Selenium 作业 1
- 请到如下网址下载最新Chrome浏览器 的 web driver 驱动
https://chromedriver.storage.googleapis.com/index.html
- pip 安装Selenium Web driver Python 客户端库
练习1
1 访问如下网站,
http://121866.com
先注册一个账号, 记住用户名和密码。
2 然后开发一个自动化程序, 使用 用户名密码 自动化登录该网站,
并通过检查登录后右上角显示的用户名判断,是否登录成功。
练习2
1. 访问天气查询网站(网址如下),查询江苏省天气
http://www.weather.com.cn/html/province/jiangsu.shtml
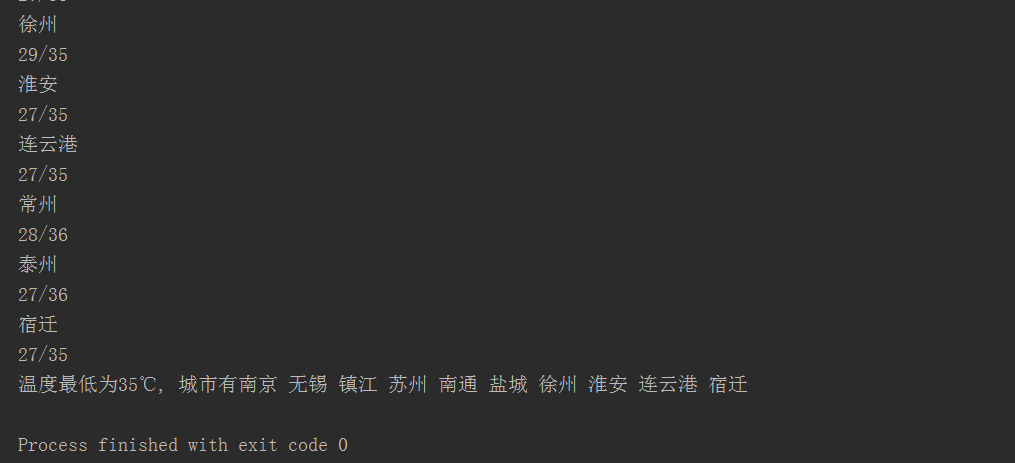
2. 获取江苏所有城市的天气,并找出其中每天最低气温最低的城市,显示出来,比如
温度最低为12℃, 城市有连云港 盐城
练习1
from selenium import webdriver
import time
driver = webdriver.Chrome(r"d: oolswebdriverschromedriver.exe")
# ------------------------
driver.get('http://121866.com/cust/sign.html')
driver.find_element_by_id("username").send_keys('xxxx')
driver.find_element_by_id("password").send_keys('xxxx')
driver.find_element_by_id("btn_sign").click()
time.sleep(2)
expectStr = driver.find_element_by_id("username").text
if 'xxxx' == expectStr:
print('测试通过')
else:
print('测试不通过')
# ------------------------
input()
driver.quit()
练习2
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("http://www.weather.com.cn/html/province/jiangsu.shtml")
cityWeather = driver.find_element_by_id("forecastID").text.split("℃ ")
print(cityWeather)
lowestweather = 100
lowestcity = []
for one in cityWeather:
one = one.replace(u'℃','')
print(one)
curweather = int(one.split(' ')[-1].split('/')[-1])
if curweather < lowestweather:
lowestweather = curweather
lowestcity.append(one.split(' ')[-2])
elif curweather == lowestweather:
lowestcity.append(one.split(' ')[-2])
print('温度最低为%s℃, 城市有%s' % (lowestweather, ' '.join(lowestcity)))
driver.quit()
方法2:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("http://www.weather.com.cn/html/province/jiangsu.shtml")
cityWeather = driver.find_element_by_id("forecastID").text.split("℃
")
print(cityWeather)
lowestweather = 100
lowestcity = []
for one in cityWeather:
one = one.replace(u'℃','')
print(one)
curweather = int(one.split('
')[-1].split('/')[-1])
if curweather < lowestweather:
lowestweather = curweather
lowestcity.append(one.split('
')[-2])
elif curweather == lowestweather:
lowestcity.append(one.split('
')[-2])
print('温度最低为%s℃, 城市有%s' % (lowestweather, ' '.join(lowestcity)))
driver.quit()
Selenium 作业 2
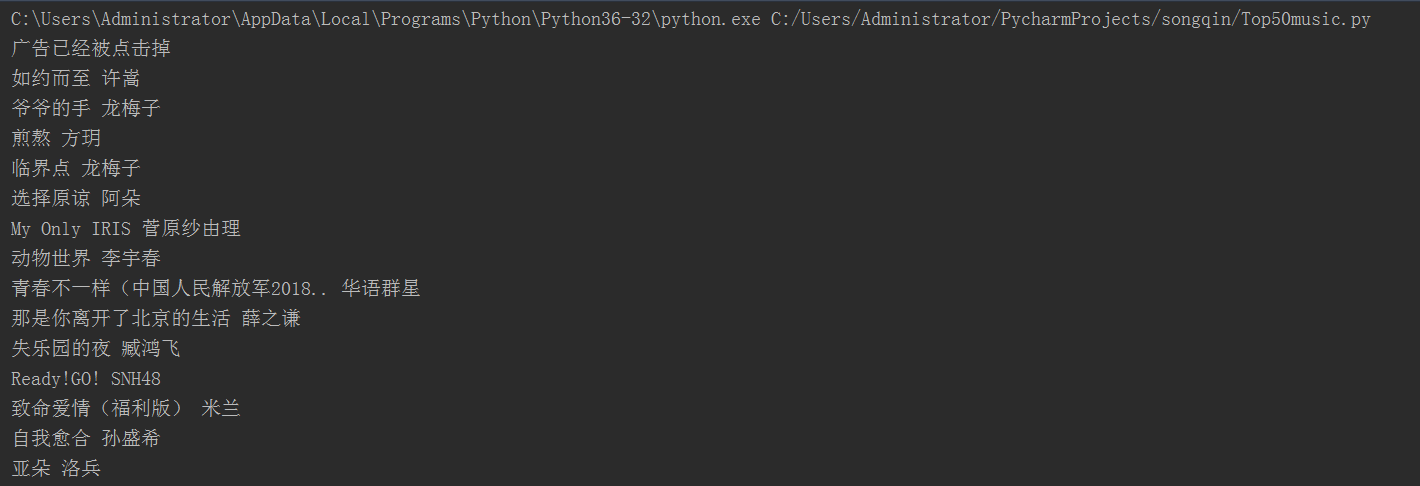
打开百度新歌榜, http://music.baidu.com/top/new
在排名前50的歌曲中,找出其中排名上升的歌曲和演唱者
注意: 有的歌曲名里面有 "影视原声" 这样的标签, 要去掉
最终结果显示的结果如下:
我不能忘记你 : 林忆莲
等 : 严艺丹
飞天 : 云朵
粉墨 : 霍尊
春风十里不如你 : 李健
方法1
# coding:utf8
from selenium import webdriver
driver = webdriver.Chrome(r"d: oolswebdriverschromedriver.exe")
