Javascript学习笔记
DOM操作:
一.GetElementById()
ID在HTML是唯一的,getElementById()可以定位唯一的一个DOM节点
二.querySelector()
返回文档中匹配指定CSS选择器中的一个元素
例子:
Document.querySelector(“#test”); //查找ID =”test” 的节点
Document.querySelector(“p”);//获取文档中第一个p元素
Document.querySelector(“.examlp”);//获取文档中class = examlp 的第一个元素
Document.querySelector(“a[target]”);//获取文档中target属性中的第一个<a>元素
三.对于HTML的class属性发现
对于一个<div class = “intro test”></div>
在用querySelector或getElementByClassName时它的关键词可以为intro 也可以为 test
所以在搜索时如果有重复名,可以用document.querySelectorAll(".intro.test");
重点:document.querySeletorAll返回的是一个集合
我在学习过程中发现,搜了许多关于Selector的语法,却找不到类似下面这种
Class = c-green 的节点,比如我要访问它的第二个<p>,但我目前已知的方法几乎都是
访问每个节点的第一个元素,那么就我所知
对于:
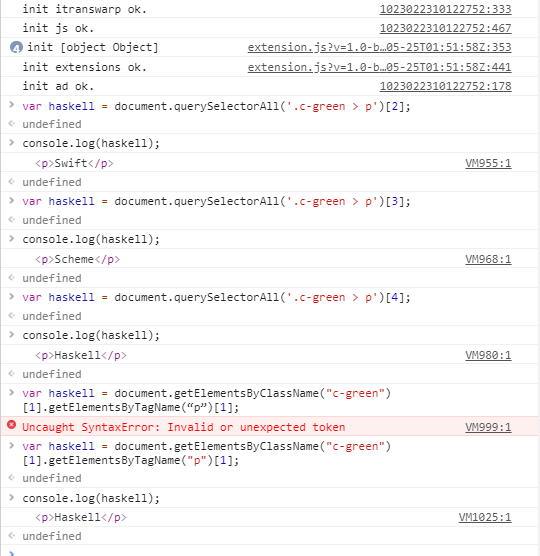
<div class="c-red c-green"> <p>Python</p> <p>Ruby</p> <p>Swift</p> </div> <div class="c-green"> <p>Scheme</p> <p>Haskell</p> </div>
假如我们要选择<p>Haskell</p>该怎么办呢?
我的想法是这样的,先通过document.getElementsByClassName("c-green")[1]访问节点<div class="c-green">,为什么后面要加个[1],后面会说,然后通过父节点,我们再访问子节点document.getElementsByClassName("c-green")[1].getElementsByTagName(“p”)[1]这样我们就能顺利访问到它的第二个<p>,也有一种方法,就是通过<divclass="c-green">直接document.querySelectorAll('.c-green > p')[4]; 来访问到它的第2个节点,一开始我很好奇,为什么括号后面是[4],它不是第二个<p>元素吗,为什么不是[1],这就跟我一开始说的情况一样了,就是intro 和 test ,之前说了,当<div class = “intro test”></div>时,它的class可以是intro,也可以是test,那么上面的标签中,是不是有两个c-green呢,两个标签中<p>元素是不是有5个呢,那第一个元素从[0]开始,<p>Haskell</p>自然就是[4]咯,刚刚不也是有个document.getElementsByClassName("c-green")[1]吗,加[1]自然是因为它是第二个class = “c-green” 的原因,如果是[0]的话,那么后面.getElementsByTagName(“p”)[1]访问的就是第一个 c-green中的第2个<p>元素<p>Ruby</p>了。
当然上述都是可以通过动手获得的概念,因为很迷惑,所以我也写了一些代码去验证:
<html> <head> <style type="text/css"> h1.test{color:blue;} </style> </head> <script> function click_first() { document.querySelector(".intro").style.backgroundColor = "red"; } function click_second() { document.querySelectorAll(".intro")[1].style.backgroundColor = "red"; } </script> <body> <h1 class="intro test">Header 1</h1> <h1 class="intro">Header 2</h1> <p>----------------------------</p> <p>点击下面按钮搜寻intro第一个节点</p> <button onclick="click_first()">搜寻</button> <p>点击下面按钮搜寻第二个intro第一个节点</p> <button onclick="click_second()">搜寻</button> </body> </html>
改变节点前:

改变节点后:

我写了上面的代码去验证后,同时也明白了
querySelectorAll()返回的是集合。
当然我也有到控制台去尝试过,不然没有实例是无法得知的。
熟悉如何寻找到节点后,就方便我们去更新DOM和删除DOM了,这样也可以去动态改变我们的HTML的内容。
目前重点还是比较关注一个网页数据交互的过程,因为之前尝试过去通过写的js脚本去获得别人的cookie,自己的cookie内容也观察过,在想如果一个网页在数据交互的时候是否能够通过一些漏洞来获得别人的cookie。
到时候会发表一些学习经验及看法。
下面是从网上找的比较详细的querySelector()的语法:
| 选择器 | 示例 | 示例说明 | CSS |
|---|---|---|---|
| .class | .intro | 选择所有class="intro"的元素 | 1 |
| #id | #firstname | 选择所有id="firstname"的元素 | 1 |
| * | * | 选择所有元素 | 2 |
| element | p | 选择所有<p>元素 | 1 |
| element,element | div,p | 选择所有<div>元素和<p>元素 | 1 |
