什么是覆盖索引?
解释一: 就是select的数据列只用从索引中就能够取得,不必从数据表中读取,换句话说查询列要被所使用的索引覆盖。
解释二: 索引是高效找到行的一个方法,当能通过检索索引就可以读取想要的数据,那就不需要再到数据表中读取行了。如果一个索引包含了(或覆盖了)满足查询语句中字段与条件的数据就叫做覆盖索引。
(即select和where条件中的字段都出现在索引中,即为覆盖索引)
解释三:是非聚集组合索引的一种形式,它包括在查询里的Select、Join和Where子句用到的所有列(即建立索引的字段正好是覆盖查询语句[select子句]与查询条件[Where子句]中所涉及的字段,也即,索引包含了查询正在查找的所有数据)。
(这里补充下,如果select中包含主键id,也是可以走覆盖索引的,因为非聚簇索引默认就包含主键id,不用回表查询)
总之,不是所有类型的索引都可以成为覆盖索引。覆盖索引必须要存储索引的列的值,而哈希索引、空间索引和全文索引等都不存储索引列的值,所以MySQL只能使用B-Tree索引做覆盖索引。
这里还补充几个非常重要的概念:
要说回表查询,先要从InnoDB的索引实现说起。InnoDB有两大类索引,一类是聚集索引(Clustered Index),一类是普通索引(Secondary Index)。
InnoDB的聚集索引
InnoDB聚集索引的叶子节点存储行记录,因此InnoDB必须要有且只有一个聚集索引。
1.如果表定义了PK(Primary Key,主键),那么PK就是聚集索引。
2.如果表没有定义PK,则第一个NOT NULL UNIQUE的列就是聚集索引。
3.否则InnoDB会另外创建一个隐藏的ROWID作为聚集索引。
(一般聚集索引默认就是主键上面的索引)
这种机制使得基于PK的查询速度非常快,因为直接定位的行记录。
二级索引:又称普遍索引,辅助索引、非聚集索引(no-clustered index),非主键索引。
b+tree树结构,然而二级索引的叶子节点不保存记录中的所有列,其叶子节点保存的是<健值,(记录)地址>,非叶子节点存放的记录格式为<键值,主键值,地址>。而聚集索引叶子节点保存保存记录中的所有列,非叶子节点保存的是下一层节点地址。
例如:
有个t表(id PK, name KEY, sex, flag),这里的id是聚集索引,name则是普通索引。

聚集索引的B+树索引(id是PK,叶子节点存储行记录):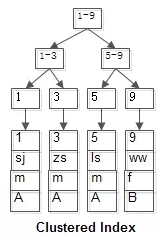
普通索引的B+树索引(name是KEY,叶子节点存储PK值,即id):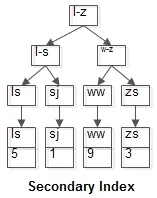
普通索引因为无法直接定位行记录,其查询过程在通常情况下是需要扫描两遍索引树的。
select * from t where name = 'lisi';
这里的执行过程是这样的:
粉红色的路径需要扫描两遍索引树,第一遍先通过普通索引定位到主键值id=5,然后第二遍再通过聚集索引定位到具体行记录。这就是所谓的回表查询,即先定位主键值,再根据主键值定位行记录,性能相对于只扫描一遍聚集索引树的性能要低一些。
索引覆盖是一种避免回表查询的优化策略。具体的做法就是将要查询的数据作为索引列建立普通索引(可以是单列索引,也可以一个索引语句定义所有要查询的列,即联合索引),这样的话就可以直接返回索引中的的数据,不需要再通过聚集索引去定位行记录,避免了回表的情况发生。
只扫描索引而无需回表的优点:
1.索引条目通常远小于数据行大小,只需要读取索引,则mysql会极大地减少数据访问量。
2.因为索引是按照列值顺序存储的,所以对于IO密集的范围查找会比随机从磁盘读取每一行数据的IO少很多。
3.一些存储引擎如myisam在内存中只缓存索引,数据则依赖于操作系统来缓存,因此要访问数据需要一次系统调用
4.innodb的聚簇索引,覆盖索引对innodb表特别有用。(innodb的二级索引在叶子节点中保存了行的主键值,所以如果二级主键能够覆盖查询,则可以避免对主键索引的二次查询)
覆盖索引必须要存储索引列的值,而哈希索引、空间索引和全文索引不存储索引列的值,所以mysql只能用B-tree索引做覆盖索引。
当发起一个索引覆盖查询时,在explain的extra列可以看到using index的信息

覆盖索引的坑:mysql查询优化器会在执行查询前判断是否有一个索引能进行覆盖,假设索引覆盖了where条件中的字段,但不是整个查询涉及的字段,mysql5.5和之前的版本也会回表获取数据行,尽管并不需要这一行且最终会被过滤掉。

如上图则无法使用覆盖查询,原因:
1.没有任何索引能够覆盖这个索引。因为查询从表中选择了所有的列,而没有任何索引覆盖了所有的列。
2.mysql不能在索引中执行LIke操作。mysql能在索引中做最左前缀匹配的like比较,但是如果是通配符开头的like查询,存储引擎就无法做比较匹配。这种情况下mysql只能提取数据行的值而不是索引值来做比较
优化后SQL:添加索引(artist,title,prod_id),使用了延迟关联(延迟了对列的访问)
说明:在查询的第一阶段可以使用覆盖索引,在from子句中的子查询找到匹配的prod_id,然后根据prod_id值在外层查询匹配获取需要的所有值。
5.5时API设计不允许mysql将过滤条件传到存储引擎层(是把数据从存储引擎拉到服务器层,在根据条件过滤),5.6之后由于ICP这个特性改善了查询执行方式
采用执行计划分析覆盖索引:
CREATE TABLE a1
(
id INT AUTO_INCREMENT PRIMARY KEY,
column_name VARCHAR(20),
column_type VARCHAR(20)
);
CREATE INDEX idx_a1_column_name ON a1(column_name);

语句1:它没有使用到索引(Extra:using where),意味着全表扫描,理论如此。(因为索引没覆盖到select中的列)
语句2:它使用了索引范围查找(type=range)(key=idx_a1_column_name),但是它使用**索引方式为二级检索(Extra:Using index condition)**还是会有一定的性能消耗的,也有解决办法:针对select的列创建联合索引。
查询走了索引idx_a1_column_name,但是还需要根据二级索引检测出的结果中的主键id去进行回表查询。
语句3:虽然是全匹配模糊查询,但是使用了索引覆盖(Extra:Using index)
因为普通索引中已经包含了主键id的值,不需要再进行回表查询。
所以性能比(Extra:Using index condition)的快。
结论:
using index :使用覆盖索引的时候就会出现
using where:未使用索引,需要全表查询
using index condition:查找使用了索引,但是需要回表查询数据
using index & using where:查找使用了索引,但是需要的数据都在索引列中能找到,所以不需要回表查询数据。
实验证明using index & using where要优于using index condition。
不得不说,这篇文章刷新了对mysql中索引使用的认知,特别是通过延迟关联(延迟了对列的访问)使用覆盖索引的方式,堪称经典,很值得学习。