# driver.implicitly_wait(1)
# 抓取排行榜信息
driver.get('http://music.baidu.com/top/new')
# 层层往下查找
div = driver.find_element_by_id("songListWrapper")
ul = div.find_element_by_tag_name("ul")
liList = ul.find_elements_by_tag_name('li')
for li in liList:
# 哪些 是有 有up 标签的 歌曲, F12 查看特性
upTags = li.find_elements_by_class_name("up")
if upTags:
# 由于只要 歌曲名和 演唱者名
title = li.find_element_by_class_name("song-title")
titleStr = title.find_element_by_tag_name("a").text
authorsStr = li.find_element_by_class_name("author_list").text
print('{:10s}:{}'.format(titleStr, authorsStr))
driver.quit()
方法2:
# encoding:utf-8
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get("http://music.taihe.com/top/new")
sleep(5)
try:
driver.find_element_by_xpath('//*[@id="subPage"]/div[8]/div[2]/span').click()
print("广告已经被点击掉")
except Exception as e:
print("searchKey: there is no suspond Page1. e = {e}")
sleep(2)
div = driver.find_element_by_id("songListWrapper")
ul = div.find_element_by_tag_name("ul")
liList = ul.find_elements_by_tag_name("li")
for li in liList:
cla = li.find_elements_by_class_name("down")
spa = li.find_elements_by_class_name("appendix")
if len(cla) > 0:
title = li.find_element_by_class_name("song-title ")
yuanMa = title.text
# print(yuanMa)
if "影视原声" not in yuanMa:
titleStr = title.find_element_by_tag_name("a").text
authorList = li.find_element_by_class_name("author_list").text
print(titleStr, authorList)
driver.quit()
Selenium 作业 3
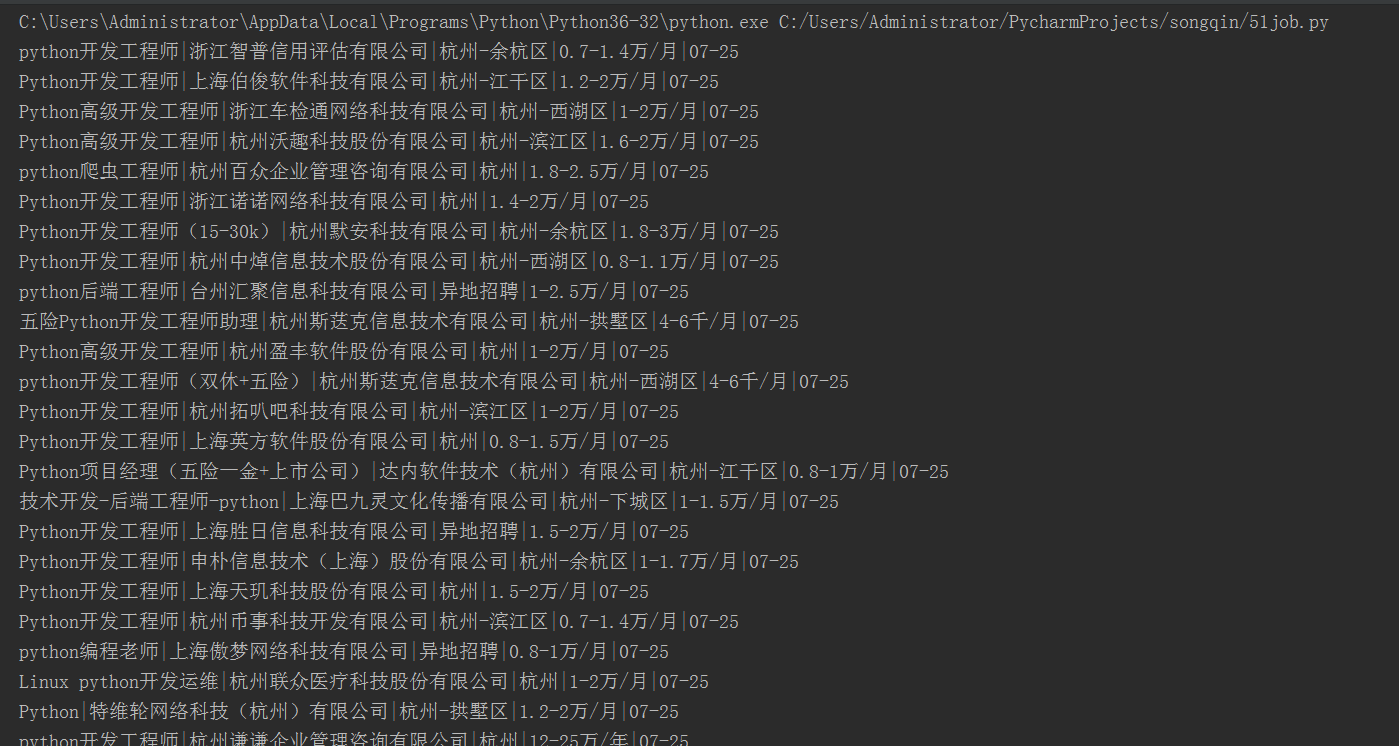
登录 51job ,
http://www.51job.com
输入搜索关键词 "python", 地区选择 "杭州"(注意,如果所在地已经选中其他地区,要去掉),
搜索最新发布的职位, 抓取页面信息。 得到如下的格式化信息
Python开发工程师 | 杭州纳帕科技有限公司 | 杭州 | 0.8-1.6万/月 | 04-27
Python高级开发工程师 | 中浙信科技咨询有限公司 | 杭州 | 1-1.5万/月 | 04-27
高级Python开发工程师 | 杭州新思维计算机有限公司 | 杭州-西湖区 | 1-1.5万/月 | 04-27
方法一
# coding:utf8
from selenium import webdriver
driver = webdriver.Chrome(r"d: oolswebdriverschromedriver.exe")
# 别忘了设置
driver.implicitly_wait(10)
# 抓取信息
driver.get('http://www.51job.com')
driver.find_element_by_id('kwdselectid').send_keys('python')
# 点击工作地点
driver.find_element_by_id('work_position_input').click()
# 选择所有城市,去掉非杭州的且选择杭州,
# 如果是杭州但是没有选,选上这些城市
cityEles = driver.find_elements_by_css_selector('#work_position_click_center_right em')
for one in cityEles:
cityName = one.text
selected = one.get_attribute('class')
# print cityName,seleted
if cityName == u'杭州':
if selected != 'on':
one.click()
else:
if selected == 'on':
one.click()
# 保存城市选择
driver.find_element_by_id('work_position_click_bottom_save').click()
