分享最近学习 Go 语言的心得和体会,适合有编程基础的人,因为这里只做经验性的总结概述,不做基础教学的入门知识讲解,如果想要学习编程语言的基础知识,请出门左转进入官方文档,查看基础教学文档。
Go 概览
Go 的特征
我经常说要学一样东西,首先要搞清楚它为什么会出现? 解决了什么问题 ?
只要了解这些底层的根本问题,你才会有持续的动力深入学习,而不是盲目跟风和三分钟热度。
Go 语言是 google 在 2009年11月发布的项目,在编程语言里面算是非常年轻的小伙子。
至于 Go 语言的诞生和历史,大家可以看看这篇文章:三分钟了解 Go 语言的前世今生
我个人认为 Go 的诞生是有时代的必要性,因为她主要解决主要是解决了:
- 动态语言的性能和弱类型问题
- 静态语言的开发效率和复杂度,还有并发问题
我们都知道 Google 是世界上数据量最大的公司,Go 语言的轻量级线程设计,也帮助 Google 降低运算和并发计算的成本,这也是 Go 语言能诞生的一个重要目的。
在数据爆炸的今天,Go 语言重新平衡了开发效率和运行性能,所以 Go 会在未来十年,都是最重要的编程语言
关于 go 的定位,大家看下图可能会更清晰:
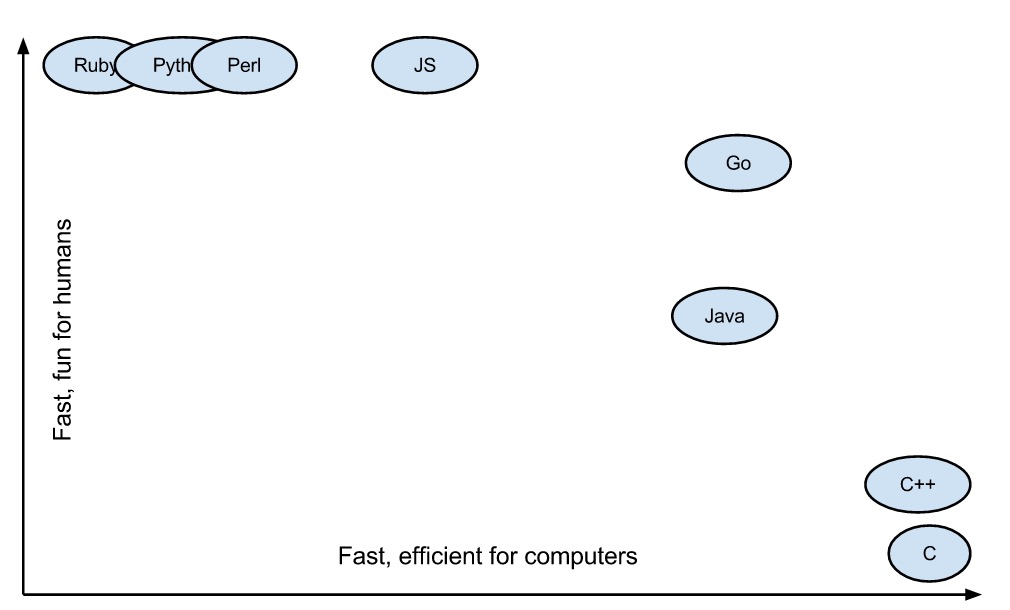
Go 的设计理念
刚接触这门语言的时候,能感受到它的设计者是经过认真思考的,从不同语言迁移过来的开发者,可以从 Go 身上看到很多其他语言的影子,因为设计者借鉴了许多其他语言的设计,但是它也非常的克制,不是完全照搬,而且非常精准的把优秀并且使用的设计融入到 Go 当中,将很多不实用且复杂的设计直接剔除。
虽然 Go 出自名门,你从 Go 身上看不到什么学院派的影子,没有多余的设计,没有复杂的概念,处处可见的 简单,实用 的设计理念,因为它的创造者的理念是:
只有通过设计上的简单性,系统才能在增长的过程中保持稳定和自洽
Go 另外还有一个特点区别于其他语言的就是,Go 语言为了追求代码可读性,可能是第一个将代码风格在编译器层面做出强制要求的语言。例如:
- 首字母大写代表
public,代表导出类型,外部可访问 - 首字母小写代码
private,代表非导出类型,仅内部可访问 - 还有对
{}换行的限制, - 编译层面就不允许出现无用变量
- 等等&……
Go 对于动态语言:
写过动态语言类似 Ruby,Python 的开发者,最头痛的应该就是类型问题,因为不确定类型,导致很多问题在编译期无法被发现,直接 runtime 的时候才能暴露出现,处理成本极高。Go 语言提供简单够用的类型系统,对于动态语言开发者不会有太大的手上成本,也帮助了动态语言的开发者解决大多数类型问题。
Go 对于静态语言:
Go 语言并没有去照搬 C++ 和 Java 那套超级复杂的类型系统,Go 放弃了大量的 OOP 特性,不支持继承和重载,对于 Java/C++ 等主流 OOP 编程语言,Go 可能也是一个彻头彻尾的异类,但是不要怀疑 Go 也是一门面向对象的编程语言,只是他在用自己理解方法,一种不同寻常的方式来解释面向对象,它的特征如下:
- 它没有继承、甚至没有类
- 没有继承,通过组合来完成继承
- 类型和接口都是非侵入式(无需声明接口的实现)
至于 Go 其他语言的区别,可以单独列出一篇文章,这里暂时不深入讨论了……
Go 语法简介
