NB:
优点:高效(收敛速度快)、易实现;对小规模数据表现好(生成模型的原因?高偏差低方差的原因?);
缺点:性能不一定高;不能学习特征之间的相互作用
解释:NB的模型参数很容易求(有直接的公式求解),所以高效、易实现。
由于特征的条件独立假设不一定能满足所以分类性能不能保证很高。
LR:
优点:对数据的假设少,适应性强,可用于在线学习,分类时计算量小,速度快;
缺点:梯度下降可能会出现欠拟合;要求数据线性可分。
解释:LR只是假定了数据的p(y|x)服从伯努利分布(分布的参数p就是sigmoid函数),所以对数据的假设少,适应各种类型的数据。由于没有直接的解析解,求解得通过梯度下降、拟牛顿法等方法求得数值解,所以相对来说,没有NB那样高效。另外LR只适合求解线性可分的问题。
SVM:
优点:高准确率、可处理线性和非线性可分数据,计算复杂度低;解决小样本及高维模式识别中表现出许多特有的优势;对不平衡数据效果好(当然不平衡对效果还是有影响的)
缺点:调参麻烦,对参数和核的选择比较敏感。内存消耗大。难解释。多分类效果不好
解释:
1)高效:计算过程也就是SMO算法,每一个子问题都是两个变量的二次规划问题,存在解析解,所以求解很快,虽然计算子问题的次数很多,但总体还是高效的。
在对参数α产生影响的数据只有那些支持向量,所以大部分数据都不会参与计算。
2)调参麻烦:要选择适当核函数,核函数又有参数选择,多项式核的参数非常多,不同的核函数和不同参数对结果影响大
3)内存消耗大:参数α是通过SMO算法得到的,而SMO算法是迭代计算的过程,每次α的计算都是以核矩阵中的值(Kij)作为参数,
因此为了避免重复计算(Kij)就必须存储核矩阵(n2,n是样本数量),所以内存消耗大。
4) 难解释: 经过核函数映射之后的所学习的模型变成了
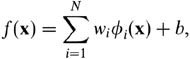
而由于映射Φ(x)是不明确的(要由核函数推出来),所以SVM的解是难解释的。
当数据样本数远远少于特征数(n<<p),高维特征空间意味着更高的数据过拟合风险。事实上,当样本数远小于特征数时,应该彻底避免使用高方差模型。
决策树:
优点:可解释,对数据线性与否无关,计算量简单,对缺失不敏感;
数据不需要过多预处理,对于决策树,数据的准备往往是简单或者是不必要的.其他的技术往往要求先把数据一般化,比如去掉多余的或者空白的属性。
能够同时处理数据型和常规型属性。其他的技术往往要求数据属性的单一。
可扩展:决策树可很好地扩展到大型数据库中,同时它的大小独立于数据库的大小。【???】
缺点:不支持在线学习,容易过拟合;对线性数据没有线性分类器的效果好
RF:
优点:快速并且可扩展,参数少,一般不会过拟合
缺点:偏向对多值属性(cart),不平衡数据效果不好(投票模型的缺点)
1.随机森林已经被证明在某些噪音较大的分类或回归问题上会过拟,2.对于有不同级别的属性的数据,级别划分较多的属性会对随机森林产生更大的影响,所以随机森林在这种数据上产出的属性权值是不可信的
adaboost:
优点:准确率高
缺点:鲁棒性差(异常值影响大,因为误分类对象会获得大的权重),可能过拟合(误分类样本会越来越得到关注)
KNN:
优点: 简单、可用于非线性分类(线性可分与否对算法没影响),训练时间复杂度为O(n),对数据没有假设,对outlier不敏感(因为是多数决定)
缺点: 计算量大(每次预测都要计算该样本与数据集其他样本的距离), 样本不平衡问题(即有些类别的样本数量很多,而其它样本的数量很少),需要大量的内存(存储所有数据);
RF VS SVM
使用随机森林无需预先对数据进行预处理,而若使用支持向量机则有必要进行数据预处理;因为:支持向量机需要计算几何间隔,所以如果数据没有预处理的话,会有影响。
在多分类问题上,随机森林的泛化能力显著优于支持向量机;因为:支持向量机多分类的机制是通过1对多或1对1这种方式实现的,效果不一定很好。
