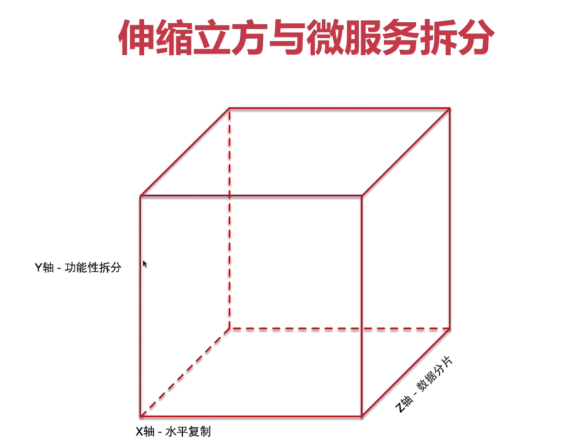
一、服务拆分的三个维度
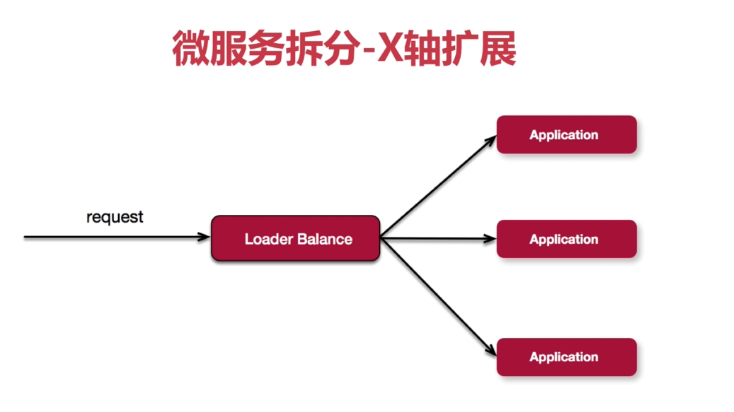
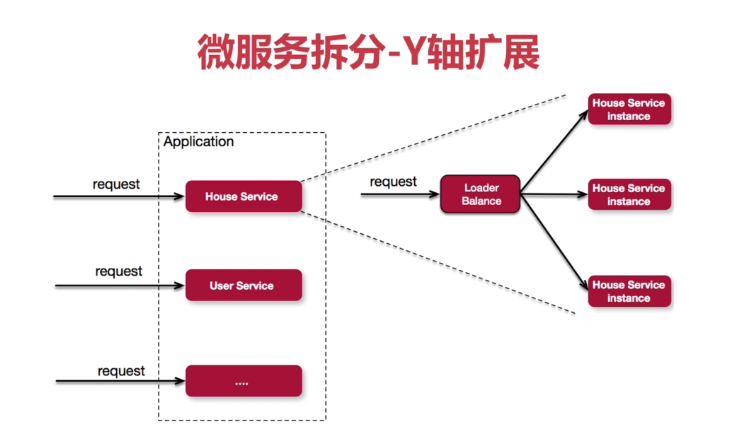

三个维度拆分后,微服务的架构图就如下图所示:
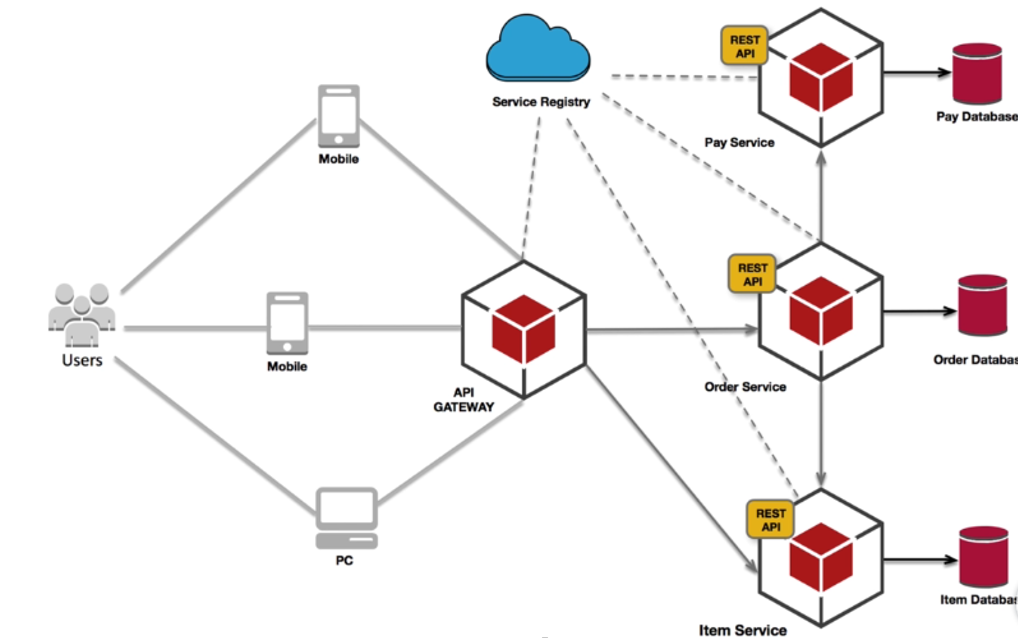
API GATEWAY服务网关:
身份认证、权限管理、服务动态路由、数据的聚合(比如房产详情页就有详情、评论、推荐,这些都属于不同的服务,这些我们就需要在服务网关中去做)
Service Register:注册中心 服务的注册与发现
注册与发现:如果是在单体架构中,添加一个实例,一般是在前端反向代理中如Nginx中添加一个实例服务器ip端口。
而在微服务中这种方式就很难满足多服务的架构,一方面频繁的修改Nginx配置文件极易出错,引起整个系统的故障。
