TCP/IP 五层模型:
应用层:HTTPFTPSMTPTELNETPOP3
传输层:TCP传输控制协议UDP用户数据报协议
网络层:路由器(IP互联网协议)
数据链路层:网桥、交换机(ARP地址解析协议)
物理层:网卡、网线、集线器、中继器、调制解调器
常用缩写:
HTTP 超文本传输协议 HyperText Transfer Protocol
HTML 超文本标记语言 HyperText Markup Language
URL 统一资源定位符 Uniform Resource Locator
HTTP简介
HTTP是从万维网(WWW:World Wide Web)服务器传输超文本到本地浏览器的传送协议,面向应用层,基于TCP/IP通信协议来传输数据。HTTP协议工作于客户端-服务端架构上。客户端(浏览器)通过URL向服务端(WEB服务器)发送请求
浏览器中输入URL后,浏览器给Web服务器发送了一个Request, Web服务器接到Request后进行处理,生成相应的Response,然后发送给浏览器, 浏览器解析Response中的HTML,这样我们就看到了网页
往往打开一个网页需要浏览器发送很多次request,过程如下:
1. 当你在浏览器输入URL http://www.cnblogs.com 的时候,浏览器发送一个Request去获取 http://www.cnblogs.com 的html. 服务器把Response发送回给浏览器.
2. 浏览器分析Response中的 HTML,发现其中引用了很多其他文件,比如图片,CSS文件,JS文件。
3. 浏览器会自动再次发送Request去获取图片,CSS文件,或者JS文件。
4. 等所有的文件都下载成功后。 网页就被显示出来了
主要特点:
1、简单,通信速度快;常用方法:get、post、head等
2、http允许传输任意类型的数据对象,正在传输的类型由content-type加以标记
3、无连接:每次连接只处理一个请求
4、无状态:对于事物处理没有记忆能力,各请求间数据没有关联性
5、支持B/S,C/S
无连接、无状态
- 无连接:限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。
优点:节省传输时间
缺点:多个请求需要多次建立连接
- 无状态:指协议对于事务处理没有记忆能力;同一个客户端的这次请求和上次请求是没有对应关系;服务器中没有保存客户端的状态,对http服务器来说,它并不知道这两个请求来自同一个客户端
缺点:客户端必须每次带上自己的状态去请求服务器,请求开销大
短连接和长连接(keep-alive解决多次建立连接问题)
HTTP不是字面意义上的没有连接,HTTP真正的连接,是通过传输层的TCP协议实现的,所有的操作均在可靠的连接基础之上。
1、HTTP/0.9:最早发布的1991年0.9版,该时期的HTTP协议十分简单,只支持Get请求,采用短连接的方式,也就是说,客户端和服务器每进行一次HTTP操作,就建立一次连接,任务结束就中断连接。当客户端浏览器访问的某个HTML或其他类型的Web页中包含有其他的Web资源(如JavaScript文件、图像文件、CSS文件等),每遇到这样一个Web资源,浏览器就会重新建立一个HTTP会话。
2、HTTP/1.0:1996年发布,默认使用短连接,提出长连接(也叫持久连接)的概念,但当时仅提供初步的支持。
3、HTTP/1.1:1999年发布,默认使用长连接,用以保持连接特性。使用长连接的HTTP协议,会在响应头加入这行代码:Connection:keep-alive。在使用长连接的情况下,当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的TCP连接不会关闭,客户端再次访问这个服务器时,会继续使用这一条已经建立的连接。Keep-Alive不会永久保持连接,它有一个保持时间,可以在不同的服务器软件(如Apache)中设定这个时间。实现长连接需要客户端和服务端都支持长连接。HTTP协议的长连接和短连接,实质上是TCP协议的长连接和短连接。
cookie、session、token(解决无状态问题)
cookie:
1. cookie是一门客户端缓存技术
2. cookie数据由服务器生成,发送给浏览器保存
3. cookie数据的格式:键值对
4. cookie数据过期机制:设置expire值
5. 每一个cookie都会有名称,值,过期时间...。cookie有很多使用场景,在项目中比较常见的有:
1.登录记住用户名
2.记录用户浏览记录
...
