就库的范围,个人认为网络爬虫必备库知识包括urllib、requests、re、BeautifulSoup、concurrent.futures,接下来将结对requests库的使用方法进行总结
1. requests库简介
官方中文文档:http://docs.python-requests.org/zh_CN/latest/user/quickstart.html
Requests 是用Python语言编写,基于 urllib,采用 Apache2 Licensed 开源协议的 HTTP 库。
它比 urllib 更加方便,上篇博客中使用的urllib方法都可以通过requests实现,个人认为更方便于爬虫。
requests库功能过于强大,包括:保持活力和连接池、支持国际域名和网址、会话与Cookie持久性、浏览器式SSL验证、自动内容解码、基本/摘要式身份验证、自动解压缩、Unicode响应body、HTTP(s)代理支持、多部分文件上传、流媒体下载、连接超时、分块的请求、.netrc 支持等
request依赖包关系:
requests==2.19.1 - certifi [required: >=2017.4.17, installed: 2018.4.16] #CA认证模块 - chardet [required: <3.1.0,>=3.0.2, installed: 3.0.4] #通用字符编码检测器模块 - idna [required: <2.8,>=2.5, installed: 2.7] #国际化域名解析模块 - urllib3 [required: <1.24,>=1.21.1, installed: 1.23] #线程安全HTTP库
2. Response请求响应类
由于resquests方法都将返回一个Response对象,为了方便大家对后面每个request方法的测试,我决定将Response类放在最前面总结
Response类封装在requests.modles中,该Response对象包含服务器对HTTP请求的响应信息
该对象包含的属性和方法:
apparent_encodind:由chardet库提供的明显编码。
close():将连接释放回池中,即关闭连接,通常不需要调用
content:响应的内容,以字节为单位。
cookies=None : 服务器发回的Cookies CookieJar。
elapsed=None : 发送请求和响应到达之间所经过的时间量(作为timedelta)。该属性具体测量发送请求的第一个字节和完成解析报头之间的时间。因此,它不受消费响应内容或stream关键字参数值的影响。
encoding=None : 编码以在访问r.text时进行解码。
headers=None :不区分大小写的响应头字典。例如,headers['content-encoding']将返回'Content-Encoding'响应头的值。
history=None :Response请求历史记录中的对象列表。任何重定向响应都会在这里结束。该列表从最旧的到最近的请求进行排序。
is_permanent_redirect:如果此响应为真,则为重定向的永久版本之一。
is_redirect:如果此响应是可以自动处理的格式良好的HTTP重定向,则为真。
iter_content(chunk_size = 1,decode_unicode = False ):迭代响应数据。在请求中设置stream = True时,可以避免将内容一次性读入内存以获得较大的响应。块大小是它应该读入内存的字节数;chunk_size必须是int或None类型。stream = True将在数据以任何大小接收到的数据到达时读取数据。如果stream = False,则数据作为单个块返回;如果decode_unicode为True,则内容将使用基于响应的最佳可用编码进行解码。
iter_lines(chunk_size = 512,decode_unicode = None,delimiter = None ):迭代响应数据,一次一行。在请求中设置stream = True时,可以避免将内容一次性读入内存以获得较大的响应。
json(** kwargs ):返回响应的json编码内容
links:返回解析的响应头部链接
next:返回重定向链中下一个请求的PreparedRequest
ok:如果status_code小于400 则返回True,否则返回False
reason=None:响应HTTP状态的文本原因,例如“未找到”或“确定”。
request=None:一个响应的对象。
status_code=None:整数响应HTTP状态的代码,例如404或200。
text:响应的内容,以unicode表示。
url=None:响应的最终URL位置
3. requests提供的系列HTTP方法
requests库提供了包含requests.request函数在内告知服务器意图的7种方法,7种方法分别是:get,options,head,post,put,pach,delete,这7种方法都封装在api.py模块种,通过阅读源码我们会发现这7种方法的内部实现都是直接调用的request函数接口,也就是说所有方法的参数都在request函数参数中,所有方法能实现的功能都可以由request函数实现。下面将依次介绍各方法的功能和函数原型,若没有例子不用在意,将在第三节内容后通过具体实践对各方法详细介绍。
(1)get:获取资源
请求访问已被URI识别的资源,指定的资源经服务器端解析后返回响应内容,也就是说如果请求的是文本,那就保持原样返回,如果是像CGI(通用网关接口)那样的程序,则返回经过执行后的输出结果。
函数原型:
def get(url, params=None, **kwargs): r"""Sends a GET request. :param url: URL for the new :class:`Request` object. :param params: (optional) Dictionary or bytes to be sent in the query string for the :class:`Request`. :param **kwargs: Optional arguments that ``request`` takes. :return: :class:`Response <Response>` object :rtype: requests.Response """ kwargs.setdefault('allow_redirects', True) return request('get', url, params=params, **kwargs)
注意注释已说明参数为字典或字节,返回一个response对象,看下面简单示例:
params={'name':'张三','age':17} response = requests.get('https://www.baidu.com', params = params) print('###以下为response属性:') print([attr for attr in dir(response) if not attr.startswith('_')]) print("status_code:",response.status_code) print("url:",response.url)

从输出接口可以看出response对象的属性(以_开头的属性都没打印出来),大家可以一一的打印看看各属性值是什么。
这里主要说下response.text和response.content的区别,这两个属性都返回响应内容主体,text返回的是字符串类型,content返回的是二进制类型,很多情况下的网站如果直接response.text会出现乱码的问题,可以通过response.content.decode('utf-8')的方法解决通过response.text直接返回显示乱码的问题。
(2)opetions:询问支持的方法
options方法用来查询针对请求URL指定的资源支持的方法,说的直白点就是服务器返回它支持的这7种方法中的某种
函数原型:
def options(url, **kwargs): r"""Sends an OPTIONS request. :param url: URL for the new :class:`Request` object. :param **kwargs: Optional arguments that ``request`` takes. :return: :class:`Response <Response>` object :rtype: requests.Response """ kwargs.setdefault('allow_redirects', True) return request('options', url, **kwargs)
上面提到了默认支持允许重定向,options方法使用很少
response = requests.options('https://www.baidu.com')
(3)head:获得报文首部
函数原型:
def head(url, **kwargs): r"""Sends a HEAD request. :param url: URL for the new :class:`Request` object. :param **kwargs: Optional arguments that ``request`` takes. :return: :class:`Response <Response>` object :rtype: requests.Response """ kwargs.setdefault('allow_redirects', False) return request('head', url, **kwargs)
特别注意,上面的允许重定向属性默认为False
response = requests.head('https://www.baidu.com') print("status_code:",response.status_code) print("url:",response.url) print(response.headers)

(4)post:传输实体主体
函数原型:
def post(url, data=None, json=None, **kwargs): r"""Sends a POST request. :param url: URL for the new :class:`Request` object. :param data: (optional) Dictionary (will be form-encoded), bytes, or file-like object to send in the body of the :class:`Request`. :param json: (optional) json data to send in the body of the :class:`Request`. :param **kwargs: Optional arguments that ``request`` takes. :return: :class:`Response <Response>` object :rtype: requests.Response """ return request('post', url, data=data, json=json, **kwargs)
简单示例:
import requests data = { "name":"fate0729", "age":23 } response = requests.post("http://httpbin.org/post",data=data)
(5)put:传送更新资源(全部更新)
put方法用于传送更新资源,比如传输文件,要求在请求报文的主体中包含文件内容,然后保存到请求URL指定位置,但是鉴于HTTP/1.1的PUT方法自身不带验证机制,任何人都可以上传文件存在安全性问题,因此一般的web网站不使用该方法,若配合web应用程序的验证机制,或架构设计采用REST标准的同类网站,就可以开放使用put方法