在不平衡分类问题上,随机森林显著逊色于支持向量机。因为:支持向量机只由少数支持向量决定,虽然不平衡数据可能会有影响,但影响不大;随机森林采取的多数投票的原理,所以一般会被分为大的类别
LR VS 决策树
1.逻辑回归对数据整体结构的分析优于决策树,而决策树对局部结构的分析优于逻辑回归。
2.逻辑回归擅长分析线性关系,而决策树对线性关系的把握较差。虽然对付非线性关系是决策树的强项,但是很多非线性关系完全可以用线性关系作为近似,而且效果很好。
线性关系在实践中有很多优点:简洁,易理解解,可以在一定程度上防止对数据的过度拟合。
3.逻辑回归对极值比较敏感,容易受极端值的影响,而决策树在这方面表现较好。
两者的差别主要来自算法逻辑。决策树由于采用分割的方法,所以能够深入数据细部,但同时失去了对全局的把握。一个分层一旦形成,它和别的层面或节点的关系就被切断了,以后的挖掘只能在局部中进行。同时由于切分,样本数量不断萎缩,所以无法支持多变量的同时检验。而逻辑回归,始终着眼整个数据的拟合,所以对全局把握较好。但无法兼顾局部数据,或者说缺乏探查局部结构的内在机制。
除外,逻辑回归和决策树还有一些应用上的区别。决策树的结果和逻辑回归相比略显粗糙。逻辑回归原则上可以提供数据中每个观察点的概率,而决策树只能把挖掘对象分为有限的概率组群。比如决策树确定17个节点,全部人口就只能有17个概率,在应用上受到一定限制。就操作来说,决策树比较容易上手,需要的数据预处理较少,而逻辑回归则要求一定的训练和技巧。
基于内容 VS 协同过滤
差别在于:协同过滤必须要有用户行为,基于内容的推荐可以不用考虑用户行为。
冷启动阶段只能用基于内容的推荐,因为没有用户行为数据;积累一段时间用户行为数据后就可以用协同过滤了。
基于内容的推荐的要求:item数据比较容易结构化,且结构化的数据能相对完整的描述item。否则效果不会太好;
协同过滤的要求:用户行为越丰富越好;
参考:http://www.zhihu.com/question/19971859
http://www.itongji.cn/article/121930092013.html
http://wenku.baidu.com/link?url=DV0TX-ferYRQ3g9P550eL5yTwZ4RtK9DjFnMedHkBw8W0nnBp1jwLX7piBcbxOIb_BwHbk82AKWbW9HdIHQ8vMS7iirRvqGh-5xY-yEuIDS
如果训练集很小,那么高偏差/低方差分类器(如朴素贝叶斯分类器)要优于低偏差/高方差分类器(如k近邻分类器),因为后者容易过拟合。然而,随着训练集的增大,低偏差/高方差分类器将开始胜出(它们具有较低的渐近误差),因为高偏差分类器不足以提供准确的模型
重点:
1)将线性或逻辑回归模型的系数绝对值解释为特征重要性
因为很多现有线性回归量为每个系数返回P值,对于线性模型,许多实践者认为,系数绝对值越大,其对应特征越重要。事实很少如此,因为:(a)改变变量尺度就会改变系数绝对值;(b)如果特征是线性相关的,则系数可以从一个特征转移到另一个特征。此外,数据集特征越多,特征间越可能线性相关,用系数解释特征重要性就越不可靠。
2)尚未标准化就进行L1/L2/等正则化
使用L1或L2去惩罚大系数是一种正则化线性或逻辑回归模型的常见方式。然而,很多实践者并没有意识到进行正则化之前标准化特征的重要性。
回到欺诈检测问题,设想一个具有交易金额特征的线性回归模型。不进行正则化,如果交易金额的单位为美元,拟合系数将是以美分为单位时的100倍左右。进行正则化,由于L1/L2更大程度上惩罚较大系数,如果单位为美元,那么交易金额将受到更多惩罚。因此,正则化是有偏的,并且趋向于在更小尺度上惩罚特征。为了缓解这个问题,标准化所有特征并将它们置于平等地位,作为一个预处理步骤
3)想当然地使用缺省损失函数
4)非线性情况下使用简单线性模型
5)忘记异常值
6)样本数少于特征数(n<<p)时使用高方差模型
7)不考虑线性相关直接使用线性模型