上面应用中大家最熟悉的应该就是记住用户名这个场景了,以京东网站的登录功能为例,当我们登录了一次京东,后面再去登录页面登录的时候,会发现它会帮你回填之前的用户名,这个场景就是通过cookie技术实现的
session:
1. session是一门服务端会话缓存技术。
2. session由服务器端的web容器创建,保存在服务器端。
3. session保存数据:键值对形式
4. session过期:默认30分钟
5. session是服务端的会话技术,当用户登录了系统,服务器端的web容器就会创建一个会话,此会话中可以保存登录用户的信息
6. session过期:当服务器端的会话过期了,那么当你继续发起请求的时候,因为你从客户端带过去的会话编号还是之前的那个,就会验证不通过,就会提示你会话过期请重新登录。
token:
一般app项目都会基于一个token做鉴权。因为此时客户端不是浏览器,因此就没有cookie这一说了。
当用户登录app时,服务器会响应回来一个token信息(一般都是返回的一串唯一的标识符,比如说uuid或其他)。服务器端会将登录用户跟token(票据)保存一个映射关系,一般保存在redis或者表里面,服务器端响应回来的token会缓存在手机的本地缓存里,后面手机去访问app的其他页面,就会带着这个token去服务器做验证,如果通过这个token能够从redis找到登录用户信息,那么就认为你是已经登录了的用户。
token失效:一段时间后,服务器端的token失效了,那么就会把此token跟用户的映射关系从redis里删掉,那么后面再来访问的时候,根据你手机请求带来的token就匹配不上登录用户了,服务器就告诉客户端,需要去做重新登录了
cookie示例
1. 请求登录接口
服务器在response头中,设置了cookie
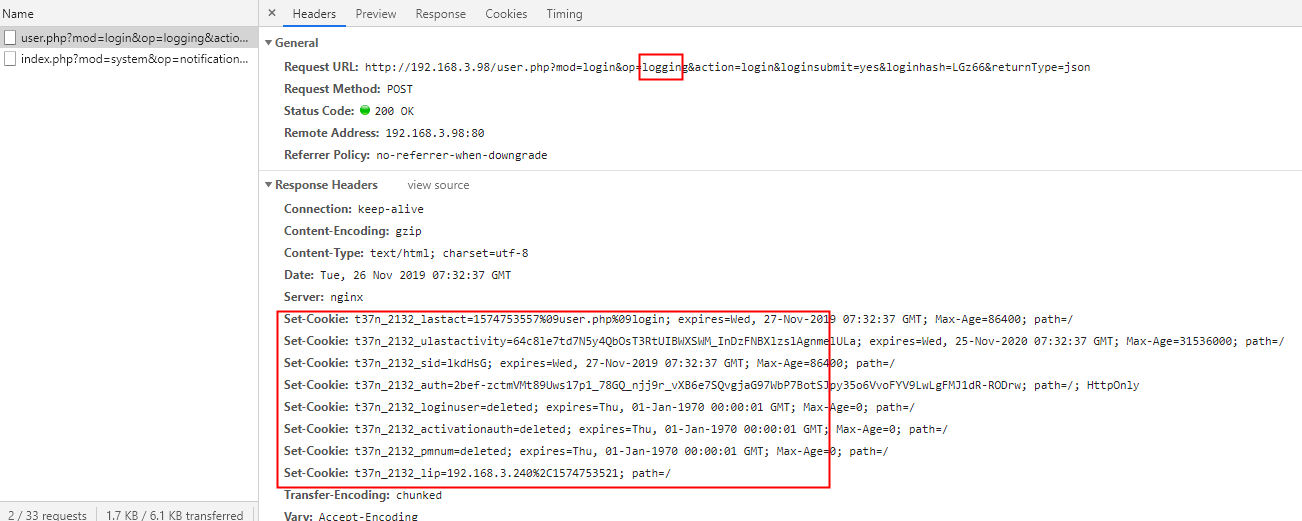
2. 在浏览器查看cookie
设置 -》 隐私设置和安全性 -》网站设置 -》cookie和网站数据 -》查看所有cookie和网站数据

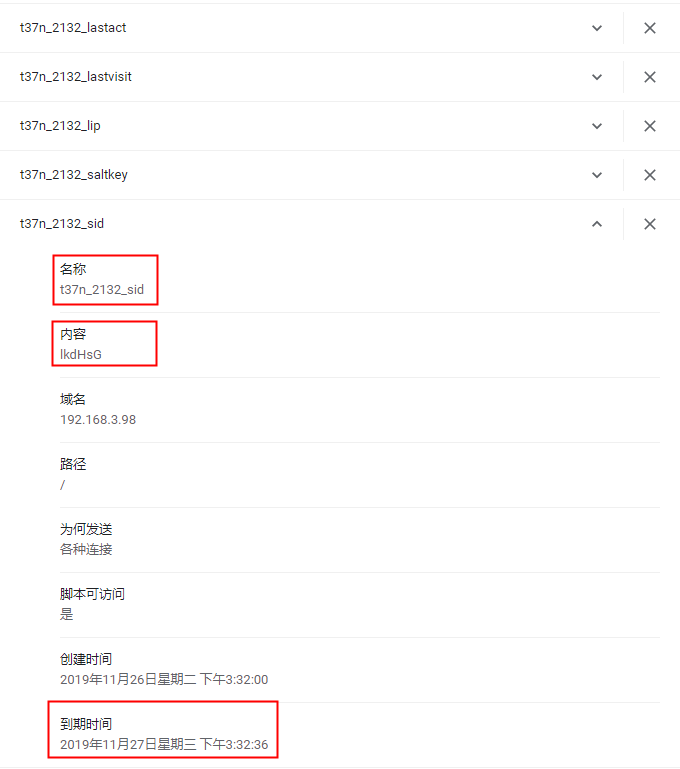
浏览器的F12中,application中也可以查看cookie信息

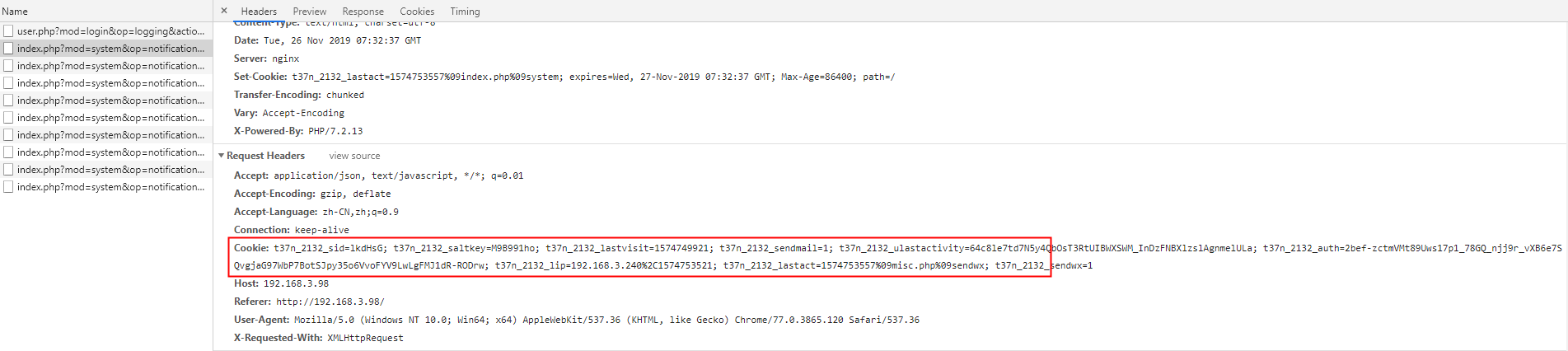
3. 再次发起请求
