一、概述
在之前的文章中,一般是抓取某个页面信息。那么如何抓取一整个网站的信息呢?
想像一下,首先我们需要解析一个网站的首页, 解析出其所有的资源链接(ajax方式或绑定dom事件实现跳转忽略),请求该页面所有的资源链接, 再在资源链接下递归地查找子页的资源链接,最后在我们需要的资源详情页结构化数据并持久化在文件中。这里只是简单的介绍一下全站抓取的大致思路,事实上,其细节的实现,流程的控制是很复杂的。
下面我来演示一下,如何抓取一个个人网站的所有文章。
二、页面分析
以yzmcms博客为例,网址:https://blog.yzmcms.com/

可以看到,首页有几个一级标题,比如:首页,前端,程序...
那么真正我们需要抓取的,主要要3个标题,分别是:前端,程序,生活。这里面都是博客文章,正是我们需要全部抓取的。
一级标题
//ul/li[@class="menu-item menu-item-type-custom menu-item-object-custom menu-item-has-children"]/a/text()
效果如下:

二级标题
先打开前端分类,链接:https://blog.yzmcms.com/qianduan/
它主要3个二级分类
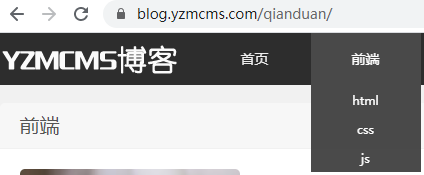
匹配规则
//li[@class="menu-item menu-item-type-custom menu-item-object-custom current-menu-item menu-item-has-children"]/ul/li/a/text()
效果如下:

分页数
我需要获取分页数,比如:5

规则:
//div[@class="pages"]/span/strong[1]/text()
效果如下:

页面信息
打开某个二级分类页面后,默认会展示10篇文章,我需要获取标题,作者,创建时间,浏览次数
标题
以标题为例
//div[@class="content"]/article//h2/a/text()
效果如下:

其他的,比如作者之类的信息,在下文中的代码中会有的,这里就不多介绍了。
全站爬取流程
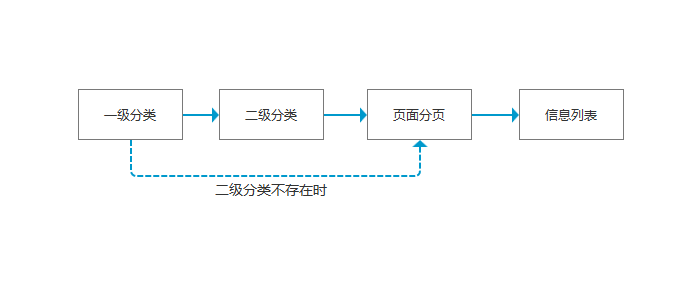
说明:
默认流程是:一级分类-->二级分类-->页面分页-->信息列表。
当一级分类下,没有二级分类时,就直接到页面分页-->信息列表。
通过这样,就可以抓取所有文章信息了。
三、项目演示
新建项目
打开Pycharm,并打开Terminal,执行以下命令
scrapy startproject personal_blog
cd personal_blog
scrapy genspider blog blog.yzmcms.com
在scrapy.cfg同级目录,创建bin.py,用于启动Scrapy项目,内容如下:
#在项目根目录下新建:bin.py from scrapy.cmdline import execute # 第三个参数是:爬虫程序名 execute(['scrapy', 'crawl', 'blog',"--nolog"])
创建好的项目树形目录如下:
./ ├── bin.py ├── personal_blog │ ├── __init__.py │ ├── items.py │ ├── middlewares.py │ ├── pipelines.py │ ├── settings.py │ └── spiders │ ├── blog.py │ └── __init__.py └── scrapy.cfg
修改blog.py


# -*- coding: utf-8 -*- import scrapy from scrapy import Request # 导入模块 from personal_blog.items import PersonalBlogItem class BlogSpider(scrapy.Spider): name = 'blog' allowed_domains = ['blog.yzmcms.com'] # start_urls = ['http://blog.yzmcms.com/'] # 自定义配置,注意:变量名必须是custom_settings custom_settings = { 'REQUEST_HEADERS': { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.75 Safari/537.36', } } def start_requests(self): print("开始爬取") r1 = Request(url="https://blog.yzmcms.com/", headers=self.settings.get('REQUEST_HEADERS'), ) yield r1 def parse(self, response): print("返回响应,获取一级分类") # 获取一级分类 category_name_list = response.xpath( '//ul/li[@class="menu-item menu-item-type-custom menu-item-object-custom menu-item-has-children"]/a/text()').extract() print("category_name_list", category_name_list) # 获取一级分类url category_url_list = response.xpath( '//ul/li[@class="menu-item menu-item-type-custom menu-item-object-custom menu-item-has-children"]/a/@href').extract() print("category_url_list", category_url_list) # 去除最后2个分类,因为它不是博客文章 for i in range(2): category_name_list.pop() category_url_list.pop() # 构造字典 category_dict = dict(zip(category_name_list, category_url_list)) # category_dict = {"生活":"https://blog.yzmcms.com/shenghuo/"} print("category_dict",category_dict) for k, v in category_dict.items(): # print(k,v) add_params = {} add_params['root'] = k add_params['root_url'] = v # 注意,这里要添加参数dont_filter=True,不去重。当二级分类为空时,下面的程序,还会调用一次。 yield Request(url=v, headers=self.settings.get('REQUEST_HEADERS'), callback=self.get_children, dont_filter=True,cb_kwargs=add_params) # break def get_children(self, response,root,root_url): """ 获取二级分类 :param response: :param root: 一级分类名 :param root_url: 一级分类url :return: """ print("获取二级分类") try: children_name_list = response.xpath('//li[@class="menu-item menu-item-type-custom menu-item-object-custom current-menu-item menu-item-has-children"]/ul/li/a/text()').extract() print("root",root,"children_name_list",children_name_list) # 子分类url children_url_list = response.xpath( '//li[@class="menu-item menu-item-type-custom menu-item-object-custom current-menu-item menu-item-has-children"]/ul/li/a/@href').extract() print("root", root, "children_url_list", children_url_list) children_dict = dict(zip(children_name_list,children_url_list)) print("children_dict",children_dict) for k, v in children_dict.items(): print("kv",k,v) add_params = {} add_params['root'] = root add_params['root_url'] = root_url add_params['children'] = k add_params['children_url'] = v yield Request(url=v, headers=self.settings.get('REQUEST_HEADERS'), callback=self.get_page, cb_kwargs=add_params) # break # 如果子分类为空时 if not children_name_list: print("子分类为空") add_params = {} add_params['root'] = root add_params['root_url'] = root_url add_params['children'] = None add_params['children_url'] = None yield Request(url=root_url, headers=self.settings.get('REQUEST_HEADERS'), callback=self.get_page, cb_kwargs=add_params) except Exception as e: print("获取子分类错误:",e) def get_page(self, response, root,root_url,children,children_url): """ 获取分页,不论是一级还是二级 :param response: :param root: 一级分类名 :param root_url: 一级分类url :param children: 二级分类名 :param children_url: 二级分类url :return: """ print("获取分页") # 获取分页数 # //div[@class="pages"]/span/strong[1]/text() try: page_num = response.xpath('//div[@class="pages"]/span/strong[1]/text()').extract_first() print(root,root_url,children,children_url,"page_num", page_num) # 如果二级分类为空时 if not children: add_params = {} add_params['root'] = root yield Request(url=root_url, headers=self.settings.get('REQUEST_HEADERS'), callback=self.get_list_info, cb_kwargs=add_params) for i in range(1,int(page_num)+1): # 当二级分类为空时 if not children_url: url = "{}list_{}.html".format(root_url,i) else: url = "{}list_{}.html".format(children_url,i) print("url",url) add_params = {} add_params['root'] = root add_params['children'] = children yield Request(url=url, headers=self.settings.get('REQUEST_HEADERS'), callback=self.get_list_info, cb_kwargs=add_params) # break except Exception as e: print("获取分页错误:",e) def get_list_info(self, response, root,children): """ 获取页面信息,比如:标题,作者,创建时间,浏览次数 :param response: :param root: 一级分类名 :param children: 二级分类名 :return: """ print("获取页面信息") # title = response.xpath('//h2/a/text()').extract_first() # autho = response.xpath('//article/p/span[3]/text()').extract() node_list = response.xpath('//div[@class="content"]/article') # print("node_list",node_list) for node in node_list: try: title = node.xpath('.//h2/a/text()').extract_first() print("title",title) author = node.xpath('.//p/span[1]/text()').extract() if author: author = author[1].strip() print("author",author) create_time = node.xpath('.//p/span[2]/text()').extract() if create_time: create_time = create_time[1].strip() print("create_time",create_time) # 浏览次数 hits_info = node.xpath('.//p/span[3]/text()').extract() hits = 0 if hits_info: hits_info = hits_info[1].strip() cut_str = hits_info.split('次浏览') hits = cut_str[0] print("hits",hits) item = PersonalBlogItem() item['root'] = root item['children'] = children item['title'] = title item['author'] = author item['create_time'] = create_time item['hits'] = hits yield item except Exception as e: print(e)
修改items.py
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # https://docs.scrapy.org/en/latest/topics/items.html import scrapy class PersonalBlogItem(scrapy.Item): # define the fields for your item here like: root = scrapy.Field() children = scrapy.Field() title = scrapy.Field() author = scrapy.Field() create_time = scrapy.Field() hits = scrapy.Field()
修改pipelines.py
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html import json class PersonalBlogPipeline(object): def __init__(self): # python3保存文件 必须需要'wb' 保存为json格式 self.f = open("blog_pipline.json", 'wb') def process_item(self, item, spider): # 读取item中的数据 并换行处理 content = json.dumps(dict(item), ensure_ascii=False) + ', ' self.f.write(content.encode('utf=8')) return item def close_spider(self, spider): # 关闭文件 self.f.close()
修改settings.py,应用pipelines
ITEM_PIPELINES = { 'personal_blog.pipelines.PersonalBlogPipeline': 300, }
执行bin.py,启动爬虫项目,效果如下:
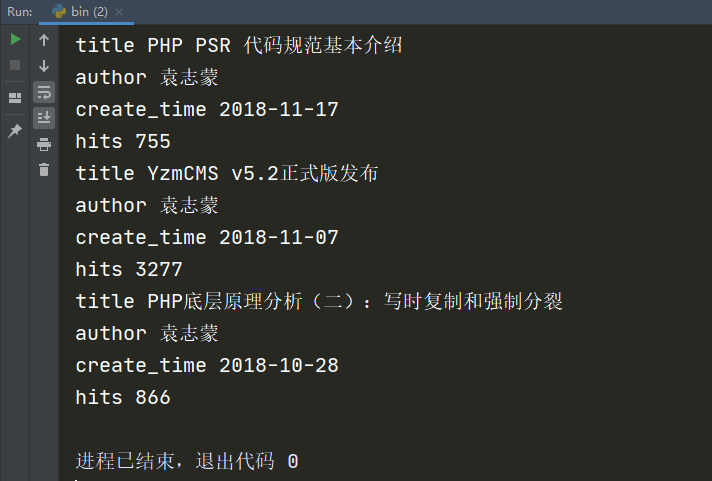
查看文件blog_pipline.json,内容如下:

注意:本次访问的个人博客,可以获取到207条信息。