通过cookies信息爬取
分析header和cookies
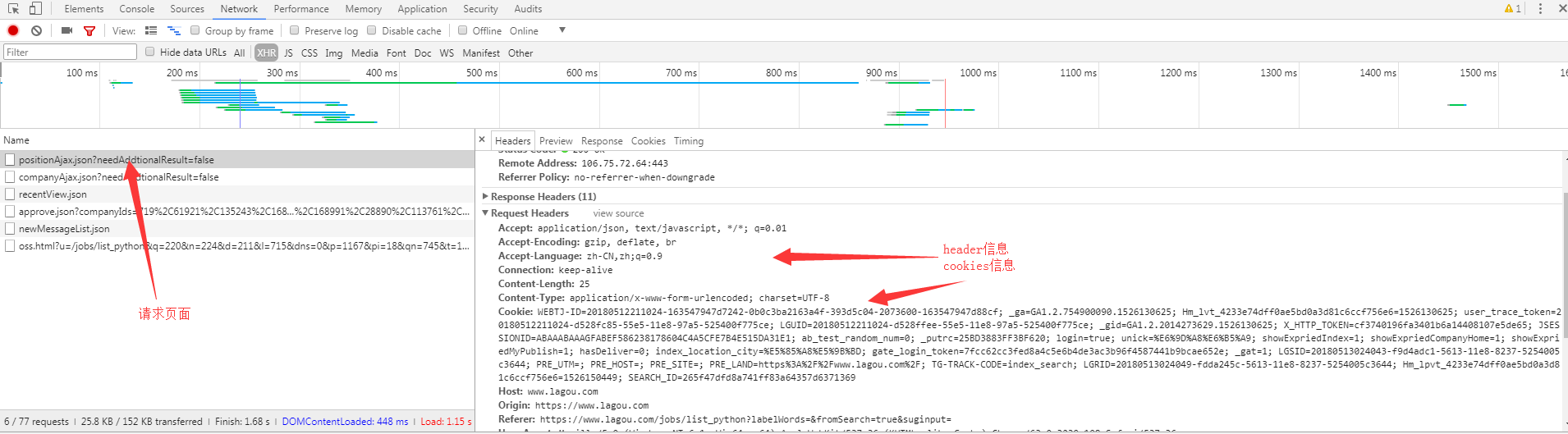
通过subtext粘贴处理header和cookies信息
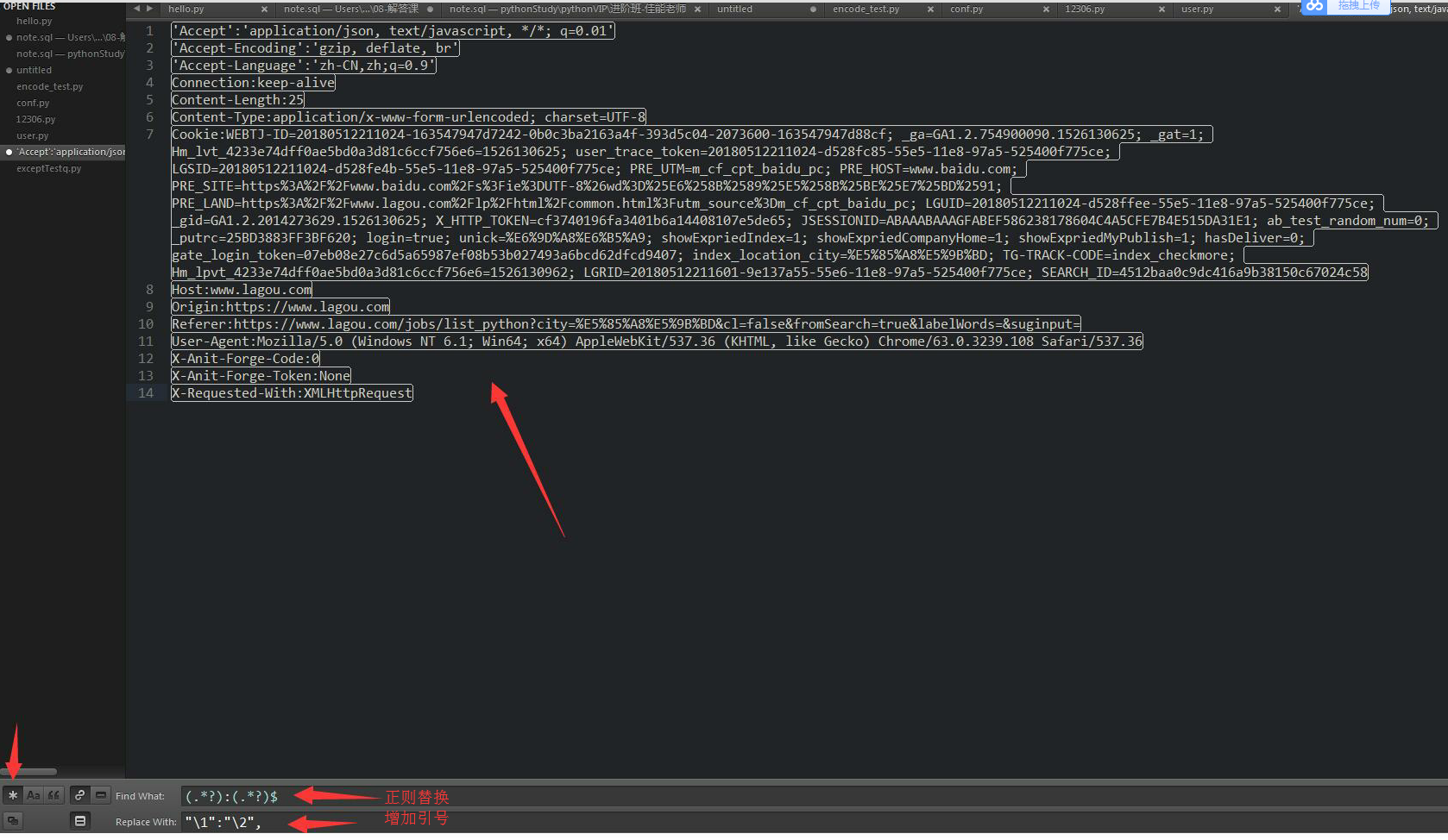
处理后,方便粘贴到代码中

爬取拉钩信息代码
import requests class LagouSpider(object): def __init__(self): self.url ='https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false' self.headers ={ "Accept":"application/json, text/javascript, */*; q=0.01", "Accept-Encoding":"gzip, deflate, br", "Accept-Language":"zh-CN,zh;q=0.9", "Connection":"keep-alive", "Content-Length":"25", "Content-Type":"application/x-www-form-urlencoded; charset=UTF-8", "Cookie":"", #根据每个人登录信息填写 "Host":"www.lagou.com", "Origin":"https://www.lagou.com", "Referer":"https://www.lagou.com/jobs/list_python?city=%E5%85%A8%E5%9B%BD&cl=false&fromSearch=true&labelWords=&suginput=", "User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36", "X-Anit-Forge-Code":"0", "X-Anit-Forge-Token":"None", "X-Requested-With":"XMLHttpRequest" } self.offset = 0 self.data = { "first":'true', "pn":0, # 页数请求 "kd":'python' # 查询关键字 } self.pos_li = [] self.total = 0 self.pageNo = 0 self.resultSize = 0 def start_request_total(self): """ 得到拉钩网页数信息 :return: """ response = requests.post(url=self.url, headers=self.headers, data=self.data) html = response.json() # 得到拉钩工作信息总数 print(html['content']['positionResult']) self.total = html['content']['positionResult']['totalCount'] # 得到拉钩工作信息每页展示数 self.resultSize = html['content']['positionResult']['resultSize'] # 从0开始 self.pageNo = int(self.total / self.resultSize) if self.total % self.resultSize > 0 else int(self.total / self.resultSize)-1 print(self.pageNo) print(len(html['content']['positionResult']['result'])) def start_request(self): """ 得到拉钩每页工作信息 :return: """ response = requests.post(url=self.url, headers=self.headers, data=self.data) html = response.json() # 得到拉钩工作信息 print(html['content']['positionResult']['result']) self.pos_li.append(html['content']['positionResult']['result']) def main(self): self.start_request_total() for i in range(self.pageNo): self.start_request() print(len(self.pos_li)) # 得到页数 if __name__ == '__main__': la = LagouSpider() la.main()
展示结果
