/tang.xlsx'
data=pd.read_excel(file).fillna("无")
appear=data.appear
back=data.background
for i in range(6000):
app=appear[i]
bk=back[i]
#print("===============欣赏===================")
app_time=demo_CRF_lexical_analyzer(app)
#print("===============背景===================")
bk_time=demo_CRF_lexical_analyzer(bk)
f=False
for it in bk_time:
if bool(re.search(r'\d', it)) == True:
print(it)
pome_time.append(it)
f=True
break
if f==False:
for it in app_time:
if bool(re.search(r'\d', it)) == True:
print(it)
pome_time.append(it)
f=True
break
if f==False:
print("无")
pome_time.append("无")
write_to(pome_time,file)
结果