# 点击搜索
driver.find_element_by_css_selector('.ush button').click()
# 搜索结果分析
jobs = driver.find_elements_by_css_selector('#resultList div.el')
for job in jobs:
# 去掉第一行:标题行
if 'title' in job.get_attribute('class'):
continue
filelds = job.find_elements_by_tag_name('span')
strField = [fileld.text for fileld in filelds]
print (' | '.join(strField))
driver.quit()
方法二
# coding:utf8
from selenium import webdriver
driver = webdriver.Chrome(r"d: oolswebdriverschromedriver.exe")
driver.implicitly_wait(10)
driver.get('http://www.51job.com')
driver.find_element_by_id('kwdselectid').send_keys('python')
driver.find_element_by_id('work_position_input').click()
# 选择城市,去掉非杭州的,选择杭州
selectedCityEles = driver.find_elements_by_css_selector(
'#work_position_click_center_right_list_000000 em[class=on]')
for one in selectedCityEles:
one.click()
driver.find_element_by_id('work_position_click_center_right_list_category_000000_080200').click()
# 保存城市选择
driver.find_element_by_id('work_position_click_bottom_save').click()
driver.find_element_by_css_selector('div.ush > button').click()
# 搜索结果分析
jobs = driver.find_elements_by_css_selector('#resultList div[class=el]')
for job in jobs:
fields = job.find_elements_by_tag_name('span')
stringFilelds = [field.text for field in fields]
print (' | '.join(stringFilelds))
driver.quit()
方法2:
from selenium import webdriver
import time
# 使用火狐浏览器,打开51job的链接
driver = webdriver.Chrome()
driver.implicitly_wait(10)
driver.get("https://www.51job.com/")
# 定位到输入框,并输入python
driver.find_element_by_id("kwdselectid").send_keys('python')
# 点击城市
pot = driver.find_element_by_xpath('//*[@id="work_position_click"]')
pot.click()
# 定位到城市的上层
cityEles = driver.find_elements_by_css_selector('#work_position_click_center_right em')
# 获取城市名称、以及是否选中
for one in cityEles:
cityName = one.text
selected = one.get_attribute('class')
# 如果城市名称叫杭州 并且未被选中就点击一下选中
if cityName == u'杭州':
if selected != 'on':
one.click()
# 如果城市名称不叫杭州 但是被选中了就点击一下取消选择
else:
if selected == 'on':
one.click()
# 点击确定按钮,关闭城市窗口
driver.find_element_by_id("work_position_click_bottom_save").click()
time.sleep(2)
# 在主页面点击搜索按钮,等待两秒之后,再结果页面打印所有表格中内容
driver.find_element_by_xpath('/html/body/div[3]/div/div[1]/div/button').click()
time.sleep(2)
# 定位到表格的行所在的位置
resultList = driver.find_elements_by_css_selector('#resultList div.el')
for re in resultList:
# 表格的第一行不要
if 'title' in re.get_attribute('class'):
continue
# 通过循环获取每一行的内容,把换行用|代替
t1 = re.text.replace("
", "|")
# 打印出所有内容
print(t1)