另一方面,服务消费者要记录大量url和ip的配置,管理这些配置非常繁琐,很难理清他们之间的依赖关系。而且要增加软硬件的投入。
如果在客户端配置,就减少了这种投入。服务的注册与发现在客户端负载均衡提供了可能。
-
微服务的数据库可以根据每个服务的特点选择合适的数据库,比如Order数据量大,可以选择Hbase数据库。也可以根据自己擅长的技术栈来选择。
二、拆分的原则和步骤
1.拆分的原则
评价架构好坏的原则:可以用变化的成本来衡量。架构的目的就是管理复杂性、易变性和不确定性。
这样就能在系统演化进程中一部分系统的改变不会影响另一部分的系统。
- 高内聚低耦合,服务粒度适中
- 以业务模型切入
- 演进式拆分

2.拆分的步骤
- 分析业务模型——弱耦合在一起,高内聚
- 确定服务边界
1)分析业务模型
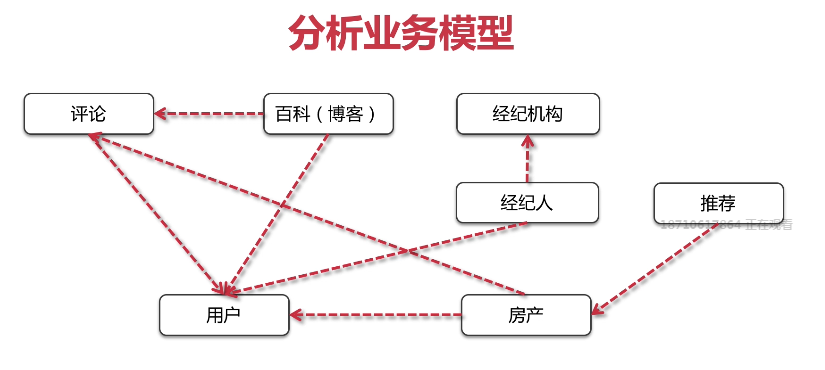
推荐是对房产进行推荐,所以推荐依赖房产;房产的产权属于某个用户,所以房产依赖用户
经济人属于某个经济机构;经济人也是一个用户
评论可以针对博客,也可以针对房产
评论和博客都依赖于用户
