1.什么是redis?
2. 缓存中间件——Memcache和redis的区别?
Memcache:
代码层次类似哈希,不支持简单数据类型,不支持分片,不支持主从分布,不支持持久化存储。
redis
数据类型丰富,支持主从分布,支持分片,支持持久化存储
3.为什么redis这么快?
100000+ qps(每秒内查询次数)
1)完全基于内存,绝大部分的请求纯粹是内存操作,执行效率高。
2)数据结构简单,对数据操作也接单
3)主线程采用单线程(io处理,io下的请求,赋值协调,集群协调),想要多核也可启用实例。
4)使用多路i/o复用模型,非阻塞io
4.什么是多路复用模型?
FD:文件描述符,一个打开的文件通过唯一的描述符进行引用,该描述符是打开文件的元数据到文件本身的映射。
传统的阻塞i/o模型:由于发现阻塞(读写不可动,不会对其他操作进行改变)一般用select系统调用,selector负责监听是否可读或可写。
redis采用的多路复用函数:eqoll/kqueue/evport/select.因地制宜,优先选择时间复杂度为O(1)的多路复用函数作为底层实现。以时间复杂度为O(n)的select作为保底。基于react设计模式监听i/o事件。
5.redis常用的数据类型?
供用户使用的数据类型
-
String:最基本的数据类型,二进制安全(jpg图片,序列化文件)
-
Hash:String元素组成的字典,适用于存储对象
-
List:列表,按照String元素插入顺序排序(大约41个成员)
-
Set:String元素组成的无需集合,通过哈希表实现,不允许重复
-
Sorted Set:通过分数为集合中的成员进行从小到大的排序
-
用于计数的HyperLogLog:HyperLogLog实际上不会存储每个元素的值,它使用的是概率算法,通过存储元素的hash值的第一个1的位置,来计算元素数量。
-
用于支持存储地理位置信息的Geo。
6.底层数据类型基础
这一部分不过多讲解
-
简单动态字符串
-
链表
-
字典
-
跳跃表
-
整数集合
-
压缩列表
-
对象
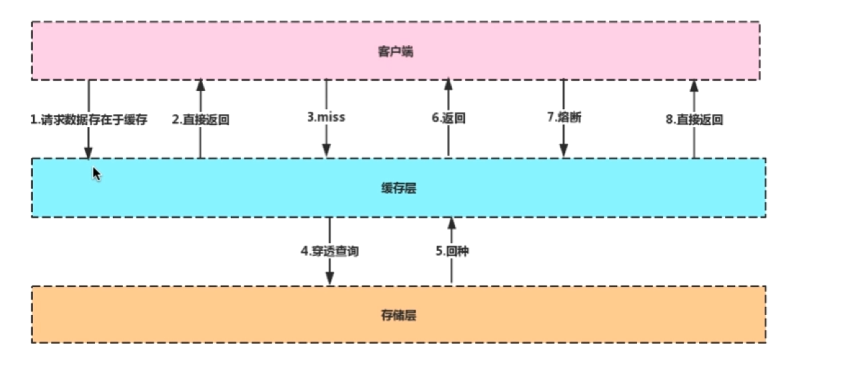
7.从海量key里查询出来某一固定前缀的key
留意细节
-
摸清数据规模,即问清楚边界
使用keys对线上业务的影响:Keys pattern :查找所有符合给定模式pattern的 key
-
Keys指令会一次性返回所有匹配的key
-
键的数量过大会使服务器卡顿
第二种方式:Scan cursor [Match pattern] [Count count]
-
基于游标的迭代器,需要基于上一次的游标延续之间的迭代过程。
-
以0作为游标开始进行一次新的迭代,知道命令返回游标0完成一次遍历。
-
不保证每次执行都返回某个给定数量的元素,支持模糊查询。
-
一次返回的数量不可控,只能是某个大概率符合count的数。
8.如何通过Redis实现分布式锁
Setnx key value:如果key不存在,则创建并复制。
-
时间复杂度:O(1)
-
返回值:设置成功,返回1;设置失败,返回0
9.如何解决Setnx长期有效的问题
Expire key seconds
-
设置key的生存时间,当key过期时(生存时间为0),会被自动删除
-
缺点:原子性得不到满足
10.如何将两者结合起来?(2.6.12)
Set key value[Ex seconds] [Px milliseconds] [Nx|xx]
-
Ex seconds:设置键的过期时间为seconds秒。
-
Px millisecond:设置键的过期时间为milliseconds毫秒。
-
Nx:只在键不存在时,才对键进行操作。
-
Xx:只在键已经存在时,才对键进行设置操作。
-
Set操作成功完成时返回OK,否则返回设置操作nil。
11.大量的key同时过期的注意事项
-
集中过期,由于清除大量的key很耗时,会出现短暂的卡顿现象。
-
解决方案:在设置key的过期时间的时候,给每个key加上随机值。
12.如何使用Redis做异步队列
-
使用List作为队列,Rpush生产消息,Lpop消费消息
-
缺点:没有等待队列有值,就能进行消费。
-
弥补:可以通过在应用层引入sleep机制去调用Lpop重试。
-
另外方法
-
Blpop key [key...] timeout:阻塞直到队列有消息或者超时。
-
缺点:只能供一个消费者消费
怎么样才能够生产一次便让多个消费者消费?
