目录结构
2.3.第三步:启动django项目【helloworld】服务
2.4.第四步:通过任一浏览器访问url地址【http://127.0.0.1:8000/search_person_data/】后查看展示数据
2.5.第五步:复制接口返回值去【https://www.json.cn/】进行json数据在线解析和格式化,方便直观查看数据
1.前言
首先,整体的开发思路是:比如一个前端开发人员A和一个后端开发人员B,一起联调一个【查询用户数据】功能,那么前端开发人员A就负责【查询用户数据的页面】的开发,后端开发人员B就负责【查询用户数据的接口】的开发且开发完成且自测通过后提供给前端开发人员A进行联调。
我们要知道,前端开发人员A和后端开发人员B一起开发这个功能的前提都是要严格产品人员编写的需求文档和原型图进行开发的。
所以前端开发人员A在实际开发过程中会要求后端开发人员提供的【查询用户数据的接口】的返回值必须满足这两点:
⑴.必须有返回前端开发人员A需要的所有字段和字段值信息,因为前端开发人员才能拿到这些数据去进行自测确保数据都没遗漏;
⑵.每个字段值的数据结构要满足前端开发人员A的要求,因为前端开发人员A会拿到这样的字段值直接去做相关处理而不需要对字段值的数据结构进行二次处理从而能提高前端开发人员A的开发效率也能提高数据的加载效率。
细节:
①.在django框架里,接口其实就是视图函数,只是称呼不一致而已。
②.后续涉及的前后端接口联调流程,基本按照这样的思路去进行即可。
