一. python的数据类型
计算机本身只认识二进制,我们要输入的是数字,字符串等等,所以是python解释器自动的帮我们识别了我们所输入的数据类型,那么数据类型又是什么?
每种编程语言里都会有一个数据类型,就是对我们常用的数据类型进行区分,想要进行数字运算,就传数字。想要拍处理文字,就传文字,python中的常用数据类型又有哪些?

可变与不可变数据类型
可变数据类型:列表list和字典dict;不可变数据类型:整型int、浮点型float、字符串型string和元组tuple
1. 数字
int(整型)
32位机器,整数的位数是32位,取值范围是-2**31~2**31-1
64位机器,整数的位数是64位,取值范围是-2**63~2**63-1
long(长整型)
python没有限制长整数数值的大小,python3自动会转成int,
float(浮点型)
就是小数
2. 字符串
在python中,带引号的字符都被认为是字符串

既然单引号,双引号,多引号都能用,他们有什么区别?
单引号与双引号没什么不一样,只是有时候需要配合使用
三引号用于多行字符
字符串可以相加或者相乘
特性:1.有序
 ‘rain’并不是覆盖了‘jack’,而是开辟了一个新的内存地址,旧的一个被python解释器定时的清空掉。
‘rain’并不是覆盖了‘jack’,而是开辟了一个新的内存地址,旧的一个被python解释器定时的清空掉。
2.不可变:
用法:(常用的有 isdigit replace find count strip center format join)
name=" aleX"
a.移除name 变量对应的值两边的空格,并输入移除有的内容
name.strip() 'aleX'
s='hello world' s+=' ' print(s) 'hello world ' #执行结果 s=' hello world' print(s) ' hello world '#执行结果 s.strip() 'hello world' #执行结果 s.lstrip() 'hello world '#执行结果 s.rstrip() ' hello world'#执行结果
b.判断name 变量对应的值是否以"al"开头,并输出结果
print(name.startswith("al")) False #执行接轨
c.判断name 变量对应的值是否以"X"结尾,并输出结果
print(name.endswith("X")) True #执行结果
d.将name 变量对应的值中的“l”替换为“p”,并输出结果
print(name.replace("l","p")) apeX #执行结果
e.将name 变量对应的值根据“l”分割,并输出结果。
print(name.split("l")) [' a', 'eX'] #执行结果
(注意到分割以后得到一个列表)
分割列
s='a b alex c' s.splitlines() ['a', 'b', 'alex', 'c'] #执行结果
f. 将name 变量对应的值变大写,并输出结果
print(name.upper())
ALEX #执行结果
g.将name 变量对应的值变小写,并输出结果
alex #执行结果
h.小写变大写,大写变小写
print(name.swapcase())
ALEX #执行结果
i.字符串是否可迭代?如可以请使用for 循环每一个元素?
for i in name:
print(i)
j.
name.center(20,'*') '********ALex********' #执行结果
name='hello world' name.ljust(50) 'hello world ' #执行结果 name.ljust(50,'-') 'hello world---------------' #执行结果
(.ljust 是从左边开始 字符串补满50哥字符)
k.判断是否为整数
'33'.isdigit() True #执行结果
'33'.isdecimal() True #执行结果
l.首字母大写,其余小写
name='hello Wrold'
name.capitalize()
'Hello world' #执行结果
m.统一变成小写
name='hello Wrold'
name.casefold()
'hello world' #执行结果
n.统计name中’o‘的个数
s.count('o') 2 #执行结果
o.name中’o‘的个数在0-5个元素的个数
s.count('o',0,5)
1 #执行结果
p.扩展tab、键
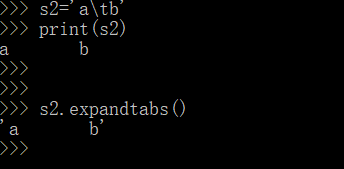 , 解释成了 那么多的空格
, 解释成了 那么多的空格
q.查找‘o’,(如果没找到会返回-1)
name.find('o') 4 #执行结果
r.格式化
s3='my name is {0}, i am {1} old' s3.format('alex','22')
s3='my name is {name}, i am {age} old' s3.format(name='alex',age='22')
s.判断是否为数字
'22'.isalnum() True
t.判断是否为字符
'ds'.isalpha() True
u.判断是否为正确的变量名
'd3_'.isidentifier() True
v.把字符串拼接起来
name=['alex','bob','alan'] ''.join(name) 'alexbobalan' ' '.join(name) 'alex bob alan' '_'.join(name) 'alex_bob_alan'
w.
