Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。
框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
Scrapy 使用了 Twisted异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
一 Scrapy框架流程图

(1) 组件描述
Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
(2) 数据流描述
- 引擎打开一个网站(open a domain),找到处理该网站的Spider并向该spider请求第一个要爬取的URL(s)。
- 引擎从Spider中获取到第一个要爬取的URL并在调度器(Scheduler)以Request调度。
- 引擎向调度器请求下一个要爬取的URL。
- 调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件(请求(request)方向)转发给下载器(Downloader)。
- 一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(返回(response)方向)发送给引擎。
- 引擎从下载器中接收到Response并通过Spider中间件(输入方向)发送给Spider处理。
- Spider处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。
- 引擎将(Spider返回的)爬取到的Item给Item Pipeline,将(Spider返回的)Request给调度器。
- (从第二步)重复直到调度器中没有更多地request,引擎关闭该网站。
二 创建项目及相关组件说明
Scrapy库的安装、项目创建及简单使用参考之前的博客Python网络爬虫之scrapy(一),下面主要对项目各组件进行说明
(1) 项目目录结构
D:scrapy_project>scrapy genspider country example.webscraping.com
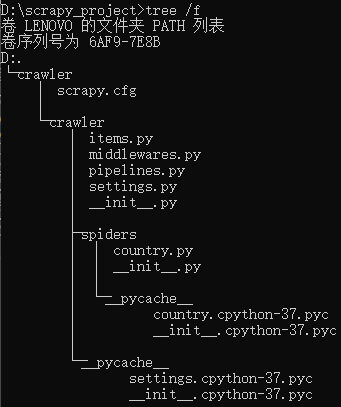
item.py:类似Django中的models.py,用于声明数据类型,将来报错数据
middlewares.py:爬虫中间件,可以对请求和响应进行处理
pipelines.py:管道,作用是将每一个Item对象进行存储,MySql/MongoDB
settings.py:对爬虫项目进行配置
spiders:管理对各爬虫项目,具体的爬虫逻辑在各自的项目爬虫文件中
country.py:创建的爬虫项目
三 Scrapy重要类说明及部分源码分析
1. Response类
(1)查看Response类的属性
from scrapy.http import Response for key,value in Response.__dict__.items(): print("{0}:{1}".format(key,value))
__module__:scrapy.http.response __init__:<function Response.__init__ at 0x00000257D64B1C80> meta:<property object at 0x00000257D64B2458> _get_url:<function Response._get_url at 0x00000257D64B40D0> _set_url:<function Response._set_url at 0x00000257D64B4158> url:<property object at 0x00000257D64B24A8> _get_body:<function Response._get_body at 0x00000257D64B4268> _set_body:<function Response._set_body at 0x00000257D64B42F0> body:<property object at 0x00000257D64B2728> __str__:<function Response.__str__ at 0x00000257D64B4400> __repr__:<function Response.__str__ at 0x00000257D64B4400> copy:<function Response.copy at 0x00000257D64B4488> replace:<function Response.replace at 0x00000257D64B4510> urljoin:<function Response.urljoin at 0x00000257D64B4598> text:<property object at 0x00000257D64B2778> css:<function Response.css at 0x00000257D64B46A8> xpath:<function Response.xpath at 0x00000257D64B4730> follow:<function Response.follow at 0x00000257D64B47B8> __dict__:<attribute '__dict__' of 'Response' objects> __weakref__:<attribute '__weakref__' of 'Response' objects> __doc__:None
从上面我们会看到三个重要属性(url、body和text),再查看下Response类源码会发现如下代码
url = property(_get_url, obsolete_setter(_set_url, 'url')) body = property(_get_body, obsolete_setter(_set_body, 'body')) @property def text(self): """For subclasses of TextResponse, this will return the body as text (unicode object in Python 2 and str in Python 3) """ raise AttributeError("Response content isn't text")
url、body、text这就是我们在爬虫分析中需要用到的三个重要属性,都可与通过Response对象获得
例子:
import scrapy from lxml import etree class CountrySpider(scrapy.Spider): name = 'country' allowed_domains = ['example.webscraping.com'] start_urls = ['http://example.webscraping.com/places/default/view/Afghanistan-1'] #该函数名不能改变,因为scrapy源码中默认callback函数的函数名就是parse def parse(self, response): from bs4 import BeautifulSoup as bs print(response.url) soup = bs(response.body) names = [i.string for i in soup.select('td.w2p_fl')] values = [j.string for j in soup.select('td.w2p_fw')] dic = dict(zip(names, values)) print(dic)
2. Spider类
(1)样的方法,线查看Spider类提供的属性
import scrapy for key,val in scrapy.Spider.__dict__.items(): print("{}:{}".format(key,val))
