交叉熵
二次代价函数

原理

缺陷
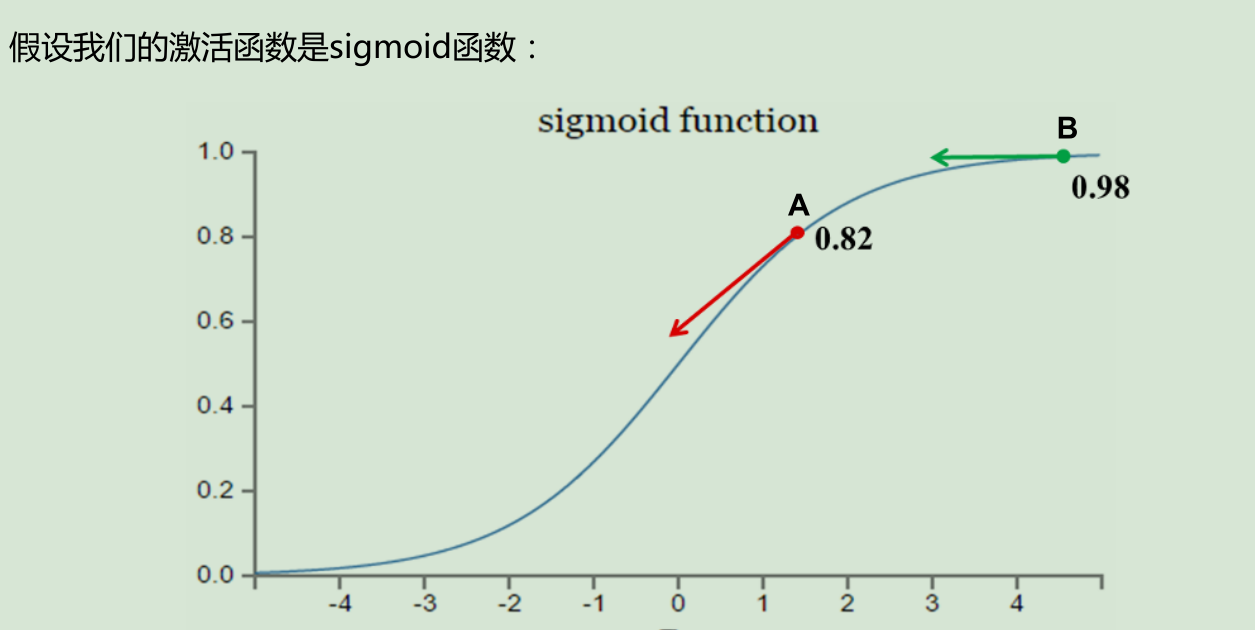
假如我们目标是收敛到0。A点为0.82离目标比较近,梯度比较大,权值调整比较大。B点为0.98离目标比较远,梯度比较小,权值调整比较小。调整方案不合理。
交叉熵代价函数(cross-entropy)
换一个思路,我们不改变激活函数,而是改变代价函数,改用交叉熵代价函数:

原理

用法

实战
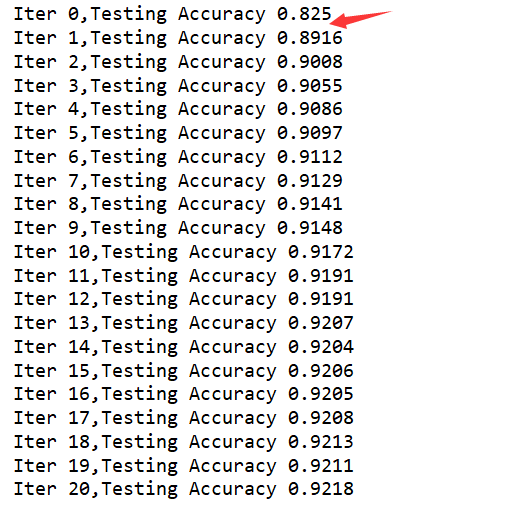
import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data tf.compat.v1.disable_eager_execution() import numpy as np #载入数据集 mnist=input_data.read_data_sets("MNIST_data",one_hot=True) #每个批次大小 batch_size=100 #计算一共有多少个批次 n_bath=mnist.train.num_examples // batch_size print(n_bath) #定义两个placeholder x=tf.compat.v1.placeholder(tf.float32,[None,784]) y=tf.compat.v1.placeholder(tf.float32,[None,10]) #创建一个简单的神经网络 W=tf.Variable(tf.zeros([784,10])) b=tf.Variable(tf.zeros([10])) prediction=tf.nn.softmax(tf.matmul(x,W)+b) #交叉熵函数 loss=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y,logits=prediction)) #梯度下降 train_step=tf.compat.v1.train.GradientDescentOptimizer(0.2).minimize(loss) #初始化变量 init=tf.compat.v1.global_variables_initializer() #结果存放在一个布尔型列表中 #返回的是一系列的True或False argmax返回一维张量中最大的值所在的位置,对比两个最大位置是否一致 correct_prediction=tf.equal(tf.argmax(y,1),tf.argmax(prediction,1)) #求准确率 #cast:将布尔类型转换为float,将True为1.0,False为0,然后求平均值 accuracy=tf.reduce_mean(tf.cast(correct_prediction,tf.float32)) with tf.compat.v1.Session() as sess: sess.run(init) for epoch in range(21): for batch in range(n_bath): #获得一批次的数据,batch_xs为图片,batch_ys为图片标签 batch_xs,batch_ys=mnist.train.next_batch(batch_size) #进行训练 sess.run(train_step,feed_dict={x:batch_xs,y:batch_ys}) #训练完一遍后,测试下准确率的变化 acc=sess.run(accuracy,feed_dict={x:mnist.test.images,y:mnist.test.labels}) print("Iter "+str(epoch)+",Testing Accuracy "+str(acc))
输出:明显可以看到有了巨大的变化
拟合

