1、定义
两个对象之间的距离相异度(dissimilarity)是这两个对象差异程度的数值度量。对象越类似,他们的相异度就越低(相似度就越高)。通常用“距离(distance)”用作相似度的同义词。
变换经常和相异度一起出现,因为把相似度转换成相异度或者相反,或者将邻近度变换到一个特定区间,例如将[0,10]变换到[0,1]。通常,邻近度度量(特别是相似度)被定义为或者变换到区间[0,1]的值,这样做的动机是使用一种适当的度量,由邻近度的值表明两个对象之间的相似(相异)的程度。
2、数据对象之间的相异度
(1)欧几里得距离(Euclidean distance)
一维、二维、三维或者高维空间中的两个点x和y中间的距离通常用欧几里得距离d(x,y)表示:
![]()
(2)闵可夫斯基距离(Minkowski distance)
作为欧几里得距离的推广,或者说欧几里得距离是闵可夫斯基距离的一种特例。
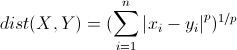
p=1,城市街区(也称曼哈顿、出租车、L1范数)距离。例如汉明距离(Hamming distance),他是两个具有二元属性的对象之间不同的二进制位数。
p=2,欧几里得距离(L2范数)
p=无穷,上确界(L无穷或者Lmax范数)距离。这是对象属性之间的最大距离。
针对数据对象之间的相异度,x和y通常都用距离矩阵(distance matrix)表示,计算欧几里得距离后得到的是欧几里得距离矩阵。
3、数据对象之间的相似度
数据对象之间的相似度一定程度上可以看做是数据对象之间的相异度的否定。
(1)简单匹配系数
Simple Matching Coefficient,SMC.
适合场景:二元属性的相似性度量。
两个仅包含二元属性的对象之间的相似性度量也称为相似系数(similarity coefficient),并且通常在0和1之间取值,0代表对象一点也不相似,1代表对象完全相同。
则: SMC=值匹配的属性个数/属性个数=(f00+f11)/(f00+f01+f10+f11)
(2)Jaccard系数
Jaccard coefficient.其实处理的是对SMC条件不适合的情况下,X和Y属性中有大量不同的,而少量相同的,及00匹配的很多,而11匹配的很少。例如对于x和y代表一个事务矩阵的两行,表示每个非对称的二元属性对应商店的一个商品,1表示购买,0表示不购买。则对于两个事务(两次购买记录),出现同样的商品的记录非常少,而都不买的商品非常多,这样就不能把00和11同等看待。这就需要Jaccard 系数。
J=匹配的个数/不涉及0-0匹配的属性个数=f11/(f01+f10+f11)
(3)余弦相似度
解决SMC、Jaccard针对二元属性的问题。实际问题中不具备二元属性的对象非常多,并且要计算其相似度。例如文档。
针对文档矩阵,向量的每个属性代表一个特定的词在文档中出现的频率(实际的问题复杂的多,因为需要忽略常用的词,并使用各种技术处理同一个词的不同形式,不同的文档长度以及不同的词频)。
尽管文档的词(向量的属性)很多,但是每个文档的向量都是稀疏的(出现很多属性为0的情况),并且属性的值为非负整数,此时SMC和Jaccard都失效。可采用余弦相似度(cosine similarity)。
cos(x,y)=x*y / (||x||*||y||)
其实就是这两个向量夹角的角度。
下面还有广义的Jaccard系数和相关性度量皮尔森相关(Person's correlation)等不再讨论。
参考文档:
[1] 数据挖掘导论(完整版) Pang-Ning Tan著,范明、范宏建等译
[2] 炼数成金数据挖掘之距离计算算法
[3] 炼数成金 常用的距离度量总结