2.进行实际的一个完整流程操作
2.1.第一步:编写一个用于查询用户数据的视图函数
# 该视图函数的作用:按照不同条件,来获取hello_person表指定的数据。 def search_person(request): # 进行实际的一个完整流程操作 try: res = Person.objects.all().values() res = list(res) except: raise("查询语句执行过程中出现报错信息,程序终止执行!") data = {} # 初始化一个空dict,用于存储要返回给前端页面的所有字段和对应字段值,且字段对应字典的key,字段值对应字典的value; if len(res) != 0: # 对查询到的数据做相关判断,从而执行不同的代码分支; data["result"] = res # 1.第一步:把数据表的相关数据都存储在这个key【result】; data["code"] = 200 # 2.第二步:把状态码200的值存储在这个key【code】; data["success"] = True # 3.第三步:把状态success的值存储在这个key【success】; data["msg"] = "获取数据成功!" # 4.第四步:把信息的值存储在这个key【msg】; else: data["result"] = res data["code"] = 100 data["success"] = False data["msg"] = "获取不到数据!" return JsonResponse(data,json_dumps_params={"ensure_ascii":False})
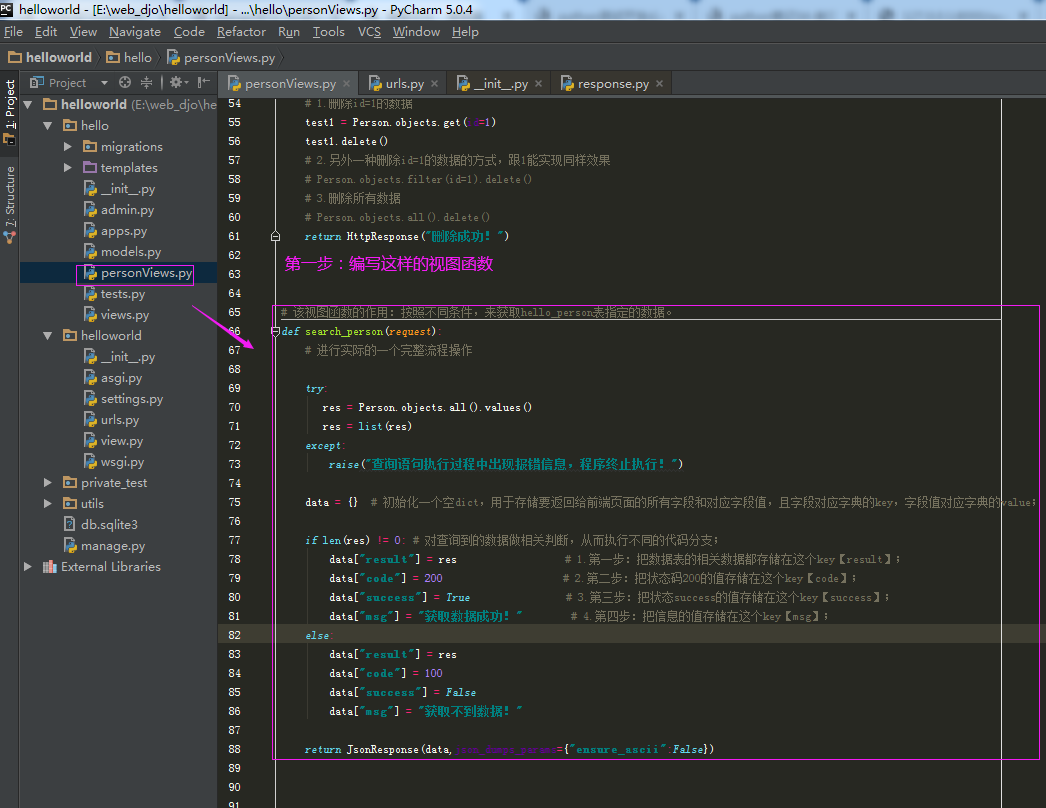
2.2.第二步:编写对应的一个url匹配规则
细节:
①.url匹配规则在之前已经配置好了,在之前的博客文章里可以找到对应内容,在这篇博客里不再继续重复写一遍了;
2.3.第三步:启动django项目【helloworld】服务
2.4.第四步:通过任一浏览器访问url地址【http://127.0.0.1:8000/search_person_data/】后查看展示数据
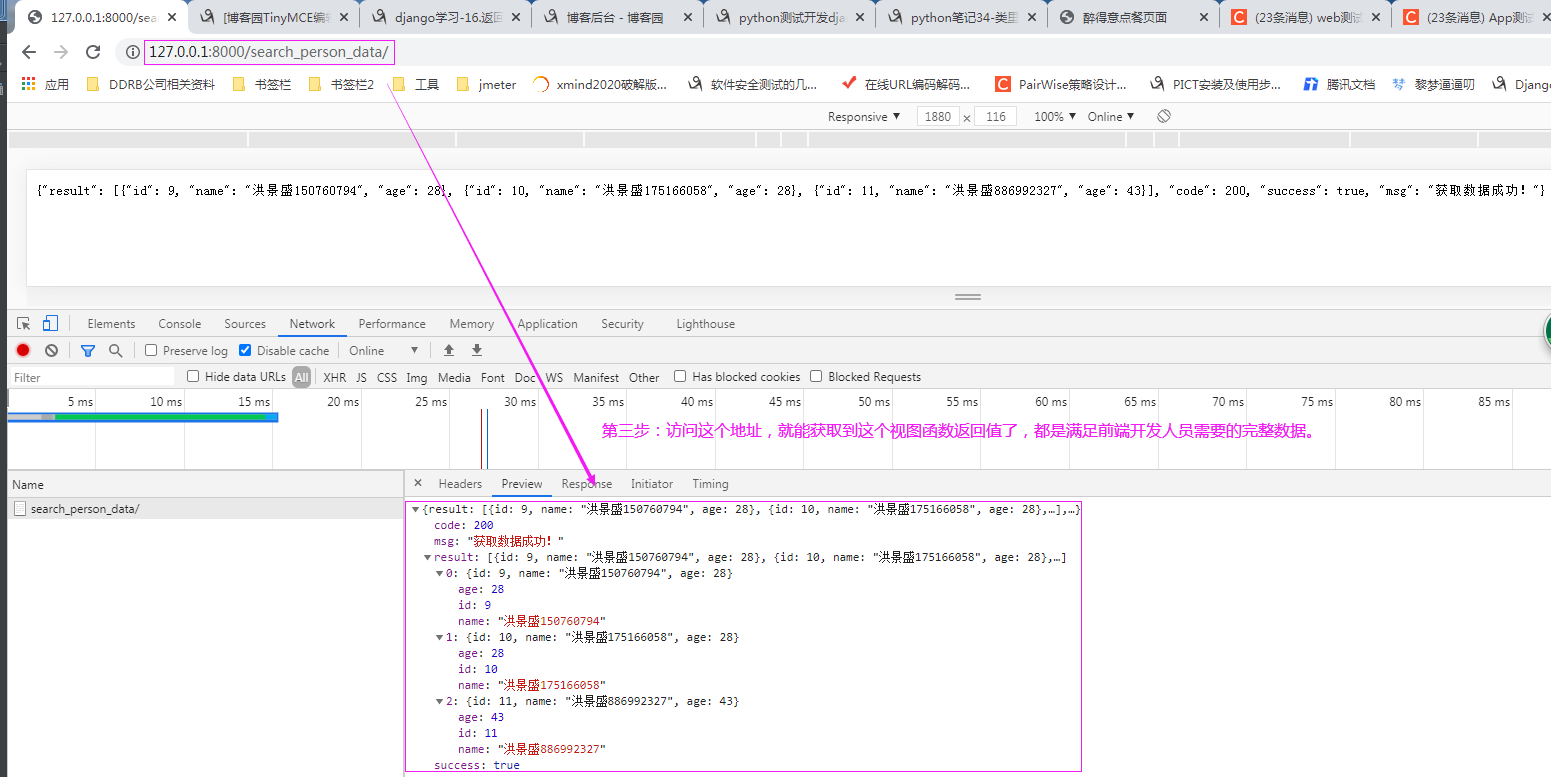
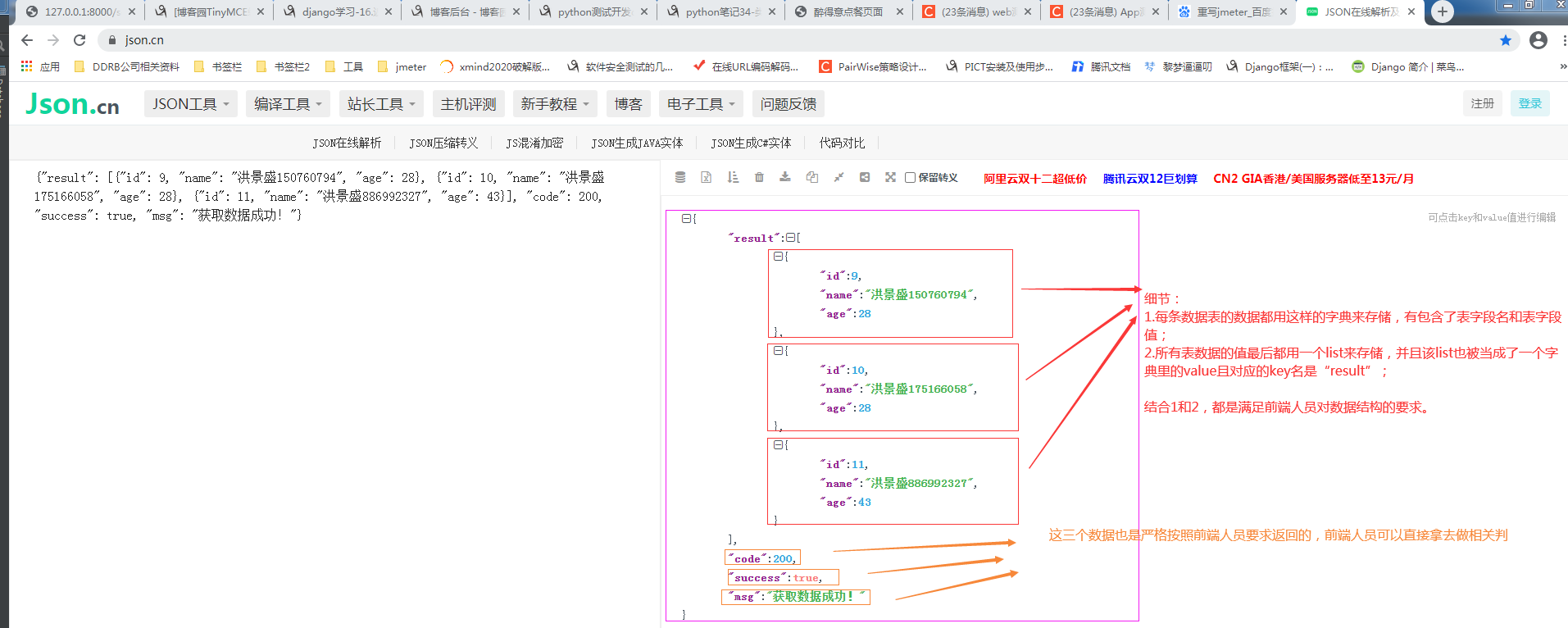
2.5.第五步:复制接口返回值去【https://www.json.cn/】进行json数据在线解析和格式化,方便直观查看数据
{
"result":[
{
"id":9,
"name":"洪景盛150760794",
"age":28
},
{
"id":10,
"name":"洪景盛175166058",
"age":28
},
{
"id":11,
"name":"洪景盛886992327",
"age":43
}
],
"code":200,
"success":true,
"msg":"获取数据成功!"
}