用户、经济人、经济机构是练习比较紧密的,所以可以放到一个服务当中,叫用户服务。
推荐目前只是针对房产进行推荐,我们可以将推荐和房产放到一起,叫房产服务。
评论和博客放到一起,我们叫评论服务。
最后产生的依赖关系就是:
评论服务依赖于用户服务
房产服务依赖于用户服务和评论服务
用户服务作为底层服务不依赖于其他服务
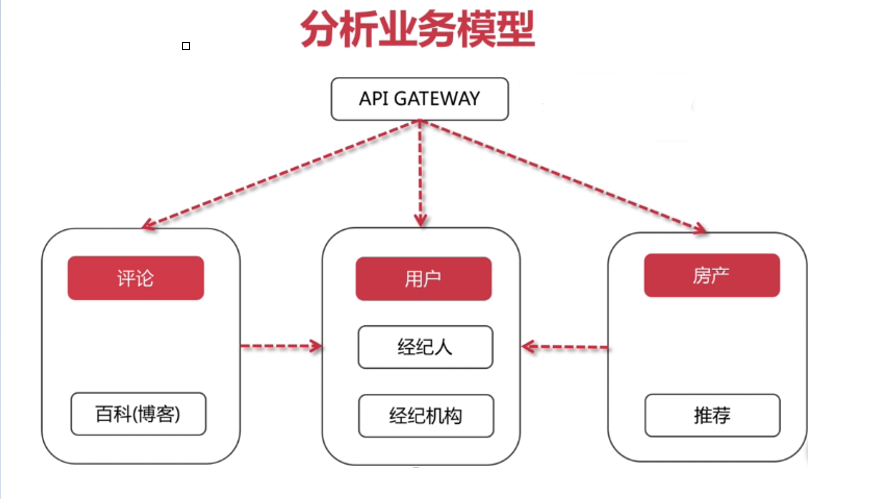
2)确定服务边界
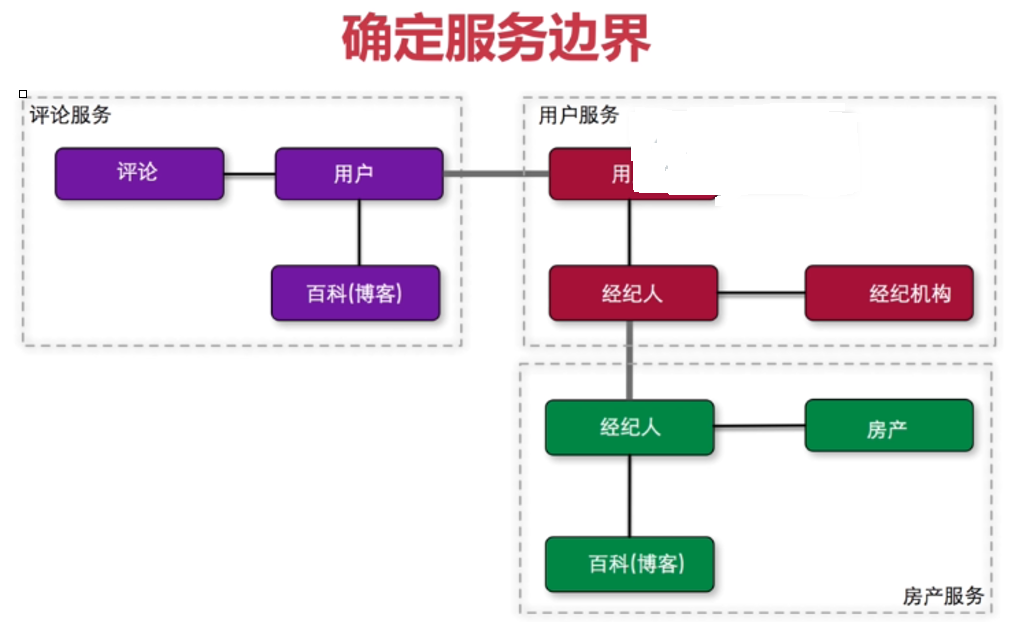
评论服务和用户服务的共享模型是用户
评论服务需要获取用户的头像、名称等信息,用户服务提供接口给评论服务访问。
用户服务和房产服务的共享模型是经济人
房产服务需要从用户服务那获取经济人的一些信息,包含头像 email 联系方式等,并不需要密码等信息,用户服务提供接口给房产服务访问。
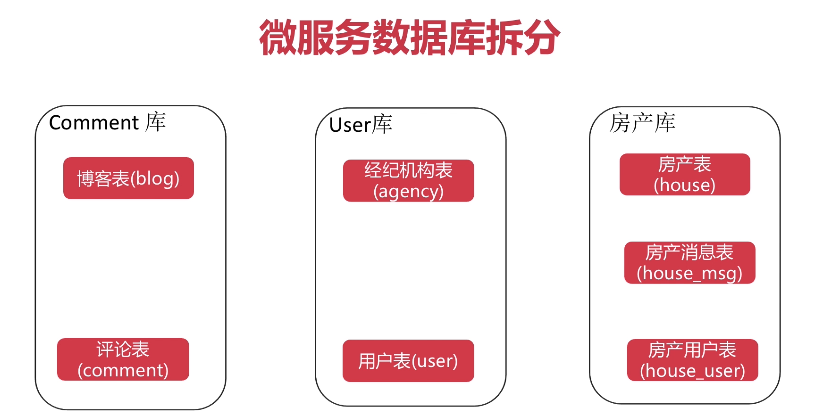
和单体相比,各个数据库的表是没有变化的,但是将数据库分成了三个