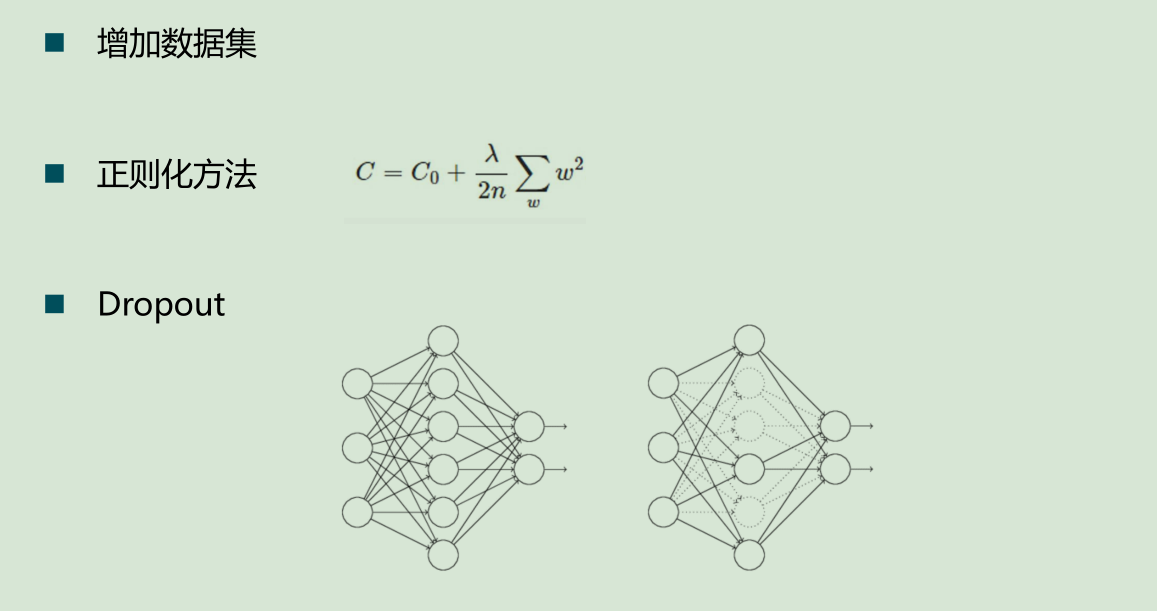
防止过拟合
代码
import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data tf.compat.v1.disable_eager_execution() import numpy as np #载入数据集 mnist=input_data.read_data_sets("MNIST_data",one_hot=True) # 批次的大小 batch_size = 128 n_batch = mnist.train.num_examples // batch_size x = tf.compat.v1.placeholder(tf.float32, [None,784]) y = tf.compat.v1.placeholder(tf.float32, [None, 10]) keep_prob = tf.compat.v1.placeholder(tf.float32) # 创建神经网络 W1 = tf.Variable(tf.compat.v1.truncated_normal([784,2000],stddev=0.1)) b1 = tf.Variable(tf.zeros([1, 2000])) # 激活层 layer1 = tf.nn.relu(tf.matmul(x,W1) + b1) # drop层 layer1 = tf.nn.dropout(layer1,keep_prob) # 第二层 W2 = tf.Variable(tf.compat.v1.truncated_normal([2000,500],stddev=0.1)) b2 = tf.Variable(tf.zeros([1, 500])) layer2 = tf.nn.relu(tf.matmul(layer1,W2) + b2) layer2 = tf.nn.dropout(layer2,keep_prob) # 第三层 W3 = tf.Variable(tf.compat.v1.truncated_normal([500,10],stddev=0.1)) b3 = tf.Variable(tf.zeros([1,10])) prediction = tf.nn.sigmoid(tf.matmul(layer2,W3) + b3) loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y, logits=prediction)) # 梯度下降法 # train_step = tf.train.GradientDescentOptimizer(0.2).minimize(loss)#得到97的正确率 train_step = tf.compat.v1.train.AdadeltaOptimizer(0.1).minimize(loss) # 初始化变量 init = tf.compat.v1.global_variables_initializer() prediction_2 = tf.nn.softmax(prediction) # 得到一个布尔型列表,存放结果是否正确 correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(prediction_2,1)) #argmax 返回一维张量中最大值索引 # 求准确率 accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32)) # 把布尔值转换为浮点型求平均数 with tf.compat.v1.Session() as sess: sess.run(init) for epoch in range(100): for batch in range(n_batch): # 获得批次数据 batch_xs, batch_ys = mnist.train.next_batch(batch_size) sess.run(train_step, feed_dict={x:batch_xs, y:batch_ys, keep_prob:0.8}) test_acc = sess.run(accuracy, feed_dict={x:mnist.test.images,y:mnist.test.labels,keep_prob:1.0} ) train_acc = sess.run(accuracy, feed_dict={x: mnist.train.images, y: mnist.train.labels, keep_prob: 1.0}) print("Iter " + str(epoch) + ",Testing Accuracy " + str(test_acc) + ",Train Accuracy " + str(train_acc))