发现不需要重新登录,请求头中携带了cookie信息
URL详解
URL:统一资源定位符,用于描述一个网络上的资源,基本格式如下:
schema://host[:port#]/path/.../[?query-string][#anchor]
scheme 使用的协议(例如:http, https, ftp)
host 服务器的IP地址或者域名
port 服务器的默认端口是80可以省略。如果使用了别的端口,必须指明
path 访问资源的路径
query-string 发送给服务器的数据(从“?”开始到“#”为止之间的部分为参数部分,参数可以允许有多个参数,参数与参数之间用“&”作为分隔符)
anchor 锚,指页面的指定位置。抓包工具中,无法在Http请求中找到井号后面的参数,原因是井号后面的参数是针对浏览器起作用的而不是服务器端。
例子:
http://www.mywebsite.com/sj/test/test.aspx?name=sviergn&x=true#stuff Schema: http host: www.mywebsite.com path: /sj/test/test.aspx Query String: name=sviergn&x=true Anchor: stuff
HTTP消息的结构
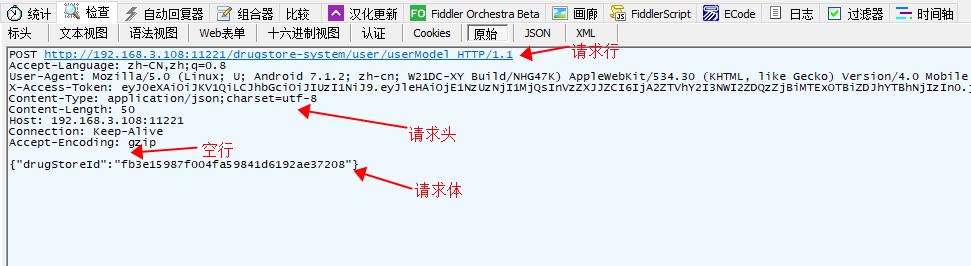
1. 请求消息
请求消息包括:请求行(request line)、请求头(header)、空行、请求数据(body)四部分
注:
a) 请求方法为get时,请求体body为空
b) 请求头后面是空行,通知服务器请求头结束
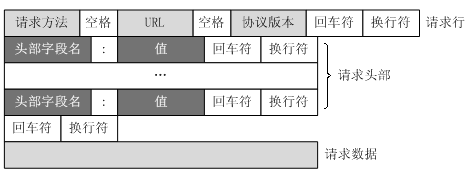
例子:(fiddler中的raw方式可以看到完整信息)
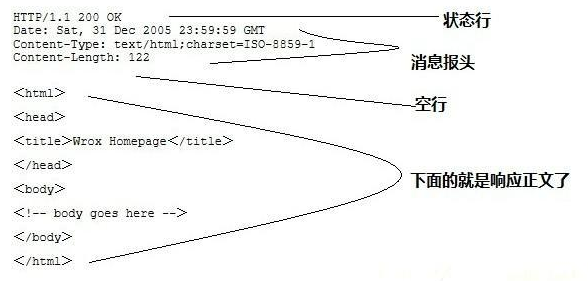
2. 响应消息
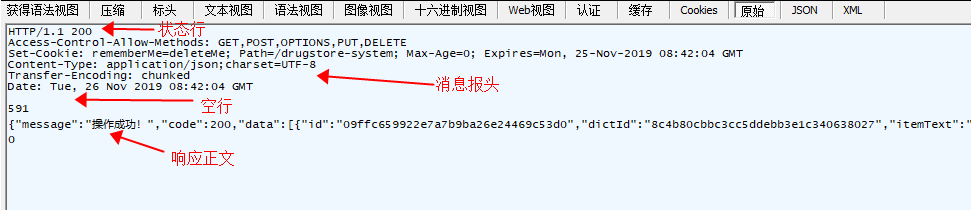
响应消息包括:状态行、消息报头、空行、响应正文四部
例子:
状态码
Response 消息中的第一行叫做状态行,由HTTP协议版本号, 状态码, 状态消息 三部分组成。
状态码用来告诉HTTP客户端,HTTP服务器是否产生了预期的Response.
HTTP/1.1中定义了5类状态码, 状态码由三位数字组成,第一个数字定义了响应的类别