函数原型:
def put(url, data=None, **kwargs): r"""Sends a PUT request. :param url: URL for the new :class:`Request` object. :param data: (optional) Dictionary (will be form-encoded), bytes, or file-like object to send in the body of the :class:`Request`. :param json: (optional) json data to send in the body of the :class:`Request`. :param **kwargs: Optional arguments that ``request`` takes. :return: :class:`Response <Response>` object :rtype: requests.Response """ return request('put', url, data=data, **kwargs)
(6)pach:传送更新资源(局部更新)
pach和put的区别,我在度娘上看到了下面的一段话,觉得很明了:
假设我们有一个UserInfo,里面有userId, userName, userGender等10个字段。可你的编辑功能因为需求,在某个特别的页面里只能修改userName,这时候的更新怎么做?人们通常(为省事)把一个包
含了修改后userName的完整userInfo而put虽然也是更新资源,但要求前端提供的一定是一个完整的资源对象,理论上说,如果你用了put,但却没有提供完整的UserInfo,那么缺了的那些字段应该被清空对象
传给后端,做完整更新。但仔细想想,这种做法感觉有点二,而且真心浪费带宽(纯技术上讲,你不关心带宽那是你土豪)。于是patch诞生,只传一个userName到指定资源去,表示该请求是一个局部更新,后
端仅更新接收到的字段。
函数原型:
def patch(url, data=None, **kwargs): r"""Sends a PATCH request. :param url: URL for the new :class:`Request` object. :param data: (optional) Dictionary (will be form-encoded), bytes, or file-like object to send in the body of the :class:`Request`. :param json: (optional) json data to send in the body of the :class:`Request`. :param **kwargs: Optional arguments that ``request`` takes. :return: :class:`Response <Response>` object :rtype: requests.Response """ return request('patch', url, data=data, **kwargs)
(7)delete:删除指定的资源
delete方法与put方法相反,与put方法一样,鉴于HTTP/1.1的PUT方法自身不带验证机制,一般的网站不使用delete方法
函数原型:
def delete(url, **kwargs): r"""Sends a DELETE request. :param url: URL for the new :class:`Request` object. :param **kwargs: Optional arguments that ``request`` takes. :return: :class:`Response <Response>` object :rtype: requests.Response """ return request('delete', url, **kwargs)
(8)request函数
对该函数参数的理解无比重要,其实也很简单,都是大家熟悉的
函数原型:
def request(method, url, **kwargs): with sessions.Session() as session: return session.request(method=method, url=url, **kwargs)
**kwargs参数说明:
- method:request对象的方法(POST)
- url:request对象的URL
- params:可选的,要在查询字符串中发送的字典或字节request
- data:可选的,字典或元祖列表以表单编码,字节或类似文件的对象在主体中发送[(key,value)]
- json:可选的,一个json可序列化的python对象,在主体中发送request
- headers:可选的,用于编写http头信息
- cookies:可选,用dict或cookieJar对象发送Cookies
- file:可选,用于多部分编码上传的字典,可以是多元祖,其中是定义给定文件的内容类型的字符串,以及包含问文件添加的额外头文件的类字典对象
- auth:可选,身份验证元祖,自定义http身份验证
- timeout:可选,发送等待请求数据的超时时间(float/tuple),设置为元祖即为练级connect和read读取超时,如果设置为None即为永久等待
- allow_redirects:布尔值,可选,启用或禁用GET,OPTIONS,POST,PUT,PATCH,DELETE,HEAD重定向,默认为true
- proxies:可选,字典映射协议到代理的URL
- verify:可选,可以是布尔值,可以指定验证服务器的TLS证书路径,默认为true
- stream:可选,如果是False,响应内容将立即下载