| element element | div p | 选择<div>元素内的所有<p>元素 | 1 |
| element>element | div>p | 选择所有父级是 <div> 元素的 <p> 元素 | 2 |
| element+element | div+p | 选择所有紧接着<div>元素之后的<p>元素 | 2 |
| [attribute] | [target] | 选择所有带有target属性元素 | 2 |
| [attribute=value] | [target=-blank] | 选择所有使用target="-blank"的元素 | 2 |
| [attribute~=value] | [title~=flower] | 选择标题属性包含单词"flower"的所有元素 | 2 |
| [attribute|=language] | [lang|=en] | 选择 lang 属性以 en 为开头的所有元素 | 2 |
| :link | a:link | 选择所有未访问链接 | 1 |
| :visited | a:visited | 选择所有访问过的链接 | 1 |
| :active | a:active | 选择活动链接 | 1 |
| :hover | a:hover | 选择鼠标在链接上面时 | 1 |
| :focus | input:focus | 选择具有焦点的输入元素 | 2 |
| :first-letter | p:first-letter | 选择每一个<P>元素的第一个字母 | 1 |
| :first-line | p:first-line | 选择每一个<P>元素的第一行 | 1 |
| :first-child | p:first-child | 指定只有当<p>元素是其父级的第一个子级的样式。 | 2 |
| :before | p:before | 在每个<p>元素之前插入内容 | 2 |
| :after | p:after | 在每个<p>元素之后插入内容 | 2 |
| :lang(language) | p:lang(it) | 选择一个lang属性的起始值="it"的所有<p>元素 | 2 |
| element1~element2 | p~ul | 选择p元素之后的每一个ul元素 | 3 |
| [attribute^=value] | a[src^="https"] | 选择每一个src属性的值以"https"开头的元素 | 3 |
| [attribute$=value] | a[src$=".pdf"] | 选择每一个src属性的值以".pdf"结尾的元素 | 3 |
| [attribute*=value] | a[src*="runoob"] | 选择每一个src属性的值包含子字符串"runoob"的元素 | 3 |
| :first-of-type | p:first-of-type | 选择每个p元素是其父级的第一个p元素 | 3 |
| :last-of-type | p:last-of-type | 选择每个p元素是其父级的最后一个p元素 | 3 |
| :only-of-type | p:only-of-type | 选择每个p元素是其父级的唯一p元素 | 3 |
| :only-child | p:only-child | 选择每个p元素是其父级的唯一子元素 | 3 |
| :nth-child(n) | p:nth-child(2) | 选择每个p元素是其父级的第二个子元素 | 3 |
| :nth-last-child(n) | p:nth-last-child(2) | 选择每个p元素的是其父级的第二个子元素,从最后一个子项计数 | 3 |
| :nth-of-type(n) | p:nth-of-type(2) | 选择每个p元素是其父级的第二个p元素 | 3 |
| :nth-last-of-type(n) | p:nth-last-of-type(2) | 选择每个p元素的是其父级的第二个p元素,从最后一个子项计数 | 3 |
| :last-child | p:last-child | 选择每个p元素是其父级的最后一个子级。 | 3 |
| :root | :root | 选择文档的根元素 | 3 |
| :empty | p:empty | 选择每个没有任何子级的p元素(包括文本节点) | 3 |
| :target | #news:target | 选择当前活动的#news元素(包含该锚名称的点击的URL) | 3 |
| :enabled | input:enabled | 选择每一个已启用的输入元素 | 3 |
| :disabled | input:disabled | 选择每一个禁用的输入元素 | 3 |
| :checked | input:checked | 选择每个选中的输入元素 | 3 |
| :not(selector) | :not(p) | 选择每个并非p元素的元素 | 3 |
| ::selection | ::selection | 匹配元素中被用户选中或处于高亮状态的部分 | 3 |
| :out-of-range | :out-of-range | 匹配值在指定区间之外的input元素 | 3 |
| :in-range | :in-range | 匹配值在指定区间之内的input元素 | 3 |
| :read-write | :read-write | 用于匹配可读及可写的元素 | 3 |
| :read-only | :read-only | 用于匹配设置 "readonly"(只读) 属性的元素 | 3 |
| :optional | :optional | 用于匹配可选的输入元素 | 3 |
| :required | :required | 用于匹配设置了 "required" 属性的元素 | 3 |
| :valid | :valid | 用于匹配输入值为合法的元素 | 3 |
| :invalid | :invalid | 用于匹配输入值为非法的元素 | 3 |
----------------------------------------------------------------------------------------------------