短赋值语句、递增语句
符合 Java 程序员的习惯、Go 支持短赋值语句、递增语句,下面简单看一个示例即可:
x := 0
x += 5
fmt.Print(x) // x = 5
x++
fmt.Print(x) // x = 6
x--
fmt.Print(x) // x = 5
Go 虽然是静态编译型语言,但是拥有很多动态语言才有的语法特性,比如批量赋值、变量交换,示例:
// 批量赋值
x, y, z := 1, 2, 3
// 交换变量
x, y = y ,x
Java 程序员应该很羡慕这种交换变量的写法,因为在 Java 中想要交换变量必须要声明一个很别扭的 tmp 临时变量才能实现变量的交换
Go 只支持 for 一种循环语句(减少心智负担)
// for 格式
for init; condition; post{
// 循环逻辑
}
for i := range ary {
// for range 用于遍历 slice 的快捷方法
}
初体验
Go 命名规范
不同于其他语言,Go 中的函数、变量、常量、类型和包都遵循一个简单和统一的原则:
- 名称开始是一个 Unicode 字符即可,区分大小写
- 例如:HeapSort 和 heapSort 是不同的名称
还有就是上面说到的,通过大小写的命名规范,直接把 private 和 public 权限声明的关键字这种并无很大作用的关键字给移除了,这种在不改变功能的前提下做减法,可谓是刀法快准狠
另外在 Go 官方的 Demo 和文档来看, Go 是比较推崇简短的命名原则,有以下两点:
- 如果作用域越长,那么命名就应该越清晰(也就是越长)
- Go 是推崇驼峰命名法的,而不是 C 语言里面的下划线分割法
关键字
我们先看一组数据对比:
- C++ 关键字数量 62 个
- Java 关键字数量 53 个
- Go 关键字数量 25 个
从关键字的数量上,也可以看得出 Go 语言的设计者的克制,对简单设计哲学的践行。也降低学习成本和学习 Go 语言的心智负担,是一门对于初学者非常友好的语言
变量表达式
总结一下 Go 其实只有 4种可声明的类型,主要如下:
- 变量:通过
var或者:=声明 - 常量:通过关键字
const声明 - 类型:通过关键字
type声明 - 函数:通过关键字
func声明
变量的标准声明格式是:
var name type = expression
// 上面声明方式很清晰,但是很啰嗦,平时很少用,通常使用短变量的声明格式
// 如下:
name := expression // 短变量可以通过 expression 自动推导 name 的类型
短变量声明格式短小,灵活,所以是平时很常用的声明方式。
另外在 Go 语言中,变量,常量都可以通过以下方式进行批量声明:
var (
...
)
const (
...
)
如果变量没有初始化表达式,例如 var name int,那么会触发 Go 语言的零值机制(Default Value),具体每种类型对应的零值,大家可以自行 Google,这里就不长篇大论了。
通过零值其实可以明白:Go 里面不存在没有初始化的变量,这也保证了 Go 语言的健壮性,不容易出现低级错误
引用传递和值传递
熟悉 Go 语言基础的都知道 Go 的引用传递在不加任何修饰符的情况下,默认是值传递,为什么要这样设计呢 ?
因为这样的设计会为 Go 语言的垃圾回收带来性能上的提升,值传递可以最大化的减少变量的逃逸行为,变量会最大概率的被分配到栈上,栈上分配的变量是无需等待 GC 的回收,还可以减少堆内存的占用和 GC 的压力,倒不是要大家去学习垃圾回收的工作原理,或者特别去关心变量的逃逸行为,但是对于变量的生命周期还是要搞清楚的。
在 Go 里面通过表达式的 &variable 可以获取该变量的指针,通过 *pointer 可以获取该指针变量的值,这是众所周知的事情,所以在 Go 里面想要传递引用也是很简单的事情,并且使用指针可以在无需知道变量名字的情况下,读取和更新变量。
指针是可以比较的,相同值的指针必然相同,我们看一段代码:
p := 0 // 声明类型
&p != nil // true, 比较指针,说明 p 当前指向一个变量
var x, y int // 声明类型, default value 0
&x == &x // true, 相同指针结果必然相等
&x == &y // false,指针不同,结果不相等
函数参数也可以通过 * 表示当前参数的传递类型,例如函数: func incr(p *int) 表示当前 p 参数是指针传递,不过多年编程经验来看,这样引用传递过多的话,可能你的程序库庞大后,或者你想找到一个被经常传递的引用变量在哪里被修改的,你可能会很难找到和定位,这可能是传递指针所带来的一个副作用吧
基本类型
Go 的基本类型也很少,常用的也就是:整型(int)、浮点(flora)、布尔(bool)、字符串(string)、复数(complex),和 Java 的不同之处在于,string 在 Go 里面是内置的基本数据类型,在 Java 中确实一个实体类。不过我个人感受 String 本就应该是基本数据类型。用类组合 byte[] 来实现字符串似乎还是有些别扭。
整数
这里主要区分有符号整数、无符号整数。
不过无符号因为无法表达负数,所以平时使用场景比较少,往往只用于数据库自增 ID,位运算和特定算数,实现位集,解析二进制等,这里要了解平时还是使用 int 等有符号整数比较多就好,具体区分如下:
- 有符号整数:int8、int16、int32、int64
- 无符号整数:uint8、uint16、uint32、uint64
Int 后面的数字代表类型的大小,也就是 2N 次幂,使用明确的类型可以更好的利用内存空间,Go 语言的所有二元操作符和其他无言别无二致,另外 Go 不支持三元表达式,原因我也不知道为什么,个人猜测可能是因为考虑函数多返回值的原因,但是 if/else 这样的代码就要写很多了,感觉还是挺呕心的。
浮点数 float32、float64 也没什么好讲的,都很简单,只有一个原则,如果想要减少浮点运算误差,尽量推荐使用 float64,因为 float64 有效数是 15 位,差不多是 float32 的 3倍
复数(complex)目前看上去很少用,后面用到再聊聊……
布尔类型(bool)除了名字短点,基本和其他语言没有区别,跳过
字符串
可以简单聊聊,string 是 Go 的基本数据类型,这点和 Java 的类型有些不同,但是相同点还是蛮多的,例如:
- 都可以通过加号(+)拼接字符串,但是返回新的字符串(但性能敏感慎用)
不知道是不是 Go 语言设计者同时也是 UTF-8 编码的设计者(Rob、Ken),所以 Go 语言源文件默认就是 UTF8 编码,可以预见到使用 Go 语言会大大减少乱码问题。
另外介绍几个 Go 常用处理字符的工具包,如下:
- strings:提供搜索、比较、替换等平时常用的字符操作函数
- bytes:顾名思义,提供操作 byte[] 类型的函数
- strconv:提供布尔,整数,浮点等其他类型转为 string 的服务
- unicode:提供对于文字符号特性判断的函数服务
命名返回值
Go 语言可以在返回类型中,给返回值命名,所以在 return 中就无需再显示返回,代码如下
func split(sum int) (x, y int) {
x = sum + 3
y = sum + x
return // 将变量直接返回
}
func main() {
fmt.Println(split(50)) // res:53, 103
}
不过这种灵活的写法,会对影响代码的可读性,不利于团队协作。不推荐使用。
从代码可读性和团队协作的角度来说,建议写成如下方式,代码更可读,如下:
func split(sum int) (int, int) {
x := sum + 3
y := sum + x
return x, y
}
func main() {
fmt.Println(split(50)) // res:53, 103
}
常量
值得注意的是,常量使用 const 关键字,任何基本数据类型都可以声明为常量,但是不能使用 := 语法声明,示例:
const Pi = 3.14
const World = "世界"
const Truth = true
跟 import 类似可以批量声明,这样可以减少很多 const 重复声明,,如下:
const (
Pi = 3.14
World = "世界"
Truth = true
)
循环
只有 for 一种循环,简单用法如下:
sum := 0
for i := 0; i < 10; i++ {
sum += i
}
Go语言的循环和 Java、Javascript 的区别主要在于没有小括号,但是大括号则是必须的
很多编程语言都有 while 语句,但是在 Go 里面也是可以用 for 替代,如下:
sum := 1
for sum < 100 {
sum += 1 // sum 累积 100 次
}
// out: 100
if
跟 for 类似,if 也是没有小括号的,其他方面和常见的语言差不多,如下:
if x < 0 {
fmt.Println('x < 0')
}
比较有特色的是,Go语言的 if 可以在执行表达式之前,执行一段声明语句,如下:
func conditon(x, n, lim float64) float64 {
// 初始化 v 变量,在进行表达式判定
// 值得注意的是:v 是 if 条件内的局部变量,外部无法调用
if v := x * n; v < lim {
return v
}
return lim
}
condition(3, 5, 10) // out: 10
switch
switch 是简化一连串 if else 的利器,不过 Go 语言的 switch 和其他语言差别不大,这里就不多说了。。
延迟函数 defer
算是 Go 语言的特色,Go 的语言运行机制保证它会在函数返回后执行,所以通常用于关闭资源(网络/文件/IO)等操作,如下:
defer fmt.Println("end") // 最先声明,但会在最后执行
fmt.Println("hello")
fmt.Println("Phoenix")
//out:
//hello
//Phoenix
//end
值得注意的是,在使用 defer 声明函数被压力栈中,所以有多个 defer 声明会根据 FIFO 先进先出的顺序执行,如下
defer fmt.Println("1")
defer fmt.Println("2")
defer fmt.Println("3")
fmt.Println("done")
// done
// 3
// 2
// 1
指针
Go 通过 & 可以直接操作指针,并且通过 * 操作符可以通过指针修改引用值,如下:
x, y = 100, 200
p := &x // get i 指针
*p = 21 // 通过指针修改引用值
fmt.Println(x) //out x = 21
slice 切片
是 Go 语言比较常用的动态数组,值得注意的是它的传递是引用的,任何对切出来的变量进行修改,都会影响到原本的值,代码如下:
names := []string{
"金刚",
"哥斯拉",
"怪兽",
"奥特曼"
}
a := names[0:2] // out:[金刚,哥斯拉]
b := names[1:3] // out:[哥斯拉,怪兽]
b[0] = "XXX"
fmt.Println(a) // out:[金刚,XXX]
fmt.Println(b) // out:[XXX,怪兽]
fmt.Println(names)// out:[金刚,XXX,怪兽,奥特曼]
备注:声明一个 slice 就像声明一个没有长度的数组
slice 的快捷切片写法:
s := []int{2, 3, 5, 7, 11, 13}
s = s[1:4] // out: 3, 5, 7
// s[0:2] 的简写
s = s[:2] // out: 3, 5
s = s[1:] // out: 5
在 slice 中 length 和 capacity 是分开存储,例如上面改变长度,并不会改变容量,在 slice 中的长度和容量可以通过函数 len() 和 cap() 获取,参考以下几行代码:
s := []int{2, 3, 5, 7, 11, 13} // len=6, cap=6
s = s[:0] // len=0, cap=6
s = s[:4] // len=4, cap=6
Map
Go 语言 map 的简单用法:
// 使用字面量,声明并且初始化一个简单的 map,[key:string,value:int]
s := map[string]int{"a": 123, "b": 456, "c":789}
// out: map[a:123 b:456 c:789]
// 插入和更新
s["d"] = 1001 // out: map[a:123 b:456 c:789, d:1001]
//删除元素
delete(s, "d") // out: map[a:123 b:456 c:789]
// 检索元素
value = s["a"] // out: 123
// 比较常用的快捷检索
if v, ok := s["a"]; ok {
fmt.Println("the value is >", v) // out: 123
}
函数变量
在 Go 中函数可以作为变量复制,也可以作为参数被引用
// 声明函数参数为函数变量,fn 则执行该函数
func compute(fn func(float64, float64) float64) float64 {
return fn(3, 4)
}
// 声明函数变量
hypot := func(x, y float64) float64 {
return math.Sqrt(x*x + y*y)
}
// 传递函数变量
hypot(5, 12) // out: 13
compute(hypot) // out: 5
闭包
Go 的闭包是一段匿名函数,并且可以访问外部的局部变量,如下 adder 返回一个函数闭包:
func adder() func(int) int {
sum := 5
return func(x int) int {
sum += x
return sum
}
}
// 声明 pos 函数变量
pos := adder()
fmt.Println(pos(5)) // out: 10
后面还有很多内容。。。。有空再聊。。。