简介
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。 它支持多种类型的数据结构,如 字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets)。为单进程, 单线程。
安装
$ wget http://download.redis.io/releases/redis-6.0.6.tar.gz
$ tar xzf redis-6.0.6.tar.gz
$ cd redis-6.0.6
$ make
若make报错,则执行下列命令
1、安装gcc套装:
yum install cpp
yum install binutils
yum install glibc
yum install glibc-kernheaders
yum install glibc-common
yum install glibc-devel
yum install gcc
yum install make
2、升级gcc
yum -y install centos-release-scl
yum -y install devtoolset-9-gcc devtoolset-9-gcc-c++ devtoolset-9-binutils
scl enable devtoolset-9 bash
3、设置永久升级:
echo "source /opt/rh/devtoolset-9/enable" >>/etc/profile
将redis安装为快捷启动服务
make install PREFIX=/opt/software/redis: 将redis的可执行文件迁出到固定的目录,和二进制文件分开
vi /etc/profile: 进入profile文件,进行配置下列环境变量
export REDIS_HOME=/opt/software/redis
export PATH=$PATH:$REDIS_HOME/bin
source /etc/profile:让修改后的配置文件生效
cd utils进入redis的utils目录
./install_server.sh 执行.sh文件,生成一些可执行命令,若报错,参考如下博客
https://www.cnblogs.com/strive-for-life/p/13194306.html
其他命令
service redis_6379 start/stop/status redis启动/停止/状态,
ps -fe|grep redis 查看redis状态
主从复制
- 简介
Redis使用默认的异步复制,其特点是低延迟和高性能,是绝大多数 Redis 用例的自然复制模式。但是,从 Redis 服务器会异步地确认其从主 Redis 服务器周期接收到的数据量。
参考文档 http://redis.cn/topics/replication.html
https://blog.csdn.net/u014691098/article/details/82391608
- 主服务器配置
- 注释bind(本例是注释,即所有ip都能连接)

- 启动
service redis_6379 start
- 注释bind(本例是注释,即所有ip都能连接)
- 从服务器配置(第一行是指定主服务器IP和端口号,第二行是指定从服务器只读)
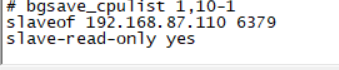
- 启动
service redis_6380 start
配置完毕
参考 https://blog.csdn.net/u014691098/article/details/82391608
哨兵
- 主服务器配置
无,不需要配置 - 从服务器配置
无,不需要配置 - 哨兵配置
vi 16379.conf:创建一个16379端口号的哨兵配置文件,并配置下列内容
port 16379
#指定该配置时一个哨兵 无 主机名字 主机ip 主机端口号 2个哨兵同时投票主机挂掉,则进行主从转移
sentinel monitor mymaster 127.0.0.1 6379 2
- 启动哨兵
redis-server ./16379.conf --sentinel启动16379端口号的哨兵 - 同理,配置16380,16381哨兵
有点问题,等一段时间再看
五种Value基本数据类型
- String
字符串,若是数字,可做加减乘除 - List
List集合 - hash
Map集合 - Set
set集合,去重,无序。 - sorted_set
set集合,去重,有序。
常用命令
redis-cli -p 6379 shutdown: 关闭6379端口号redis,
redis-cli -p 端口号: 进入对应端口号的操作界面,
exit: 退出redis的操作界面,
help @string: 查看字符串常用命令,
help @list: 查看List集合常用命令,
help @set: 查看set集合常用命令,
help @sorted_set:查看set有序集合常用命令,
FLUSHALL: 清除所有key,
ttl 'keyName': 查询key剩余有效期,返回 -2表示这个key已过期,已不存在;返回-1,表示这个key没有设置有效期;返回0以上的值,表示是这个key的剩余有效时间,
keys *:查询所有key值,
help @hash: 查看Map集合常用命令。
RDB和AOF
RDB
- 简介
RDB持久化方式能够在指定的时间间隔能对你的数据进行快照存储。 - 配置
#15分钟内改变1次
save 900 1
#5分钟内改变10次
save 300 10
#15分钟内改变一次
save 900 1
#快照采取rdb方式
dbfilename dump.rdb
#快照存放位置
dir /var/lib/redis/6379
- 优点
- RDB是一个紧凑的单一文件,很方便传送到另一个远端数据中心;
- RDB在保存RDB文件时父进程唯一需要做的就是fork出一个子进程,接下来的工作全部由子进程来做,父进程不需要再做其他IO操作,所以RDB持久化方式可以最大化redis的性能;
- 与AOF相比,在恢复大的数据集的时候,RDB方式会更快一些。
- 缺点
- 突然redis停止工作,会导致数据丢失;
