推荐系统通常可分为两部分召回与排序,粗排和精排

首先明确一点,计算广告或者推荐系统中数据特点,大多是高维离散型数据。

1 召回
召回框架如下图所示:
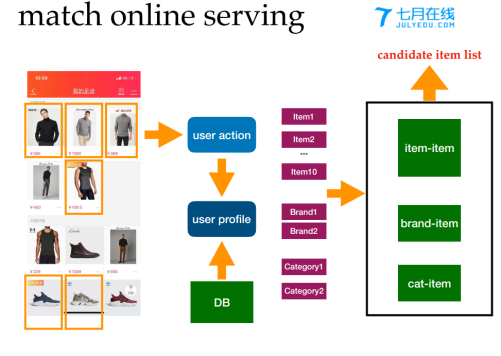
常用的召回算法:
1基于共现关系的collaborative Filtering:利用用户的行为数据建模。这里需要注意用户活跃度与物品流行度,仅仅基于用户行为数据设计的推荐算法一般称为协同过滤算法
以下展示常见的相似度计算公式:
1 用户相似度
A: 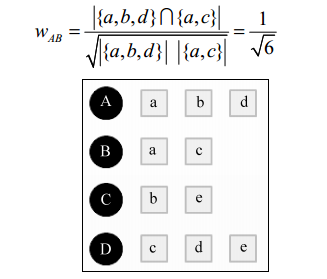
B: UserCF算法中用户u对物品i的感兴趣程度:
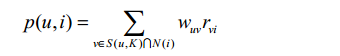
其中, S(u, K)包含和用户u兴趣最接近的K个用户, N(i)是对物品i有过行为的用户集合, wuv是用户u和用户v的兴趣相似度, rvi代表用户v对物品i的兴趣,因为使用的是单一行为的隐反馈数据,所以所有的rvi=1
C: 
可以看到,该公式惩罚了用户u和用户v共同兴趣列表中热门物品对他们相似度的影响 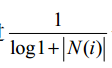
2 基于物品的协同过滤
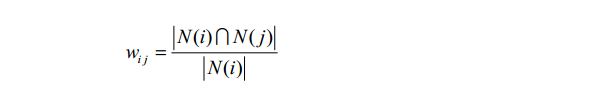
这里,分母|N(i)|是喜欢物品i的用户数,而分子 N i N j ( ) ( ) 是同时喜欢物品i和物品j的用户数。因此,上述公式可以理解为喜欢物品i的用户中有多少比例的用户也喜欢物品j
上述公式虽然看起来很有道理,但是却存在一个问题。如果物品j很热门,很多人都喜欢那么Wij就会很大,接近1。因此,该公式会造成任何物品都会和热门的物品有很大的相似度,这对于致力于挖掘长尾信息 的推荐系统来说显然不是一个好的特性。为了避免推荐出热门的物品,
可以用下面的公式: 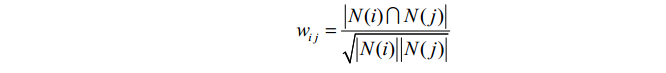
这个公式惩罚了物品j的权重,因此减轻了热门物品会和很多物品相似的可能性。
下图是一个根据上面的程序计算物品相似度的简单例子。图中最左边是输入的用户行为记录,每一行代表一个用户感兴趣的物品集合。然后,对于每个物品集合,我们将里面的物品两两加一,得到一个 矩阵。最终将这些矩阵相加得到上面的C矩阵。其中C[i][j]记录了同时喜欢物品i和物品j的用户数。最后,将C矩阵归一化可以得到物品之间的余弦相似度矩阵W。