Pub/Sub模式:主题订阅者模式
-
发送者(Pub)发送消息,订阅者(Sub)接收消息。
-
订阅者可以订阅任意数量的频道。
-
缺点:消息的发布是无状态的,无法保证可达。(解决:利用KafaKa等)
-
13.Redis如何做持久化?
RDB(快照)持久化:保存某个时间节点的全量数据快照
-
SAVE 900 1 :900秒内有一行写入
-
SAVE 300 10 :300秒内有10行写入 否则从上
-
SAVE 60 10000 60秒内有10000行写入
stop-writes-on-bgsave-error yes
-
当备份进程出错时,主进程就停止写入操作了。
rdbcompression yes
-
rdb格式
-
save:阻塞Redis的服务器进程,知道rdb文件被创建完毕。
-
bgsave:Fork出一个子进程来创建rdb文件,不阻塞服务器进程(主要的方式)
-
-
自动化触发RDB持久化的方式
-
根据redis.conf配置里的SAVE m n 定时触发(用的是Bgsave)
-
主从复制时,主节点自动触发
-
执行Debug Reload
-
执行Shutdown 且没有开启AOF持久化
-
系统调用fork():创建进程,实现了Copy-on-write
-
-
缺点
-
内存数据全量同步,量大影响IO性能
-
可能会因为Redis挂掉而丢失从当前之最近一次快照期间的数据
AOF(Append-Only-File) 持久化:保存写状态
记录除了查询以外所有变更数据库状态的指令
以append的形式追加保存到AOF文件中(增量)
-
修改redis.conf appendonly yes 默认名字 appendonly.aof
-
appendfsnc 写入方式:always(只要有变更就记录) everysec(默认) no
日志重写解决AOF文件不断增大的问题?
-
调用fork()创建一个子进程
-
子进程把新的AOF写到一个临时文件里,不依赖原来的AOF文件
-
子进程持续的将新的变化写到内存和AOF里
-
主进程获取子进程重写AOF的完成信号,往新AOF同步增量变动
-
使用新的AOF文件替换掉旧的AOF文件

Redis数据的恢复
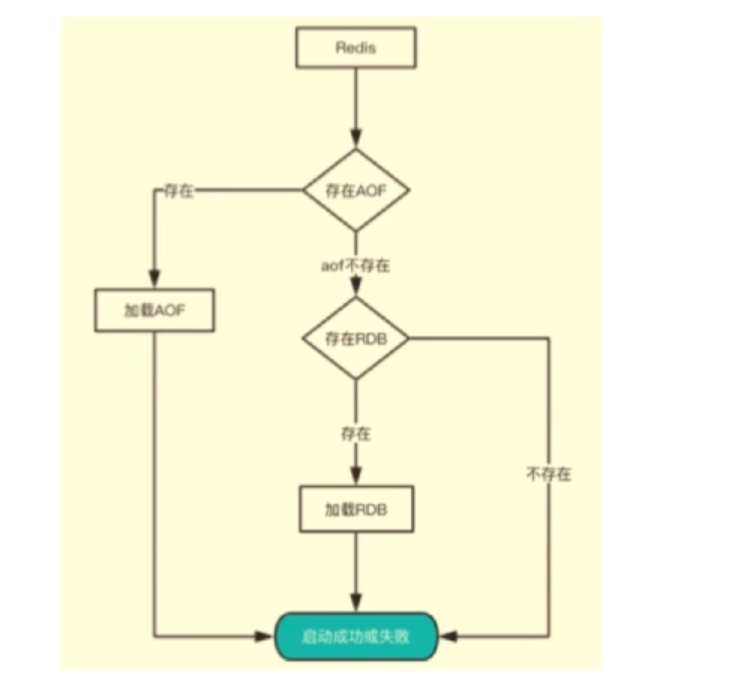
-
14.RDB和AOF的优缺点
-