- RDB 需要经常fork子进程来保存数据集到硬盘上,当数据集比较大的时候,fork的过程是非常耗时的,可能会导致Redis在一些毫秒级内不能响应客户端的请求。
AOF
-
简介
AOF持久化方式记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据,AOF命令以redis协议追加保存每次写的操作到文件末尾.Redis还能对AOF文件进行后台重写,使得AOF文件的体积不至于过大。 -
配置

-
优点
- 使用不同的fsync策略,可以让redis突然停止工作时,最多丢失1秒数据;
- AOF 文件有序地保存了对数据库执行的所有写入操作, 这些写入操作以 Redis 协议的格式保存, 因此 AOF 文件的内容非常容易被人读懂, 对文件进行分析(parse)也很轻松。 即不小心执行了 FLUSHALL 命令, 但只要 AOF 文件未被重写, 那么只要停止服务器, 移除 AOF 文件末尾的 FLUSHALL 命令, 并重启 Redis , 就可以将数据集恢复到 FLUSHALL 执行之前的状态。
-
缺点
- 对于相同的数据集来说,AOF 文件的体积通常要大于 RDB 文件的体积。
- 根据所使用的 fsync 策略,AOF 的速度可能会慢于 RDB 。 在一般情况下, 每秒 fsync 的性能依然非常高, 而关闭 fsync 可以让 AOF 的速度和 RDB 一样快, 即使在高负荷之下也是如此。 不过在处理巨大的写入载入时,RDB 可以提供更有保证的最大延迟时间(latency)。
-
日志重写
AOF可以在不打断服务客户端的情况下, 对 AOF 文件进行重建(rebuild)。执行 BGREWRITEAOF 命令, Redis 将生成一个新的 AOF 文件, 这个文件包含重建当前数据集所需的最少命令。
总结
目前,redis6版本中默认快照为rdb方式,而且AOF在日志重写过程中,先采用rdb方式进行存储,最后再采用日志命令追加方式进行持久化存储。
常见基本问题
Redis的内存淘汰策略
Redis的过期键的删除策略
使用EXPIRE和PERSIST命令分别设置Redis key的过期时间和永久有效。
- 定时过期
每个设置过期时间的key都需要创建一个定时器,到过期时间就会立即清除。该策略可以立即清除过期的数据,对内存很友好;但是会占用大量的CPU资源去处理过期的数据,从而影响缓存的响应时间和吞吐量。 - 惰性过期
只有当访问一个key时,才会判断该key是否已过期,过期则清除。该策略可以 大化地节省CPU资源,却对内存非常不友好。极端情况可能出现大量的过期key没有再次被访问,从而不会被清除,占用大量内存。 - 定期过期
每隔一定的时间,会扫描一定数量的数据库的expires字典中一定数量的key,并清除其中已过期的key。该策略是前两者的一个折中方案。通过调整定时扫描的时间间隔和每次扫描的限定耗时,可以在不同情况下使得CPU和内存资源达到 优的平衡效果。
(expires字典会保存所有设置了过期时间的key的过期时间数据,其中,key是指向键空间中的某个键的指针,value是该键的毫秒精度的UNIX时间戳表示的过期时间。键空间是指该Redis集群中保存的所有键。)
Redis中同时使用了惰性过期和定期过期两种过期策略。
Redis的内存淘汰策略
Redis的内存淘汰策略是指在Redis的用于缓存的内存不足时,怎么处理需要新写入且需要申请额外空间的数据。
- 全局的键空间选择性移除
- noeviction
当内存不足以容纳新写入数据时,新写入操作会报错。 - allkeys-lfu
当内存不足以容纳新写入数据时,在键空间中,移除近期少使用的key。(这个是最常用的) - allkeys-random
当内存不足以容纳新写入数据时,在键空间中,随机移除某个key。 - allkeys-lru
加入键的时候,如果过限,首先通过LRU算法驱逐最久没有使用的键。
- noeviction
- 设置过期时间的键空间选择性移除
- volatile-lfu
当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除近期少使用的key。 - volatile-random
当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key。 - volatile-ttl
当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除。 - volatile-lru
加入键的时候如果过限,首先从设置了过期时间的键集合中驱逐最久没有使用的键。
- volatile-lfu
击穿
- 简介
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力。和缓存雪崩不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。 - 解决方案
- 设置热点数据永远不过期。
- 加互斥锁,即先让一条命令去执行,其余查询缓存(可通过加锁等方案实现)
穿透
- 简介
缓存穿透是指缓存和数据库中都没有的数据,导致所有的请求都落到数据库上,造成数据库短时间内承受大量请求而崩掉。 - 解决方案
- 接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截;
- 从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)。这样可以防止攻击用户反复用同一个id暴力攻击;
- 采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的 bitmap 中,一个一定不存在的数据会被这个 bitmap 拦截掉,从而避免了对底层存储系统的查询压力。
雪崩
- 简介
缓存雪崩是指缓存同一时间大面积的失效,所以,后面的请求都会落到数据库上,造成数据库短时间内承受大量请求而崩掉。 - 解决方案
- 缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
- 一般并发量不是特别多的时候,使用最多的解决方案是加锁排队。
- 给每一个缓存数据增加相应的缓存标记,记录缓存的是否失效,如果缓存标记失效,则更新数据缓存。