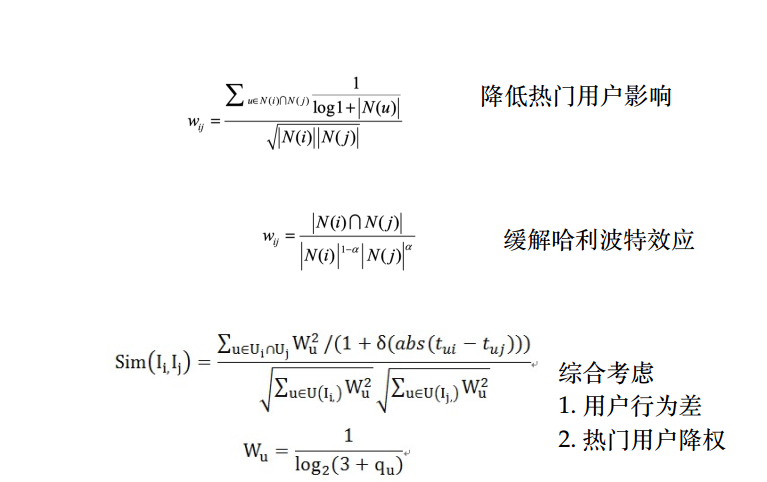
改进版ItemToItem:
2 Model based CF:
MF 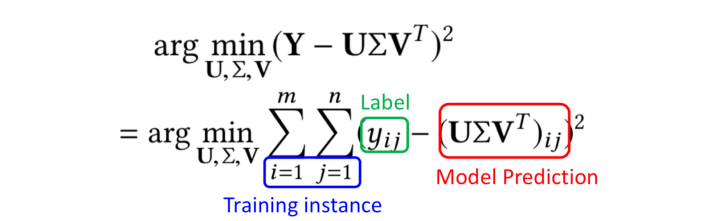
SVD 
FISM: 用评价过的Item表示用户: 
SVD++: 嵌入ID类型数据以及用户表示过的物品表示用户: 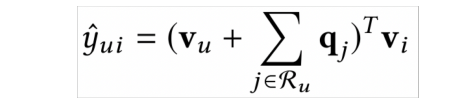
FM: 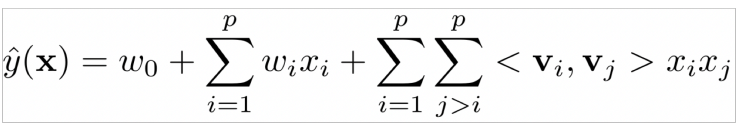
通过用户偏好建模选取key,通过k近邻搜索来查找value
查找算法: LSH KD tree ball tree
2 排序
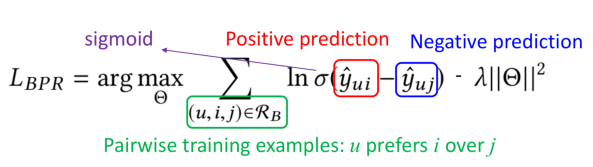
推荐系统中的排序是多目标排序, 比如CTR与CVR预估,按照优化方式的不同,也就是learn to rank的三种方式,可分为Pointwise CTR预估,Pairwise bpr Lambed MART,listWise
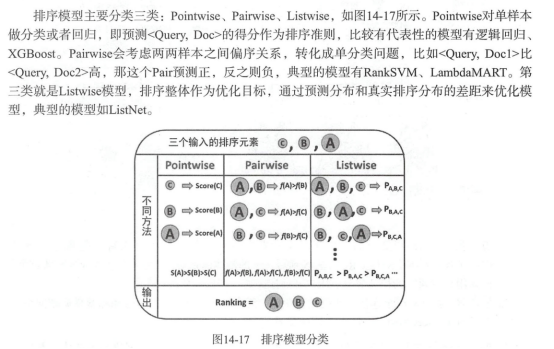
常用的pointwise方式,也就是ctr预估模型,之前已经介绍过,现在来看pair-wise方式。
pointwise在优化L2 loss ,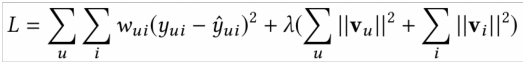
但是很多证据表明
一个低MSE模型不⼀定代表排序效果好。。
– Possible Reasons:
1) 均方误差(e.g., RMSE) and 排序指标之间的分歧
2) 观察有偏 – 用户总是去对喜欢的电影打分 现在的工作开始逐步朝着优化pairwise ranking loss
优化相对序关系,不是优化绝对值。
首先明确排序模型的评价指标:

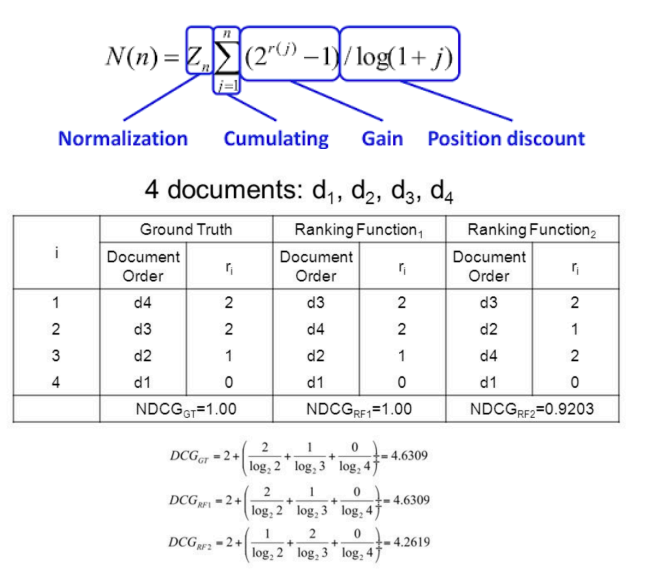
NDCG:
AUC: 有两层含义,1 ROC曲线下的面积,2 任给一个正样本,排在负样本之前的概率有多大。

但是AUC通常不可导:所以引入了BPR,
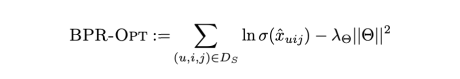
可以看出BPR可以近似看做AUC。类似的还有RankNet,常见的排序指标⽆法求梯度
• 通过概率损失函数学习Ranking Function
• 两个候选集之间的相对排序位置作为⽬标概率
• 交叉熵(cross entropy loss function)作为概率损失函数 ,模型有LambdaNet与LambdaMart,后续总结。