__module__:scrapy.spiders __doc__:Base class for scrapy spiders. All spiders must inherit from this class. name:None custom_settings:None __init__:<function Spider.__init__ at 0x000001E161FFFD90> logger:<property object at 0x000001E161785D18> log:<function Spider.log at 0x000001E161FFFEA0> from_crawler:<classmethod object at 0x000001E16178B208> set_crawler:<function Spider.set_crawler at 0x000001E161FF8048> _set_crawler:<function Spider._set_crawler at 0x000001E161FF80D0> start_requests:<function Spider.start_requests at 0x000001E161FF8158> make_requests_from_url:<function Spider.make_requests_from_url at 0x000001E161FF81E0> parse:<function Spider.parse at 0x000001E161FF8268> update_settings:<classmethod object at 0x000001E16178B240> handles_request:<classmethod object at 0x000001E16178B278> close:<staticmethod object at 0x000001E161FF7E80> __str__:<function Spider.__str__ at 0x000001E161FF8488> __repr__:<function Spider.__str__ at 0x000001E161FF8488> __dict__:<attribute '__dict__' of 'Spider' objects> __weakref__:<attribute '__weakref__' of 'Spider' objects>
(2)接下来对其中几个重要的属性和方法进行说明:
start_requests()
该 方法会默认读取start_urls属性中定义的网址,为每一个网址生成一个Request请求对象,并返回可迭代对象
make_request_from_url(url)
该方法会被start_request()调用,该方法负责实现生成Request请求对象
close(reason)
关闭Spider时,该方法会被调用
log(message[,level,component])
使用该方法可以实现在Spider中添加log
(3)上面几个函数对应的源码
def start_requests(self): cls = self.__class__ if method_is_overridden(cls, Spider, 'make_requests_from_url'): warnings.warn( "Spider.make_requests_from_url method is deprecated; it " "won't be called in future Scrapy releases. Please " "override Spider.start_requests method instead (see %s.%s)." % ( cls.__module__, cls.__name__ ), ) for url in self.start_urls: yield self.make_requests_from_url(url) else: for url in self.start_urls: yield Request(url, dont_filter=True) def make_requests_from_url(self, url): """ This method is deprecated. """ return Request(url, dont_filter=True) def log(self, message, level=logging.DEBUG, **kw): """Log the given message at the given log level This helper wraps a log call to the logger within the spider, but you can use it directly (e.g. Spider.logger.info('msg')) or use any other Python logger too. """ self.logger.log(level, message, **kw)
(4)例子:重写start_request()方法
import scrapy from lxml import etree class CountrySpider(scrapy.Spider): name = 'country' allowed_domains = ['example.webscraping.com'] start_urls = ['http://example.webscraping.com/places/default/view/Afghanistan-1', "http://example.webscraping.com/places/default/view/Aland-Islands-2"] #重写start_request()方法 def start_requests(self): for url in self.start_urls: yield self.make_requests_from_url(url) #该函数名不能改变,因为scrapy源码中默认callback函数的函数名就是parse def parse(self, response): from bs4 import BeautifulSoup as bs print(response.url) soup = bs(response.body) names = [i.string for i in soup.select('td.w2p_fl')] values = [j.string for j in soup.select('td.w2p_fw')] dic = dict(zip(names, values)) print(dic)
3. pipines的编写
在项目被蜘蛛抓取后,它被发送到项目管道,它通过顺序执行的几个组件来处理它。
每个项目管道组件(有时称为“Item Pipeline”)是一个实现简单方法的Python类。他们接收一个项目并对其执行操作,还决定该项目是否应该继续通过流水线或被丢弃并且不再被处理。
简单理解就是将item的内容进行处理或保存
class CrawlerPipeline(object): def process_item(self, item, spider): country_name = item["country_name"] country_area = item["country_area"] # 后续处理,可以写进文件 return item
新手必遇到文件,发现process_item没有被调用,解决方案:
(1)在setting.py中进行配置
ITEM_PIPELINES = { 'crawler.pipelines.CrawlerPipeline':300, } #后面的数字为0-1000,决定执行的优先级
(2)在爬虫项目的回调函数中def parse(self, response)中记得返回item
yield item
若要了解更详细的使用方法,可以参考博客:https://www.jianshu.com/p/b8bd95348ffe