driver.quit()
Selenium 作业 4
登录 http://www.51job.com
点击高级搜索
输入搜索关键词 python
地区选择 杭州
职能类别 选 计算机软件 -> 高级软件工程师
公司性质选 外资 欧美
工作年限选 1-3 年
搜索最新发布的职位, 抓取页面信息。 得到如下的格式化信息
Python开发工程师 | 杭州纳帕科技有限公司 | 杭州 | 0.8-1.6万/月 | 04-27
Python高级开发工程师 | 中浙信科技咨询有限公司 | 杭州 | 1-1.5万/月 | 04-27
# coding:utf8
from selenium import webdriver
executable_path = r"d: oolswebdriverschromedriver.exe"
driver = webdriver.Chrome(executable_path)
driver.implicitly_wait(10)
# 打开网址
driver.get('http://www.51job.com')
# 选择高级搜索
driver.find_element_by_css_selector('div.ush > a').click()
# 输入选择关键词
driver.find_element_by_id('kwdselectid').send_keys('python')
# 工作地点选择
driver.find_element_by_id('work_position_input').click()
# 取消 已经选择的
selectedCityEles = driver.find_elements_by_css_selector('#work_position_click_center em[class=on]')
for one in selectedCityEles:
one.click()
# 选杭州
driver.find_element_by_id('work_position_click_center_right_list_category_000000_080200').click()
# 保存选择
driver.find_element_by_id('work_position_click_bottom_save').click()
# 要点一下别的地方, 否则下面的元素会被挡住
driver.find_element_by_css_selector('div.tit').click()
# 职能类别 选 计算机软件 -> 高级软件工程师
driver.find_element_by_id('funtype_click').click()
driver.find_element_by_id('funtype_click_center_right_list_category_0100_0100').click()
driver.find_element_by_id('funtype_click_center_right_list_sub_category_each_0100_0106').click()
driver.find_element_by_id('funtype_click_bottom_save').click()
# 公司性质选 外资 欧美
driver.find_element_by_id('cottype_list').click()
driver.find_element_by_css_selector('#cottype_list span.li[data-value="01"]').click()
# 工作年限选
driver.find_element_by_id('workyear_list').click()
driver.find_element_by_css_selector('#workyear_list span.li[data-value="02"]').click()
# 点击搜索
driver.find_element_by_css_selector('div.p_sou > span.p_but').click()
# 结果列表获取内容
jobs = driver.find_elements_by_css_selector('#resultList div[class=el]')
for job in jobs:
fields = job.find_elements_by_tag_name('span')
stringFilelds = [field.text for field in fields]
print (' | '.join(stringFilelds))
driver.quit()
方法2:
# encoding utf-8
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get("https://www.51job.com/")
driver.implicitly_wait(3)
# 点击高级搜索
driver.find_element_by_css_selector('div.ush.top_wrap a.more').click()
# 输入python
driver.find_element_by_id('kwdselectid').send_keys('python')
# 点击城市
driver.find_element_by_id('work_position_input').click()
# 将杭州以外的城市取消选择
emList = driver.find_elements_by_css_selector('#work_position_click_center_right em')