- cert:可选,如果是string,则为ssl客户端证书文件路径,如果是元祖则('cert','key')指定证书和密钥
下面将通过模拟登录示例别展示requests模块的部分高级用法
4. 模拟登录示例
以模拟登录github官网为例,登录网址:https://github.com/login
(1)首先使用错误的账号和密码登录,分析请求头和参数,按F2可以找到与登录对应的POST方法
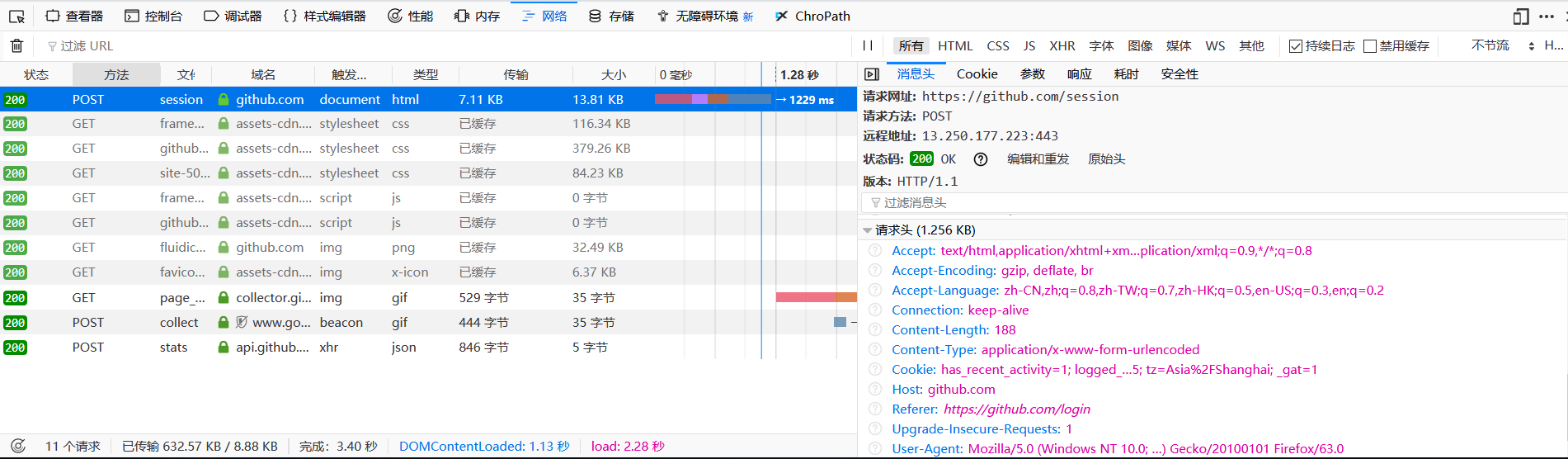
特别注意,请求网址为https://github.com/session,而不是https://github.com/login,小心入坑,查看参数:
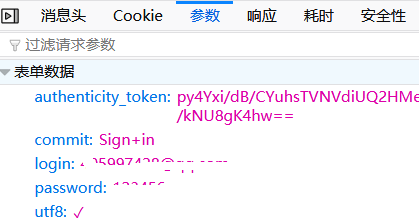
解析来进行编码:
(2)设置请求头:
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:63.0) Gecko/20100101 Firefox/63.0',
'Connection':'keep-alive',
'Host':'github.com'}
(3)设置cookies,模拟登录github网必须使用cookies,否则将登录失败
cookies = response.cookies
(4)获取请求参数
html = response.content.decode('utf-8') soup = bs(html,'lxml') login_data = {} for item in soup.select('input[name]'): if item.get("name"): login_data[item.get("name")] = item.get("value")
(5)修改请求参数,参入登录名和密码
login_data["login"] = 你自己的登录名 login_data["password"] = 你自己的密码
(6)设置等待超时:防止一直等待
timeout=3
(7)万事具备,只欠测试
import requests from bs4 import BeautifulSoup as bs from requests.exceptions import ReadTimeout,ConnectionError,RequestException url = 'https://github.com/session' headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:63.0) Gecko/20100101 Firefox/63.0', 'Connection':'keep-alive', 'Host':'github.com'} response = requests.request('get',url,headers = headers) # 这里可以替换为 response = requests.get(url,headers = headers) print('起始url:',response.url) html = response.content.decode('utf-8') soup = bs(html,'lxml') login_data = {} for item in soup.select('input[name]'): if item.get("name"): login_data[item.get("name")] = item.get("value") login_data["login"] = "------------" login_data["password"] = "--------" print('data:',login_data) try: response = requests.request('post',url,data=login_data, headers = headers,cookies = response.cookies,timeout=3) # 上面代码可以替换为 #response = requests.post(url,data=login_data, #headers = headers,cookies = response.cookies,timeout=3) except Timeout: print("timeout") except ConnectionError: print("connection Error") except RequestException: print("error") else: print("status_code:",response.status_code) print("登陆后url:",response.url)
输出:

从结果可以看出起始URL和登录后URL已不同,说明模拟登录成功,github的模拟登录很简单,大家可以试试复杂点的,比如知乎网的模拟登录
(8)大多数网站都会检测某一段事件某个IP的访问次数,如果访问次数过多,它会禁止你的访问,这个时候需要设置代理服务器来爬取数据。
proxies= { "http":"http://127.0.0.1:9999", "https":"http://127.0.0.1:8888" } response = requests.request('get',url, proxies=proxies)
如果代理需要设置账户名和密码,只需要将字典更改为如下:
proxies = { "http":"http://user:password@127.0.0.1:9999" }
如果你的代理是通过sokces这种方式则需要pip install "requests[socks]"
proxies= { "http":"socks5://127.0.0.1:9999", "https":"sockes5://127.0.0.1:8888" }
(9)使用Session修改上面的代码实现同样的功能
从源码上我们知道request内部调用的是Session对象的request函数
with sessions.Session() as session: return session.request(method=method, url=url, **kwargs)
每次都使用了新的Session对象,其实我们可以一直以一个Session对象维持会话,当一个会话对象进行请求时,已经获取了当前的cookie,这各可以从源码看到
if cookiejar is None: cookiejar = RequestsCookieJar()
修改上面的代码:
session = requests.Session() response = session.request('get',url,headers = headers) ................ ............. ........ response = session('post',url,data=login_data, headers = headers,timeout=3) .............. >>>> 效果和之前一样
5. SSL证书验证
requests提供了证书验证的功能,当发送http请求时,它会检查SSL证书,可以通过verify参数来控制是否检查此证书,默认为True会自动验证,测试https://www.12306.cn
import requests r=requests.get('https://www.12306.cn') print(r.status_code)
>>> raiser SSLError
将verify参数设置为flase:
import requests r=requests.get('https://www.12306.cn',verify=False) print(r.status_code) #能正常返回200,但有个警告信息 C:virtualenv-36.venvlibsite-packagesurllib3connectionpool.py:857
: InsecureRequestWarning: Unverified HTTPS request is being made.
Adding certificate verification is strongly advised. See:
https://urllib3.readthedocs.io/en/latest/advanced-usage.html#ssl-warnings InsecureRequestWarning)
我们如果有证书的话,可以cert参数指定证书路径,如果是单个文件包含密钥和证书,也可以设置两个文件路径的元祖分别指向证书和密钥
import requests response = requests.get('https://www.12306.cn', cert= ('/path/server.crt', '/path/key')) print(response.status_code) #注意,如果是本地私有证书的key必须是解密状态,加密状态的key是不支持的
6. 身份认证
如果访问的网站需要身份认证的话,可以使用requests自带的身份认证功能
其中包括四个类:
class requests.auth.AuthBase:所有auth实现派生自的基类
class requests.auth.HTTPBasicAuth(username, password):将HTTP基本认证附加到给定的请求对象
class requests.auth.HTTPProxyAuth(username, password):将HTTP代理身份验证附加到给定的请求对象
class requests.auth.HTTPDigestAuth(username, password):将HTTP摘要式身份验证附加到给定的请求对象
(1)基本认证
import requests from requests.auth import HTTPBasicAuth url='http://192.168.146.140/admin/' s=requests.Session() #创建密码认证对象 auth=HTTPBasicAuth('admin','123') #附加认证信息 response=s.get(url,auth=auth) print(response.text)
(2)代理身份认证
import requests from requests.auth import HTTPProxyAuth proauth=HTTPProxyAuth(username='admin',password='123') proxies={ 'http':'10.0.0.10:3324' } #创建session对象 s=requests.Session() #添加代理身份验证 s.trust_env=proauth #添加代理 s.proxies=proxies response=s.get('https://www.facebook.com') print(response.status_code)
7. 异常处理

上图来自官网:http://www.python-requests.org/en/master/api/#exceptions
从源码我可以看出各异常类的继承关系:
RequestException继承IOError
HTTPError,ConnectionError,Timeout继承RequestionException
ProxyError,SSLError继承ConnectionError
ReadTimeout继承Timeout异常
之前的模拟登录中已经列出了异常的使用方法,大家可以自己分别测试各异常出现的情况
except Timeout: print("timeout") except ConnectionError: print("connection Error") except RequestException: print("error")
补充:requests库涉及到http协议的方方面面,要想了解的更全面更详细,建议大家多阅读源码,再经过demo进行测试,这样的话会有更直接的体会。