输出下面三张表
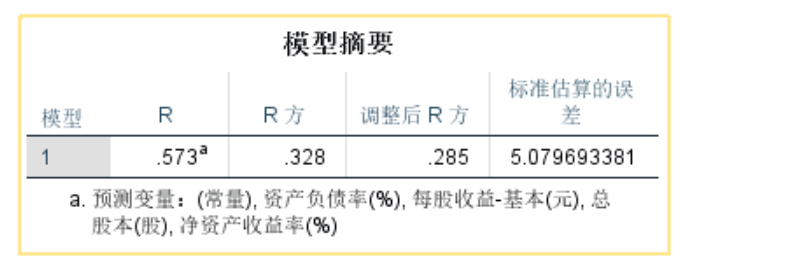
第一张R方是拟合优度
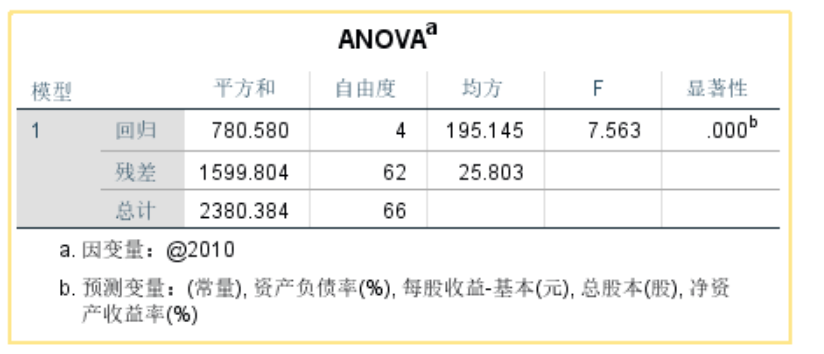
对总回归方程进行F检验。显著性是sig。
结果的统计学意义,是结果真实程度(能够代表总体)的一种估计方法。专业上,p 值为结果可信程度的一个递减指标,p 值越大,我们越不能认为样本中变量的关联是 总体中各变量关联的可靠指标。p 值是将观察结果认为有效即具有总体代表性的犯错概率。如 p=0.05 提示样本中变量关联有 5% 的可能是由于偶然性造成的。 即假设总体中任意变量间均无关联,我们重复类似实验,会发现约 20 个实验中有一个实验,我们所研究的变量关联将等于或强于我们的实验结果。(这并不是说如变量间存在关联,我们可得到 5% 或 95% 次数的相同结果,当总体中的变量存在关联,重复研究和发现关联的可能性与设计的统计学效力有关。)在许多研究领域,0.05 的 p 值通常被认为是可接受错误的边界水平。
F检验:
对于多元线性回归模型,在对每个回归系数进行显著性检验之前,应该对回归模型的整体做显著性检验。这就是F检验。当检验被解释变量yt与一组解释变量x1, x2 , ... , xk -1是否存在回归关系时,给出的零假设与备择假设分别是
H0:b1 = b2 = ... = bk-1 = 0 ,
H1:bi, i = 1, ..., k -1不全为零。
首先要构造F统计量。由(3.36)式知总平方和(SST)可分解为回归平方和(SSR)与残差平方和(SSE)两部分。与这种分解相对应,相应自由度也可以被分解为两部分。
SST具有T - 1个自由度。这是因为在T个变差 ( yt -), t = 1, ..., T,中存在一个约束条件,即 = 0。由于回归函数中含有k个参数,而这k个参数受一个约束条件 制约,所以SSR具有k -1个自由度。因为SSE中含有T个残差,= yt -, t = 1, 2, ..., T,这些残差值被k个参数所约束,所以SSE具有T - k个自由度。与SST相对应,自由度T - 1也被分解为两部分,
(T -1) = ( k - 1) + (T - k) (3.44)
平方和除以它相应的自由度称为均方。所以回归均方定义为
MSR = SSR / ( k - 1)
误差均方定义为
MSE = SSE / (T - k)
(显然MSE = s 2 (见3.23式),它的期望是s 2)。定义F统计量为