for em in emList:
cityName = em.text
check = em.get_attribute('class')
if cityName != '杭州':
if check == 'on':
em.click()
else:
if check != 'on':
em.click()
# 点击确定按钮
sleep(2)
driver.find_element_by_id('work_position_click_bottom_save').click()
driver.find_element_by_css_selector('div.tit').click()
# 在高级搜索页面点击职能类别
driver.find_element_by_id('funtype_click').click()
# 在职能页面选择高级开发工程师
driver.find_element_by_id('funtype_click_center_right_list_category_0100_0100').click()
driver.find_element_by_id('funtype_click_center_right_list_sub_category_each_0100_0106').click()
driver.find_element_by_id('funtype_click_bottom_save').click()
# 选择外派欧美
driver.find_element_by_css_selector('#cottype_list span').click()
driver.find_element_by_css_selector('#cottype_list span.li[data-value="01"]').click()
# 选择工作年限选 1-3 年,点击搜索
driver.find_element_by_id('workyear_list').click()
driver.find_element_by_css_selector('#workyear_list span.li[data-value="02"]').click()
driver.find_element_by_css_selector('div.p_sou > span.p_but').click()
sleep(2)
# 打印出搜索出的信息
elList = driver.find_elements_by_css_selector('.dw_table .el')
for el in elList:
if 'title' in el.get_attribute('class'):
continue
print(el.text.replace("
","|"))
driver.quit()

Selenium 作业 5
打开 12306 网站 https://kyfw.12306.cn/otn/leftTicket/init
出发城市 填写 ‘南京南’, 到达城市 填写 ‘杭州东’
注意输入城市名前,一定要先点击一下输入框,否则查不到。
而且输入城市名最后要包含一个回车符,否则输入框里面会自动清除
发车时间 选 06:00--12:00
发车日期选当前时间的下一天,也就是日期标签栏的,第二个标签
我们要查找的是所有 二等座还有票的车次,打印出这些有票的车次的信息(这里可以用xpath),结果如下:
G7641
G1505
G7393
G7689
from selenium import webdriver
from selenium.webdriver.support.ui import Select
driver = webdriver.Chrome(r"d: oolswebdriverschromedriver.exe")
driver.implicitly_wait(10)
driver.get('https://kyfw.12306.cn/otn/leftTicket/init')
fromEle = driver.find_element_by_id('fromStationText')
# 为什么这里要点击一下
fromEle.click()
fromEle.clear()
fromEle.send_keys(u'南京南
')
toEle = driver.find_element_by_id('toStationText')
toEle.click()
toEle.clear()
toEle.send_keys(u'杭州东
')
# 输入开始时间,
timeSelect = Select(driver.find_element_by_id('cc_start_time'))
timeSelect.select_by_visible_text('06:00--12:00')
tomorrow = driver.find_element_by_css_selector('#date_range li:nth-child(2)')
# 点击这个,就会搜索车次了
tomorrow.click()
# 方法一:用xpath实现获取二等座有票的车次信息
print('
===============================
')
xpath ='//*[@id="queryLeftTable"]//td[4][@class]/../td[1]//a'
theTrains = driver.find_elements_by_xpath(xpath)
for one in theTrains:
print (one.text)
# 方法二:用css实现获取二等座有票的车次信息
print('
===============================