1XX 提示信息 - 表示请求已被成功接收,继续处理
2XX 成功 - 表示请求已被成功接收,理解,接受
3XX 重定向 - 要完成请求必须进行更进一步的处理
4XX 客户端错误 - 请求有语法错误或请求无法实现
5XX 服务器端错误 - 服务器未能实现合法的请求
常见状态码:
200:成功响应。该请求被成功地完成,所请求的资源发送回客户端
302:重定向,新的URL会在response的Location中返回,浏览器将会自动使用新的URL发出新的Request
304:Not Modified,代表上次的文档已经被缓存了, 还可以继续使用(如果你不想使用本地缓存可以用Ctrl+F5 强制刷新页面)
400:Bad Request 客户端请求与语法错误,不能被服务器所理解
403:Forbidden 服务器收到请求,但是拒绝提供服务
404:Not Found 请求资源不存在(输错了URL)比如在IE中输入一个错误的URL
500:Internal Server Error 服务器发生了不可预期的错误
503:Server Unavailable 服务器当前不能处理客户端的请求,一段时间后可能恢复正常
post、get的区别
Http协议定义了很多与服务器交互的方法,最基本的有4种,分别是GET,POST,PUT,DELETE. 一个URL地址用于描述一个网络上的资源,而HTTP中的GET, POST, PUT, DELETE就对应着对这个资源的查,改,增,删4个操作。 我们最常见的就是GET和POST了。GET一般用于获取/查询资源信息,而POST一般用于更新资源信息.
区别:
1. GET提交的数据会放在URL之后,以?分割URL和传输数据,参数之间以&相连,如EditPosts.aspx?name=test1&id=123456. POST方法是把提交的数据放在HTTP包的Body中.
2. GET提交的数据大小有限制(因为浏览器对URL的长度有限制),而POST方法提交的数据没有限制.
3. GET方式需要使用Request.QueryString来取得变量的值,而POST方式通过Request.Form来获取变量的值。
4. GET方式提交数据,会带来安全问题,比如一个登录页面,通过GET方式提交数据时,用户名和密码将出现在URL上,如果页面可以被缓存或者其他人可以访问这台机器,就可以从历史记录获得该用户的账号和密码.