s='hello world' s.zfill(40) '00000000000000000000000000000hello world'
x.生成对应表并且翻译
str_in='abcdef' str_out='!@#$%^' str.maketrans(str_in,str_out) {97: 33, 98: 64, 99: 35, 100: 36, 101: 37, 102: 94} table=str.maketrans(str_in,str_out) table {97: 33, 98: 64, 99: 35, 100: 36, 101: 37, 102: 94} s='hello world' s.translate(table) 'h%llo worl$' 'abcdAlex'.translate(table) '!@#$Al%x'
y.从左往右分‘o’,从右往左分‘o’
s='hello world' s.partitiion('o') ('hell','o','world')
s.rpartitiion('o')
('hellow','o','rld')
z.从左往右找‘o’,从右往左找‘o’
s='hello world' s.find('o') 4 s.rfind('o') 7
s.find('dad')
-1
s.rindex('o')
4
s.rindex('da')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: substring not found
3.布尔类型True / False
主要用于逻辑判断

4.列表:特性及用法(列表里可以存放任何的数据类型)

用法:
#创建 n1=['zhao','zhi','gang',3,'a',23,3,0,4,‘c’] #查询 n1[1] >>>'zhi' #对索引的补充: #(1)正数0,1,2,3.. #(2)倒数-1,-2,-3.. #(3)index(索引) eg. n1.index(2) >>>'gang' #(4)要知道有几个重复的用count. eg.n1.count(3) >>>2 #切片 >>>n1[0:3]#==n1[:3] ['zhao','zhi','gang'] >>>n1[-1:-4] [3,0,4] >>>n1[:-4] [3,0,4,‘c’] >>>n1[:7:2] #取前7个,跳一个取一个 ['zhao','gang','a',3] >>>n1[:7:3] #跳两个取一个 ['zhao',3,3] #增加 >>>n1.append('alex') #增加到末尾 n1=['zhao','zhi','gang',3,'a',23,3,0,4,‘c’,''alex] >>>n1.insert(0,'abc') n1=['abc','zhao','zhi','gang',3,'a',23,3,0,4,‘c’] #修改 >>>n1[2]='peiqi' n1=['zhao','zhi','peiqi',3,'a',23,3,0,4,‘c’] #删除 >>>n1.pop()#删除最后一个 n1=['zhao','zhi','peiqi',3,'a',23,3,0,4] >>>n1.remove(3)#删除特定值,从左往右删 n1=['zhao','zhi','peiqi','a',23,3,0,4] >>>del n1[索引值]#全局性的删除,可以批量删 #计算长度 >>>len(n1) 10
#排序
>>>a=[1333,-213131,21313,32334]
a.sort()
>>>a
[-213131, 1333, 21313, 32334]
#循环打印n1中的各个元素 for i in n1: print(i)
5.字典特性
特性:1.key-value
2.key 必须可hash,且必须为不可变数据类型,必须唯一(必须变成数字,这样不同的key有规律)(列表,字典都是可变的,不能当作key)
3.无序(没有索引,只需要key)
4.查找速度快(涉及到一个算法:折半算法,也叫二分算法)
5.可存放任意多个值,可修改,可以不唯一
a.添加
info={'stu1101':'武藤兰','stu1102':'alex','stu1103':'shanshan'}
info['stu1104']='苍井空'
info={'stu1101':'武藤兰','stu1102':alex','stu1103':'shanshan','stu1104':'苍井空'}
info.setdefaulat('rain',45)
info={'stu1101':'武藤兰','stu1102':alex','stu1103':'shanshan','stu1104':'苍井空,'rain',45}
b.查找,获取
>>>'stu1101' in info True
>>>info.get('stu1102') 'alex'
>>>info.get('shanshan222')#什么都不会返回
>>>print(info.get('shanshan222'))
None(为空)
>>>info['stu1103']
['shanshan']
>>>info['shansahn222']
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'shansahn222'