')
theTrainLines = driver.find_elements_by_css_selector('#queryLeftTable > tr')
# 先不加这个,发现特别慢
driver.implicitly_wait(0)
for one in theTrainLines:
secondlevelseat = one.find_elements_by_css_selector('td:nth-of-type(4)[class]')
if secondlevelseat:
print (one.find_element_by_css_selector('td:nth-of-type(1) a').text)
driver.implicitly_wait(10)
driver.quit()
Selenium 作业 6
-- 作业1
登录华为官网 https://www.vmall.com/,
点击 "华为官网" 和 "更多精彩->应用市场" 两个链接
检查 "华为官网" 页面上是否 有如下主菜单
智能手机
笔记本&平板
穿戴设备
智能家居
更多产品
软件应用
服务与支持
华为商城
检查 "应用市场" 页面上是否 有如下主菜单
首页
游戏
软件
专题
品牌专区
华为软件专区
最后再回到主窗口, 检查鼠标停留在 "笔记本&平板" 处的时候, 是否显示的菜单有
"平板电脑 笔记本电脑 笔记本配件"
怎么模拟鼠标停留事件,请大家自行网上搜索,看看能不能自己解决问题。
-- 作业2
写一个程序实现如下的自动化过程
- 登录 121866.com
- 选择 发广告,
- 输入标题和 一些文本内容
- 选择 插图,在本地目录中选择一张准备好的图片 , 查看是否能够上传图片成功
# coding=utf-8
from selenium import webdriver
driver = webdriver.Chrome(r"d: oolswebdriverschromedriver.exe")
driver.implicitly_wait(20)
driver.get('https://www.vmall.com/')
driver.find_element_by_css_selector("div.s-sub a[href*='consumer.huawei']").click()
driver.find_element_by_css_selector("div.s-sub a.icon-dropdown").click()
driver.find_element_by_css_selector("a[href*='appstore.huawei.com']").click()
def checkHuawei():
expected = '智能手机|笔记本&平板|穿戴设备|智能家居|更多产品|软件应用|服务与支持|华为商城'
eles = driver.find_elements_by_css_selector(".menu_cn>ul>li")
eleTexts = [ele.text for ele in eles]
actual = '|'.join(eleTexts)
if actual == expected:
print('huawei page pass')
else:
print('huawei page fail!!!!')
def checkAppmarket():
expected = u'''首页|游戏|软件|专题|品牌专区|华为软件专区'''
eles = driver.find_elements_by_css_selector("ul.ul-nav li")
eleTexts = [ele.text for ele in eles]
actual = '|'.join(eleTexts)
if actual == expected:
print('app page pass')
else:
print('app page fail!!!!')
def checkVmall():
expected = u'''平板电脑|笔记本电脑|笔记本配件'''
from selenium.webdriver.common.action_chains import ActionChains
ac = ActionChains(driver)
ac.move_to_element(driver.find_element_by_id('zxnav_1')).perform()
eles = driver.find_elements_by_css_selector('#zxnav_1 li.subcate-item')
eleTexts = [ele.text for ele in eles]
actual = '|'.join(eleTexts)
if actual == expected:
print('main page pass')
else:
print('main page fail!!!!')
mainWindow = driver.current_window_handle
for handle in driver.window_handles:
driver.switch_to.window(handle)
if '消费者业务官网' in driver.title:
checkHuawei()
elif '应用市场' in driver.title:
checkAppmarket()
elif '商城官网' in driver.title:
checkVmall()
driver.switch_to.window(mainWindow)
checkVmall()
input('
press to quit...')
driver.quit()