(3.45)
在H0成立条件下,有
F = ~ F(k -1, T - k)
设检验水平为 a,则检验规则是
若用样本计算的F <= Fa (k -1, T - k),则接受H0,
若用样本计算的F > Fa (k -1, T - k),则拒绝H0。
拒绝H0意味着肯定有解释变量与yt存在回归关系。若F检验的结论是接受H0,则说明k – 1个解释变量都不与yt存在回归关系。此时,假设检验应该到此为止。当F检验的结论是拒绝H0时,应该进一步做t检验,从而确定模型中哪些是重要解释变量,哪些是非重要解释变量。
本实验中k-1=4,T-k=62,检验水平为0.05,则Fa(4,62) 利用excel表查询,输入公式=FINV(0.05,4,62)=2.520101,再试一下0.01检验水平,FINV=3.6378,本实验得到的F为7.563,所以拒绝H0,具有显著性。
这部分是总体分析
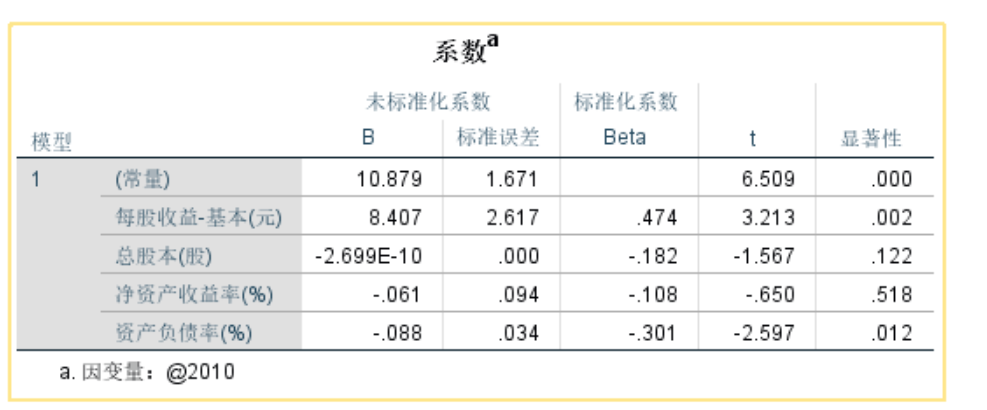
第三部分是看各个自变量对因变量的显著性,是T检验。
T检验:
1、建立虚无假设H0:μ1 = μ2,即先假定两个总体平均数之间没有显著差异;
2、计算统计量t值,对于不同类型的问题选用不同的统计量计算方法;
1)如果要评断一个总体中的小样本平均数与总体平均值之间的差异程度,其统计量t值的计算公式为:
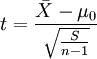
2)如果要评断两组样本平均数之间的差异程度,其统计量t值的计算公式为:
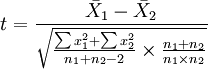
3、根据自由度df=n-1,查t值表,找出规定的t理论值并进行比较。理论值差异的显著水平为0.01级或0.05级。不同自由度的显著水平理论值记为t(df)0.01和t(df)0.05
4、比较计算得到的t值和理论t值,推断发生的概率,依据下表给出的t值与差异显著性关系表作出判断。
| T值与差异显著性关系表 | ||
|---|---|---|
| t | P值 | 差异显著程度 |
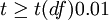 |
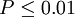 |
差异非常显著 |
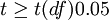 |