RDB:
-
优点:全量数据快照,文件小恢复快
-
缺点:无法保存最近一次快照之后的数据
-
-
AOF:
-
优点:可读性高,适合保存增量数据,数据不易丢失
-
缺点:文件体积大,恢复时间长
-
15.RDB-AOF混合持久方式(Redis4.0之后 最常用的方式)
Bgsave做镜像全量持久化,AOF做增量持久化
16.Copy-On-Write
如果有多个调用者同时需要要求相同的资源(如内存或磁盘上的数据存储),他们会获得相同的指针指向相同的资源,直到某个调用者试图修改资源的内容时,系统才会真正的复制一份专用副本给该调用者,而其他调用者所见到的最初的资源保持不变。
17.使用pipeline的好处
-
pipeline和linux的管道相似
-
Redis基于请求/响应模型,单个请求处理需要一一解答
-
pipeline批量执行指令,节省多次IO往返的时间
-
有顺序依赖的指令建议分批发送
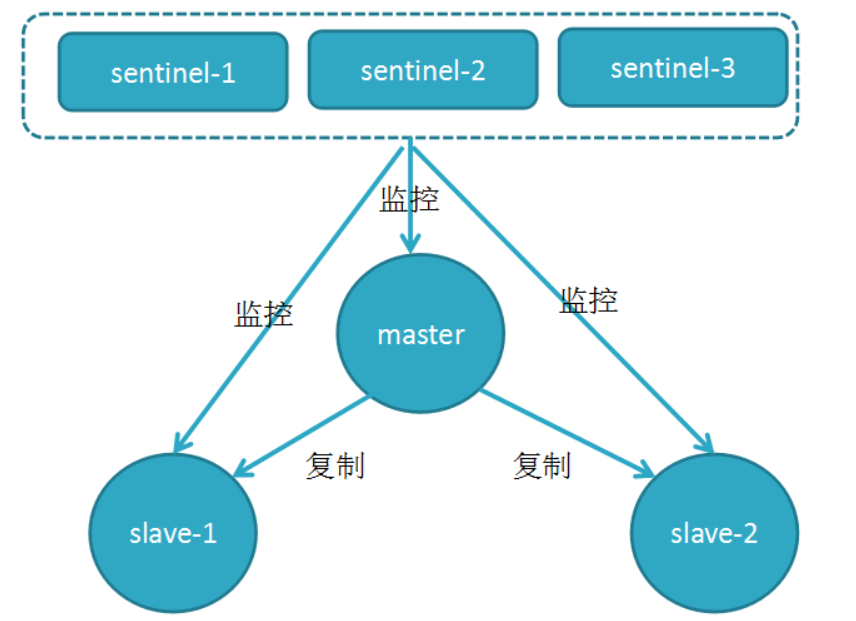
18.Redis的同步机制
主从同步原理
-
全同步过程
-
Slave发送sync指令到Master
-
master启动一个进程,将Redis中的数据快照保存到文件中
-
Master将保存数据快照期间接收到的写命令缓存起来
-
Master完成写操作后,将该文件发送给Slave
-
使用新的AOF文件替换掉旧的AOF文件
-
Master将这期间收集到的增量写命令发送给Slave端
-
-
增量同步过程
-
Master接收到用户传来的操作指令后,判断是否需要传播到Slave
-
将操作记录追加到AOF文件中
-
将操作传播到其他Slave:对齐主从库 往响应缓存写入指令
-
将缓存中的数据发送给Slave
缺点:无法保证高可用
19.解决高可用问题
引入监控机制
解决主从同步Master宕机后的主从切换问题
-
监控:检查主从服务器是否运行正常
-
提醒:通过API向管理员或者其他应用程序发送故障通知
-
自动故障迁移:主从切换
20.流言协议Gossip
在杂乱无章中寻求一致
-
每个节点都随机的与对方通信,最终所有的节点的状态达成一致
-
种子节点定期随即向其他节点发送结点列表以及需要传播的消息
-
不保证信息一定会传给所有节点,但是最终会趋于一致。
21.Redis的集群原理
-
如何从海量数据里找到所需?
