第一次个人编程作业
一、作业链接
二、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| · Planning | · 计划 | 20 | 30 |
| · Estimate | · 估计这个任务需要多少时间 | 10 | 10 |
| · Development | · 开发 | 120 | 150 |
| · Analysis | · 需求分析 (包括学习新技术) | 1000 | 1200 |
| · Design Spec | · 生成设计文档 | 30 | 60 |
| · Design Review | · 设计复审 | 30 | 50 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 60 | 60 |
| · Design | · 具体设计 | 240 | 280 |
| · Coding | · 具体编码 | 330 | 300 |
| · Code Review | · 代码复审 | 60 | 40 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 120 | 160 |
| · Reporting | · 报告 | 40 | 40 |
| · Test Repor | · 测试报告 | 30 | 30 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 60 | 90 |
| · 合计 | 2160 | 2510 |
三、计算模块接口的设计与实现过程

(题外话...)一开始看到作业题目篇幅这么长,内心极度嫌弃,甚至第一次没看全就关掉了。后来的一天,终于认真的看了一下题目,还是熟悉的味道(不会做)。可不会做咱不能束手就 -寝- 擒阿。于是乎,查找了各种资料,问烦了身边的大牛,终于找到了一个我能稍微理解的算法。
我所采用的是python+jieba+gensim计算文本相似度,这里用到了jieba的分词,以及gensim的doc2bow词袋模型
-
首先引入分词库jieba、文本相似度库gensim
import jieba for gensim import corpora,models,similaritiestexts = [jieba.lcut(text) for text in texts] #将文本分词并形成列表 dictionary = corpora.Dictionary(texts) # 基于文本集建立【词典】,并获得词典特征数 num_features = len(dictionary.token2id) corpus = [dictionary.doc2bow(text) for text in texts] # 基于词典,将【分词列表集】转换成【稀疏向量集】,称作【语料库】 tfidf = models.TfidfModel(corpus) # 用语料库来训练TF-IDF模型 new_vec = dictionary.doc2bow(jieba.lcut(test)) # 把测试文档进行分词并转换为二元组的向量 index = similarities.SparseMatrixSimilarity(tfidf[corpus], num_features) # 计算稀疏矩阵相似度,建立一个索引 sim = index[tfidf[new_vec]] # 根据索引得到最终的相似度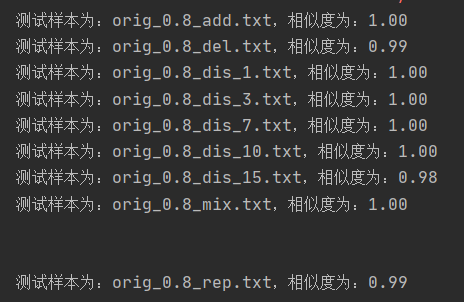
根据输出来看,该算法算出来的相似度几乎都是接近1,结果不太可观。于是继续查找资料,发现文本中的某些词以及标点符号没有包含什么信息,并且特别高频。这些词语对于判断文章的相似度毫无用处,并且会干扰计算。于是自己自定义了一个停用词列表,改进后再看结果。
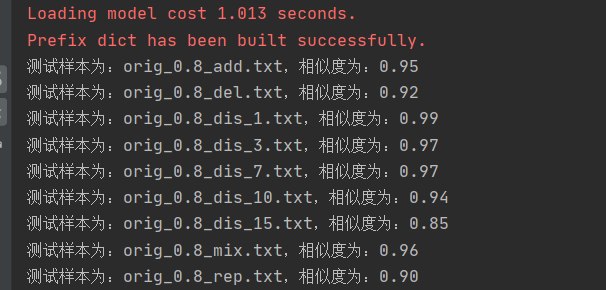
可以看出,去除停用词以后,最后的计算结果相比之前还是挺不错的。
四、计算模块接口部分的性能改进
(1)内存占用

因为在计算相似度的函数中,调用了去除停用词的函数,所以该函数所占用的内存较大。
(2)时间花费
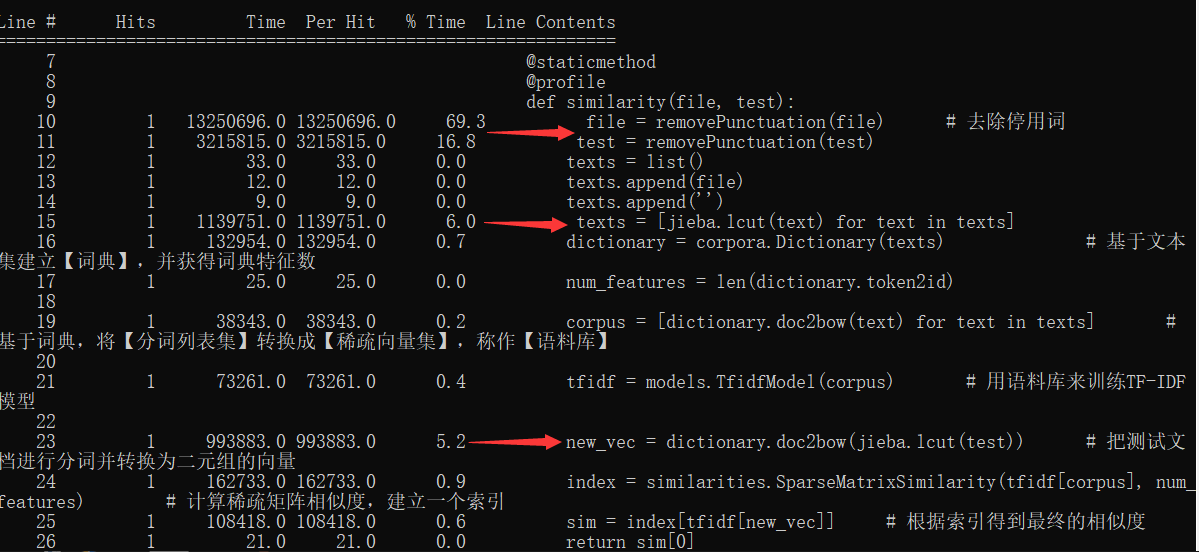
jieba分词以及去除停用词花费的时间占比较大
综上所述,去除停用词的函数为该程序的瓶颈所在,需要再进一步改进。可能需要考虑别的算法(等以后有时间了继续改进)
五、计算模块部分单元测试展示
file = open('orig.txt', 'r', encoding='utf-8').read()
test = dict()
test['orig_0.8_add.txt'] = open('orig_0.8_add.txt', 'r', encoding='utf-8').read()
#此处都为读取文本,故省略
class Testsim(unittest.TestCase):
def test_cosine(self):
cos = Similarity()
print('开始测试相似度!')
for key in test.keys():
if test[key] != '':
result = cos.similarity(file, test[key])
print('测试样本为:%s,相似度为:%.2f' % (key, result))
else:
raise EmptyError
if __name__ == '__main__':
unittest.main()

六、计算模块部分异常处理说明
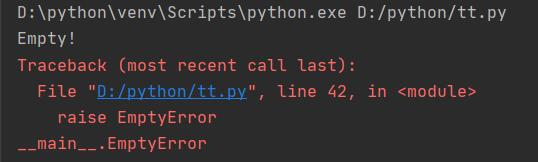
(1)自定义异常代码-EmptyError
当测试文本为空文本时,相似度计算会出现除0计算,需要排除这一情况。
class EmptyError(Exception):
def __init__(self):
print('Empty!')
七、个人总结
就挺秃然的,每次查着资料,结果我啥都不会,就暗暗叹气,可是生活还是要继续。就像老师上课所说的,我们要站在巨人的肩膀上,这次个人编程作业我就深深的体会到了拥抱开源的魅力以及做好一个项目不仅仅只有代码,还要考虑测试、异常、写文档,代码只是小小的一部分。学会怎么样去自学,怎么样面对一个陌生的事物,怎么规划,怎么查资料真的非常重要,否则在这次作业中就可能像一只无头苍蝇,不知所措。希望自己继续学习,学会了一个新东西还是挺有成就感的。
