1. 爬取内容
爬取网页内容,实际也是通过定位元素,然后获取元素内容
例如,爬取下图表格中的元素内容(tr为行,td为列)
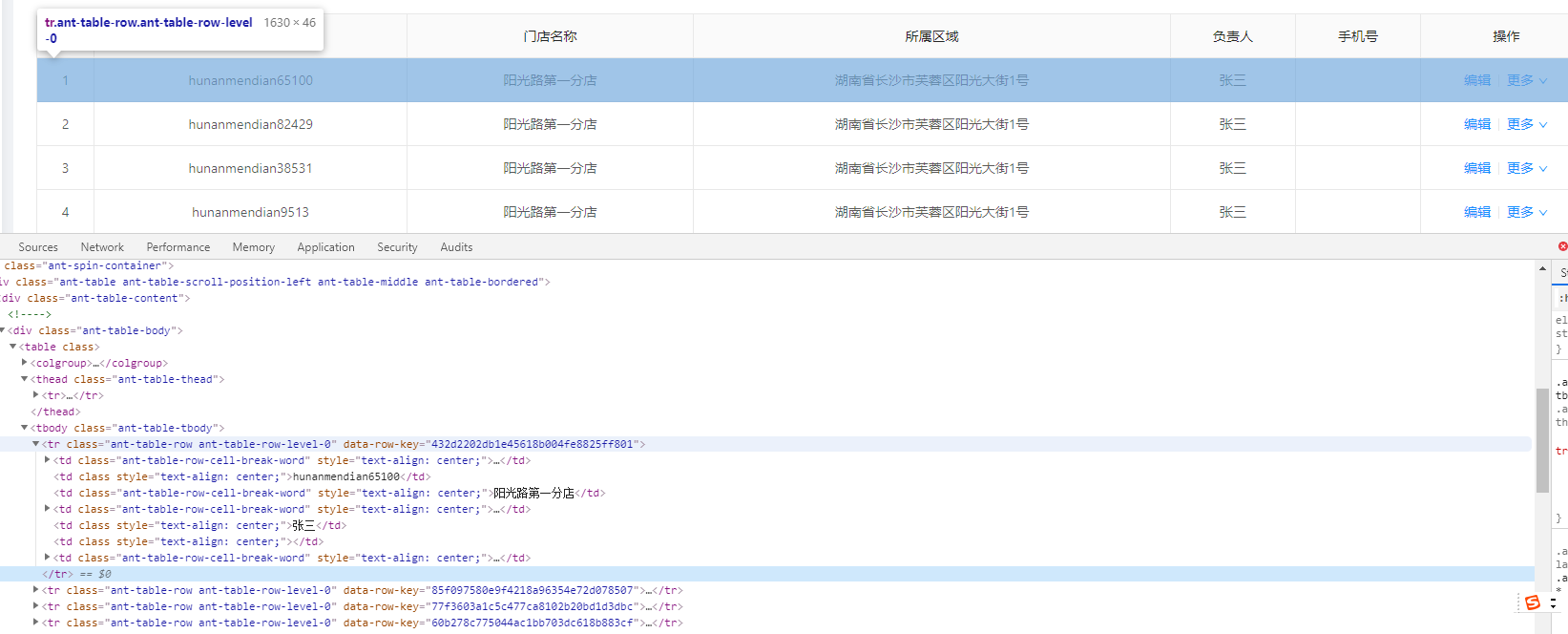
代码如下:
两层循环,一层行,一层列
1 def test_1_table(self): 2 jobs = self.driver.find_elements_by_class_name('ant-table-row.ant-table-row-level-0') # 每行tr 3 for job in jobs: 4 fields = job.find_elements_by_tag_name('td') # 每行里的字段td 5 for field in fields: 6 stringFields = field.text 7 print(stringFields, end='|') 8 print('')
打印出来如下:
1|hunanmendian65100|阳光路第一分店|湖南省长沙市芙蓉区阳光大街1号|张三||编辑更多|
2|hunanmendian82429|阳光路第一分店|湖南省长沙市芙蓉区阳光大街1号|张三||编辑更多|
3|hunanmendian38531|阳光路第一分店|湖南省长沙市芙蓉区阳光大街1号|张三||编辑更多|
4|hunanmendian9513|阳光路第一分店|湖南省长沙市芙蓉区阳光大街1号|张三||编辑更多|
5|hunanmendian87041|阳光路第一分店|湖南省长沙市芙蓉区阳光大街1号|张三||编辑更多|
6|hunanmendian89772|阳光路第一分店|湖南省长沙市芙蓉区阳光大街1号|张三||编辑更多|
7|hunanmendian38121|阳光路第一分店|湖南省长沙市芙蓉区阳光大街1号|张三||编辑更多|
8|hunanmendian2432|阳光路第一分店|湖南省长沙市芙蓉区阳光大街1号|张三||编辑更多|
9|hunanmendian22671|阳光路第一分店|湖南省长沙市芙蓉区阳光大街1号|张三||编辑更多|
10|hunanmendian63588|阳光路第一分店|湖南省长沙市芙蓉区阳光大街1号|张三||编辑更多|
2. 写入文件
将爬取的内容,存储到文件中:
1 def test_1_table(self): 2 jobs = self.driver.find_elements_by_class_name('ant-table-row.ant-table-row-level-0') # 每行tr 3 book = xlwt.Workbook() 4 sh = book.add_sheet('123') 5 6 row = 0 7 for job in jobs: 8 fields = job.find_elements_by_tag_name('td') # 每行里的字段td 9 col = 0 10 for field in fields: 11 stringFields = field.text 12 print(stringFields, end='|') 13 sh.write(row, col, stringFields) 14 col += 1 15 16 print('') 17 row += 1 18 19 book.save('44.xls')
保存后的文件如下:
