https://github.com/xiao-qingjiang/SE2021
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 30 |
| · Estimate | · 估计这个任务需要多少时间 | 360 | 480 |
| Development | 开发 | 70 | 70 |
| · Analysis | · 需求分析 (包括学习新技术) | 160 | 120 |
| · Design Spec | · 生成设计文档 | 60 | 80 |
| · Design Review | · 设计复审 | 30 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 30 |
| · Design | · 具体设计 | 120 | 100 |
| · Coding | · 具体编码 | 300 | 280 |
| · Code Review | · 代码复审 | 30 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 80 |
| Reporting | 报告 | 30 | 30 |
| · Test Repor | · 测试报告 | 30 | 30 |
| · Size Measurement | · 计算工作量 | 30 | 15 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 30 |
| · 合计 | 1320 | 1435 |
二、计算模块接口
计算模块接口的设计与实现过程
-
拼音、拆字和简繁体转换调用了现有的python库
-
使用了(DFAfliter) 类来实现解析传入敏感词文件路径、添加敏感词、识别文本中的敏感词等功能,其中包括了以下五个函数:
__init__(self):定义实例化该类所需的一些变量add_keyword(self, chars, level):将一个敏感词添加到敏感词库中,由于需要被后续add函数多次调用,因此单独封装方便使用add(self, chars, level):将敏感词的各种变形类型分析讨论,并分别调用上述add_keyword函数将各种敏感词变体(变体方式会在下文分享)存入敏感词库filter(self, message):对传入的文本内容进行检测,过滤出敏感词,并转化为所要求的输出格式,然后把转化结果添加到列表中parse(self, path):解析文件路径,读入敏感词文件,并调用add函数将敏感词添加到敏感词库
-
类外函数:
chai_zi(keywords, dfa_instance):将所有敏感词传入,并将每个敏感词进行拆字,再添加到敏感词库中read_file(file_path):读入测试文本文件,并将文本中每一行分别存入同一个列表output(filename):将filter函数中形成的结果列表输出到指定输出文件type_nums(depth, queue, lens):使用DFS算法将每一个敏感词可能的组合变形方式枚举
-
算法流程:

-
独到之处:
算法的难点主要还是敏感词库的建立,如何把敏感词库建得全面、并且在全面的同时尽量避免冗余,这是一项挑战,我使用了DFS算法进行枚举,并使用Tire树构建敏感词库。以下为主要难点及解决方案
-
排列组合形成变体:假设“浑轮“是一个敏感词(因为这两个字都有繁体字,方便举例说明)”暂用“浑轮”一词来进行描述。其中”浑轮“这两个字每个字都有拼音、拆字、繁体、简体、首字母替代五种表示形式,则”浑轮“一词就有5*5种表示形式(此处说明省略在中间插入特殊字符的情况,因为这种情况可统一避免),上述”浑轮“是两个字,组合形式有(5^2)种,如果敏感词是n个字,就是(5^n)种,因此我使用了DFS来进行搜索,以”浑轮“为例,假设我分别用0,1,2,3,4表示拼音、拆字、繁体、简体、首字母替代五种表示形式,则[0, 1]表示”浑“字用拼音表示,”轮“字用拆字表示,以此类推,可将所有组合方式枚举出并存到敏感词库中
-
Tire树构建敏感词库
-
拼音化与首字母替代:使用python库pypinyin实现
-
拆字:使用python库pychai实现
-
繁体-简体转化:使用python库zhconv实现
-
计算模块接口部分的性能改进
性能分析图:

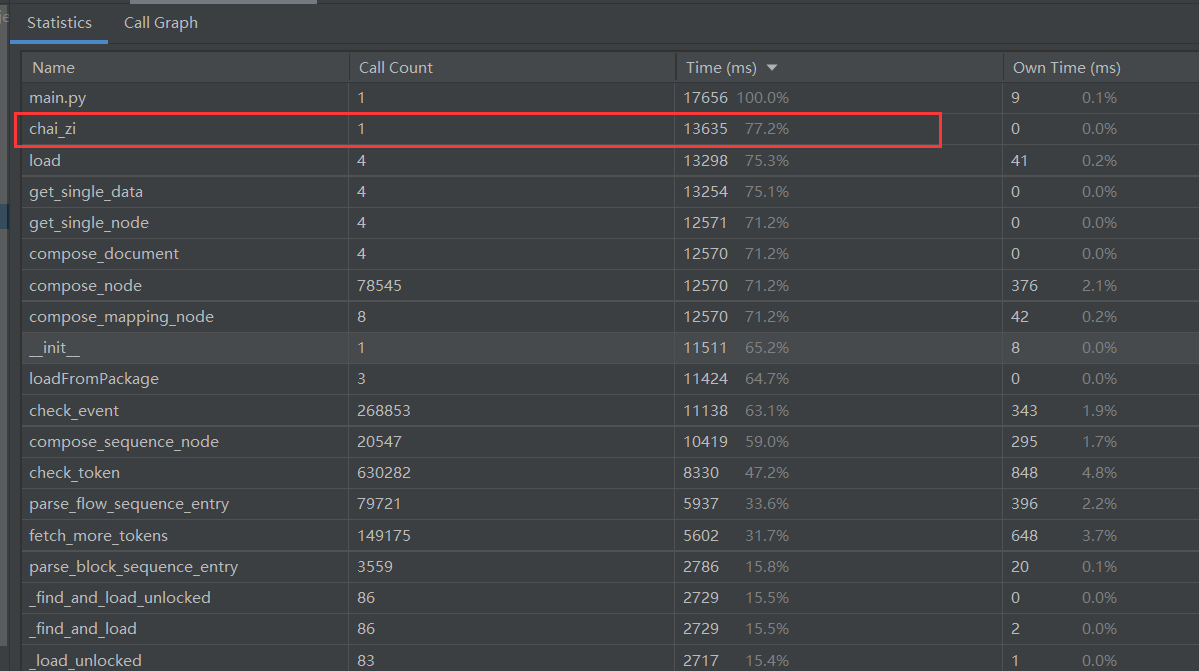
- 从上图可以看出,函数执行的大部分时间,都是由拆字操作带来的,其中经过测试,我发现是初始化调用用于拆字的pychai库时占用了绝大部分时间,因此,我选择了尽可能减少调用次数,到最后全程只调用了一次这个函数,大大减少了时间消耗。
- 在写代码过程中,其实在存储敏感词库时不同的方法也是具有着很大的性能差异,我通过结合DFS算法来调整DFA算法,避免了相同形式的敏感词重复存入的情况,减小了冗余,提高了性能。
计算模块部分单元测试展示
部分单元测试:
- 测试拆字功能
import unittest
import main
class Test(unittest.TestCase):
"""用于测试say_hello_function.py"""
def test_chai_zi(self):
"""测试能否正确拆字"""
dfa = main.DFAFilter()
res = main.chai_zi("好", dfa)
self.assertEqual(res, "女子")
if __name__ == '__main__':
unittest.main()
- 测试读入文件功能
import unittest
import main
class Test(unittest.TestCase):
"""用于测试say_hello_function.py"""
def test_read_file(self):
"""测试能否正确拆字"""
res = main.read_file(r"org.txt")
self.assertEqual(res[0], "你好,好久不见")
if __name__ == '__main__':
unittest.main()
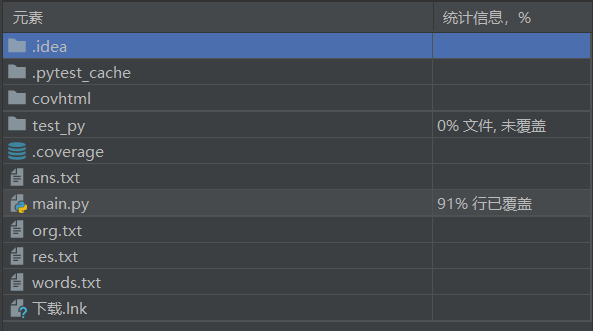
- 覆盖率截图
计算模块部分异常处理说明。
- 命令行输入异常
- 如果输入四个文件,则按顺序传入
- 如果只输入可执行python文件,使用默认路径执行
- 其他情况,输出提示并正常退出
if len(sys.argv) == 4:
words_txt = sys.argv[1]
org_txt = sys.argv[2]
ans_txt = sys.argv[3]
elif len(sys.argv) == 1:
words_txt = "words.txt"
org_txt = "org.txt"
ans_txt = "ans.txt"
else:
print("请正确输入:python main.py 文件路径 文件路径 文件路径")
exit(0)
- 当少输入了一个参数
python main.py words.txt org.txt
则输出文字提示并正常退出
请按正确格式输入:python main.py 文件名 文件名 文件名
三、心得
- 真正尝试了比较接近工程的作业,这个作业也很具备实际意义,做起来动力十足(虽然做得不怎么样), 完成这次作业是一个不断学习的过程,但好在能够明确需要学什么,感觉这次作业对能力的提升是很有帮助的
- 不要重复造轮子,第一次体会到了这句话(虽然我也不会造哈哈,目前只会用)。这次作业可以说是面向github编程,比如在解决拼音、简繁体转化、拆字时,都在网上找到了python的包,对完成作业起了很大的作用。
- 但有点可惜的是这次由于时间规划不合理,后期优化约等于0,在首字母替代的处理上也有点bug,目前已经发现了bug,但现在改显然已经来不及了,以后可能要更好地提前做好规划
- 自从数据结构与算法课结束后,就很久没有打代码了,这次写代码很生疏,希望这个能在之后的练习中得到改善
- 果然实践是最好的老师,这次算是第一次真正的用python写代码,以前有大概了解过python的基本语法,但完全没有写过,要不是这次C++没有合适的包把我给劝退了,还真不敢用python上,但没办法呀,不用python的话,C++又不会拆字,也不会简繁体转化,作业都做不了,只能硬着头皮上,不过还好,边写边查,最后也算是写出来了