#所以一般不用get,因为他不会报错
c.删除
>>>info.pop('stu1102')#删除了这个值并且返回了这个值 ['alex'] >>>
info.popitem()#随机删除,数量少看不出来,会按顺序删除
del info['!']#全局删除
info.clear()#清空
d.多级字典的嵌套以及修改
av_place={ '欧美':{ 'www.wdwa':['免费','最大网站','质量好',] 'www.fadfffd':['免费','最大网站','质量好']} '日韩:{ 'tokyo-hot':['不好用','以及不喜欢']} '大陆':{ '1024':['免费','只来过年好']} } av_place['大陆']['1024'][1]+=',可爬下来' print(av_place['大陆']['1024']) ['免费','只来过年好',',可爬下来']
e.打印所有的key值,value值
info={'alex':[24,'IT',],'rain':[24,'HR'],'jack':22}
info.keys()
dict_keys(['alex', 'rain', 'jack'])
info.values()
dict_values([[24, 'IT'], [24, 'HR'], 22]
f.字典转成列表
info.items() dict_items([('alex', [24, 'IT']), ('rain', [24, 'HR']), ('jack', 22)])
g.字典的合并(info 里边没有对应的值就创建,有对应的值就覆盖)
info={'alex':[24,'IT',],'rain':[24,'HR'],'jack':22}
dit2={1:2,2:3,'jack':[22,'CEO']
info.update(dit2)
h,.
info={'alex': [24, 'IT'], 'rain': [24, 'HR'], 'jack': [22, 'CEO'], 1: 2, 2: 3}
info.setdefault(2,'new 2')
3
info.setdefault('test','new 2')
'new 2'
info={'alex': [24, 'IT'], 'rain': [24, 'HR'], 'jack': [22, 'CEO'], 1: 2, 2: 3, 'test': 'new 2'}
#如果有2 这个值,拿回来,如果没有这个值,创建一个,赋成’new2‘
i.批量生成一个字典,并且赋值很多key
info.fromkeys(['A','B','C'],'alex') {'A': 'alex', 'B': 'alex', 'C': 'alex'}
j.字典的循环
info={'alex': [24, 'IT'], 'rain': [24, 'HR'], 'jack': [22, 'CEO'], 1: 2, 2: 3, 'test': 'new 2'}
for k in info:
print(k)
alex
rain
jack
1
2
test #打印的是key
for k in info:
print(k,info[k])
alex [24, 'IT']
rain [24, 'HR']
jack [22, 'CEO']
1 2
2 3
test new 2
for k,v in info.items():
print(k,v)
alex [24, 'IT']
rain [24, 'HR']
jack [22, 'CEO']
1 2
2 3
test new 2 #比较低效,需要先转化成列表,再循环,一般不用
6.集合
特点:集合是一个无序的,不重复的数据类型(组合)
1.去重,把一个列表变成集合,就自动去重
2.关系测试,测试两组数据之间的交集,并集,差集等关系
#大括号是基本的语法 s={} type({}) <class 'dict'> s={1} type(s) <class 'set'> s={1,2,3,4} >>>s {1, 2, 3, 4} s={1,2,3,4,3,2,6} >>>s {1, 2, 3, 4, 6} #可以把列表,元组改成集合 l=[1,2,3,4,5,2,3] set(l) {1, 2, 3, 4, 5} s=set(l) >>>s {1, 2, 3, 4, 5}
s={1,2,3,4,5}
#增加
s.add(2)
{1, 2, 3, 4, 5}#2存在,所以放不进去
s.add(6)
{1, 2, 3, 4, 5,6}
#删除
s.pop() #随机删除,只要数据量足够大
s.remove(6)
{1, 2, 3, 4, 5}#不存在的话会提示错误,有的话直接删除
s.discard(6)#如果不存在不会提示错误,有的话直接删
#联合,可以加多个值
s.update(1,2,3,4,5)
>>>s
{1, 2, 3, 4, 5}
#清空
s.clear()
#把两个的差集取出来赋值给其中一个
s1={-1,1,3,5,7}
s2={1,2,3,4}
s1.difference_update(s2)
>>>s1
{5,7,-1}
>>>s2
{1,2,3,4}
集合的关系测试:
如何快速地完成两个数据集之间的交集,并集,差集。。?
#引例
#找出同时买了iPhone7和iphone8的人
iphone7=['alex','rain','jack','old_diver'] iphone8=['alex','shanshan','jack','old_boy',] both_list=[] for name in iphone8: if name in iphone7: both_list.append(name) print(both_list) ['alex', 'jack']
#交集
iphone7={'alex','rain','jack','old_diver'} iphone8={'alex','shanshan','jack','old_boy'} #买了iphone也买了iphone8的人 iphone7.intersection(iphone8) {'alex', 'jack'} iphone7&iphone8 {'alex', 'jack'}
#判断两个集合是否相交(当数据非常大时,可以先判断一下)
iphone7.isdisjoint(iphone8)
False
#差集
iphone7={'alex','rain','jack','old_diver'}
iphone8={'alex','shanshan','jack','old_boy'}
#买了iphone7没买8的人
iphone7.difference(iphone8)
{'old_diver', 'rain'}
iphone7-iphone8
{'old_diver', 'rain'}
#买了8没买7的人
iphone8.difference(iphone7)
{'shanshan', 'old_boy'}
#并集(两个列表加起来) iphone8.union(iphone7) {'shanshan', 'jack', 'rain', 'old_diver', 'old_boy', 'alex'} iphone8 | iphone7 # | 管道符 {'shanshan', 'jack', 'rain', 'old_diver', 'old_boy', 'alex'}
#对称差集,把没有交集的取出来 #只买了iphone7 or 只买了 iphone8 的人 iphone7={'alex','rain','jack','old_diver'} iphone8={'alex','shanshan','jack','old_boy'} iphone8.symmetric_difference(iphone7) {'shanshan', 'rain', 'old_diver', 'old_boy'} iphone7^iphone8 {'old_diver', 'shanshan', 'old_boy', 'rain'}
#判断子集和超集 s1={1,2,3,4} s2={1,2,3,4,5,6} s1.issubset(s2) True
s1<=s2 True
s1.issuperset(s2) Flase
s1>=s1
Flase
s2.issuperset(s1) True
s2>=s1
True
二. 进制的换算
二进制,01
八进制,01234567(基本不用)
十进制,0123456789
十六进制,0123456789ABCDEFASCII表对应转换:
chr()
ord()
十进制转8,16进制的语法
oct(),8进制
hex(),16进制
16进制介绍:

2进制转16进制:取四合一法,以小数点为分界线,分别向左和向右每四位取一位,如果最边上少一位,补0
1 0 1 1 1 0 0 1 1 0 1 1 . 1 0 0 1
B 9 B 9
16进制的表示; BH后缀
0X53前缀
练习题:
一. 购物车

products=[['iphone8',6888],['macpro',14800],['小米',2499],['coffee',31],['book',80],['nike',1200]] shopping_car=[] while True: print('------------商品列表-------------') for index,i in enumerate(products): print('%s. %s %s'%(index,i[0],i[1])) n1=input('输入你想买的商品编号:') if n1.isdigit(): n1=int(n1) if n1>0 and n1<len(products): shopping_car.append(products[n1]) print('%s 已加入到你的购物车'%(products[n1])) else: print('你选择的商品不存在') elif n1=='q': if len(shopping_car)>0: print('---------你购买的商品有----------') for index,i in enumerate(shopping_car): print('%s. %s %s'%(index,i[0],i[1])) break
二. Python-列表嵌套字典-名片管理系统(适合刚学习完字典和列表的同学练手)
当你存取的数据类型都是一样的时候,使用列表,当你存取的数据类型不一样时就用字典。这里说明一下数据类型不一样不是指整形或者字符型
举个例子:如果你需要存很多人的姓名,仅仅这一个属性,就用列表来进行处理,当你要存取不仅仅是人名,包括年龄,性别,国籍等等这些信息时,这时候用字典是最合适的。
1、列表里面嵌套字典,怎么实现删除

这是一个names列表。怎么实现输入姓名后,可以删除这条字典,当输入pjj,删除整个字典,再次打印names时只有后面的一条信息。
names = [{'name':'pjj','age':18},{'name':'zy','age':20}]
while True:
# 删除
del_name = input("请输入要删除的名字:")
find_flag = False
for line in names:
if line['name'] ==del_name:
find_flag = True
names.remove(line)
if find_flag:
print("已删除!")
else:
print("输入的用户名不存在")
print(names)
2、列表里面嵌套字典,怎么实现修改,当输入pjj,判断pjj是否存在,如果存在则进行修改!
names = [{'name':'pjj','age':18},{'name':'zy','age':20}]
while True:
# 修改
old_name = input('请输入要修改的姓名:')
flag = 0
for line in names:
if line['name'] == old_name:
new_name = input('请输入修改的姓名:')
new_age = input('请输入修改的年龄:')
line['name'] = new_name
line['age'] = int(new_age)
flag = True
break
if flag:
print("已修改!")
else:
print('输入的用户不存在!')
print(names)
解决了上述2个问题后!就开始写这个名片管理系统了!
需求:
当用户输入对应的序号,实现相应的功能(总共6个)
1:添加一个新的名片
2:删除一个名片
3:修改一个名片
4:查询一个名片
5:显示所有的名片
6:退出系统
# Author:夜猫
# 1打印功能提示
print('=' * 50)
print('名字关系系统 V2.0')
print('1:添加一个新的名片')
print('2:删除一个名片')
print('3:修改一个名片')
print('4:查询一个名片')
print('5:显示所有的名片')
print('6:退出系统')
print('=' * 50)
# 用来存储名片
card_infors = []
while True:
# 2获取用户选择
num = input('请输入操作序号:')
if num.isdigit():
num = int(num)
if num == 1:
new_name = input('请输入名字:')
new_qq = input('请输入QQ:')
new_weixin = input('请输入微信:')
new_addr = input('请输入新的住址:')
# 定义一个新的字典,用来存储一个新的名片
new_infor = {}
new_infor['name'] = new_name
new_infor['qq'] = new_qq
new_infor['weixin'] = new_weixin
new_infor['addr'] = new_addr
# 将一个字典,添加到列表中
card_infors.append(new_infor)
#print(card_infors) # for test
elif num == 2:
del_name = input("请输入要删除的名字:")
find_flag = False
for line in card_infors:
if line['name'] == del_name:
find_flag = True
card_infors.remove(line)
break
if find_flag:
print("已删除!")
else:
print("输入的用户名不存在")
# print(card_infors) for test
elif num == 3:
old_name = input('请输入要修改的姓名:')
flag = 0
for line in card_infors:
if line['name'] == old_name:
new_name = input('姓名:')
new_qq = input('年龄:')
new_weixin = input('微信:')
new_addr = input('住址:')
line['name'] = new_name
line['qq'] = new_qq
line['weixin'] = new_weixin
line['addr'] = new_addr
flag = True
break
if flag:
print("已修改!")
else:
print('输入的用户不存在!')
elif num == 4:
find_nmae = input("请输入要查找的姓名:")
find_flag = 0 # 默认表示没有找到
for temp in card_infors:
if find_nmae == temp['name']:
print('%s %s %s %s' % (temp['name'], temp['qq'], temp['weixin'], temp['addr']))
find_flag = 1 # 表示找到了
break
# 判断是否找到
if find_flag == 0:
print('没有找到')
elif num == 5:
print("姓名 QQ 微信 住址 ")
for temp in card_infors:
print('%s %s %s %s ' % (temp['name'], temp['qq'], temp['weixin'], temp['addr']))
elif num == 6:
break
else:
print('输入有误!请重新输入')
continue
print('')
else:
print("输入错误,请重新输入!")
info={'stu1101':'武藤兰','stu1102':alex','stu1103':'shanshan','stu1104':'苍井空'}
info.setdefaulat('rain',45)