-
分片:按照某种规则区划分数据,存储在多个节点上。
-
常规的按照哈希划分无法实现节点的动态增减
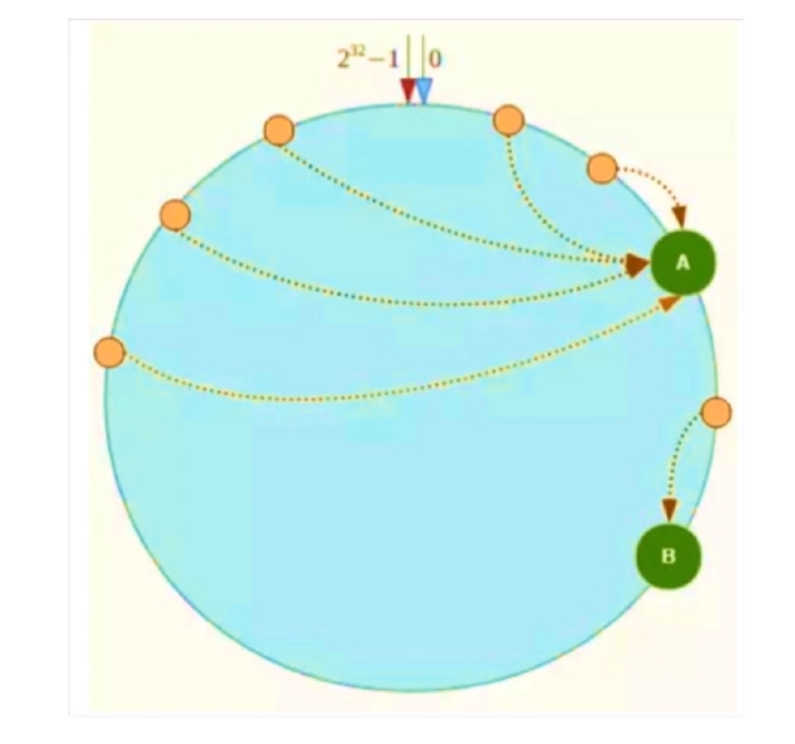
一致性哈希算法:对2的32次方取模,将哈希值空间组织成虚拟的圆环。

缺点:Hash环数据倾斜问题
-
-
解决:引入虚拟节点解决数据倾斜的问题
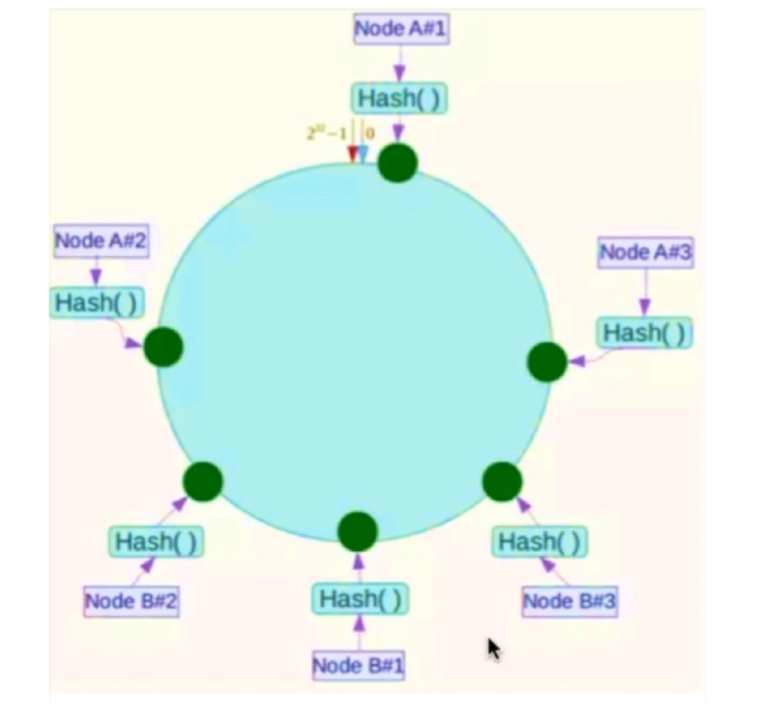
-
-