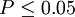 |
差异显著 |
| t < t(df)0.05 | P > 0.05 | 差异不显著 |
以0.05为检验水平的话,图中可以看到总股本和净资产收益率不显著,其他显著。
图中B是各个自变量的系数,负值代表是负相关,所以资产负债率是负向影响。标准化的系数反应了这个自变量对因变量的影响程度。
多重线性分析
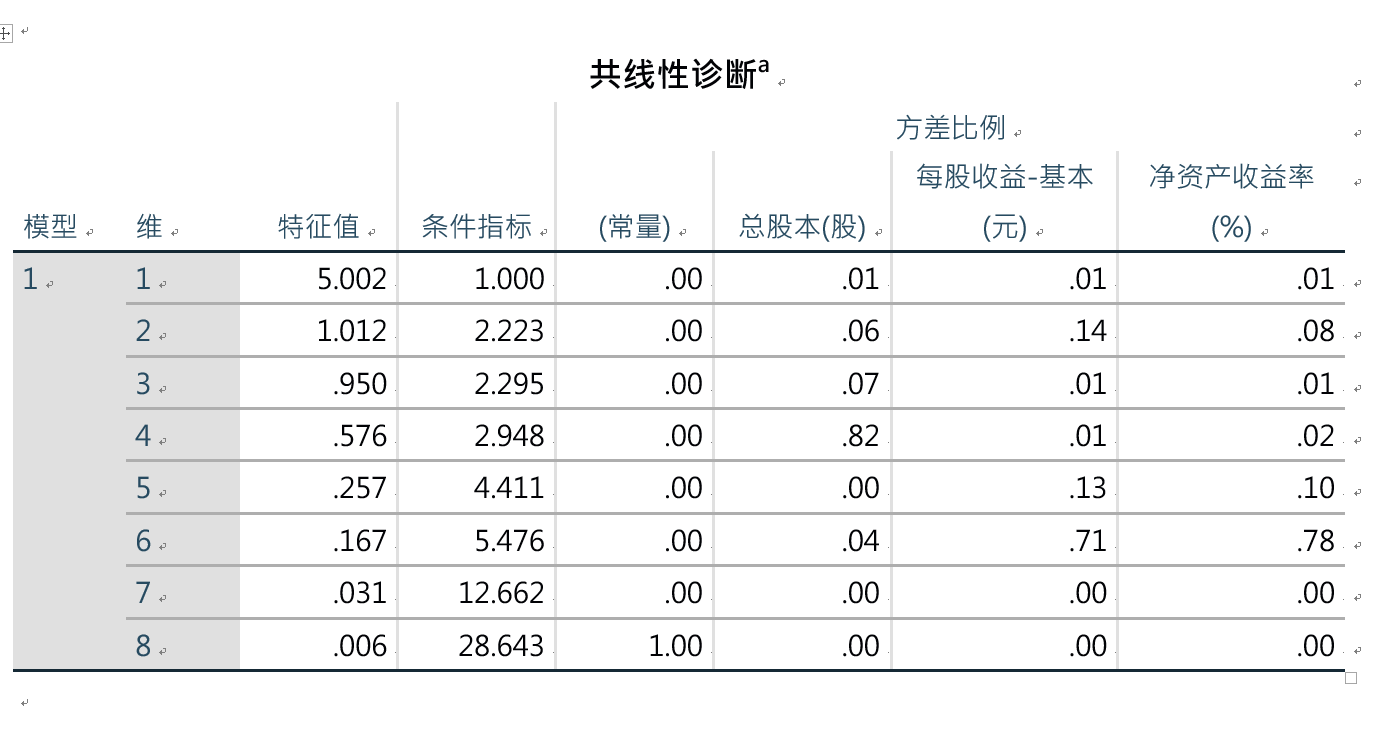
多个维度特征值约为0证明可能存在多重共线性 条件指标大于10时提示有多重共线性
再看相关系数矩阵 近似为1的有多重共线性
例如在回归分析中,线性回归-统计量-有共线性诊断。 多重共线性:自变量间存在近似的线性关系,即某个自变量能近似的用其他自变量的线性函数来描述。 多重共线性的后果: 整个回归方程的统计检验Pa,不能纳入方程 去掉一两个变量或记录,方程的回归系数值发生剧烈抖动,非常不稳定。 多重共线性的确认: 做出自变量间的相关系数矩阵:如果相关系数超过0.9的变量在分析时将会存在共线性问题。在0.8以上可能会有问题。但这种方法只能对共线性作初步的判断,并不全面。 容忍度(Tolerance):有 Norusis 提出,即以每个自变量作为应变量对其他自变量进行回归分析时得到的残差比例,大小用1减决定系数来表示。该指标越小,则说明该自变量被其余变量预测的越精确,共线性可能就越严重。陈希孺等根据经验得出:如果某个自变量的容忍度小于0.1,则可能存在共线性问题。 方差膨胀因子(Variance inflation factor, VIF): 由Marquardt于1960年提出,实际上就是容忍度的倒数。 特征根(Eigenvalue):该方法实际上就是对自变量进行主成分分析,如果相当多维度的特征根等于0,则可能有比较严重的共线性。 条件指数(Condition Idex):由Stewart等提出,当某些维度的该指标数值大于30时,则能存在共线性。 多重共线性的对策: 增大样本量,可部分的解决共线性问题 采用多种自变量筛选方法相结合的方式,建立一个最优的逐步回归方程。 从专业的角度加以判断,人为的去除在专业上比较次要的,或者缺失值比较多,测量误差比较大的共线性因子。 进行主成分分析,用提取的因子代替原变量进行回归分析。 进行岭回归分析,它可以有效的解决多重共线性问题。 进行通径分析(Path Analysis),它可以对应自变量间的关系加以精细的刻画。