小数据池/常量池(坑,别纠结) :
小数据池 一种数据缓存机制.也被称为驻留机制
用缓存的前提: 数据可以被共享。不可变数据类型
作用/意义:把数据存在小数据池 快速创建对象 共享 节省内存 解释字符串赋值问题等
python中只针对:整数,字符串串,布尔值 注意共享的是不可改变的数据类型
id() is ==
1 # id() 查看一个变量表示的值的内存地址 2 a = 1000 3 b = 1000 4 c = "lijie" 5 print(id(a)) # 2602674608112 内存地址 6 print(id(b)) # 2602674608112 7 print(id(c)) # 2602703864248 8 9 # == 判断左右两边的值是否一致 10 print(a == b) # 判断左右两边的值 11 print(a == c) 12 13 # is 判断左右两边的内容地址是否一致 14 print(a is b) # 判断左右两边内容地址 15 print(b is c)
缓存
为什么有缓存 数据保存安全 速度快 加大吞吐量 分布式 异地部署(如 Google无盘数据中心)
单纯的创建变量。都是有缓存的
1 # 单纯的创建变量。都是有缓存的 2 a = 49876 3 b = 49876 4 print(a is b) # True 5 a = 49786*20 6 b = 49786*20 7 print(a is b) # True
注意 在命令行中(command模式) 小数据池 int取值范围在[-5,256]
1 # 注意 在命令行中(command模式) 小数据池 int取值范围在[-5,256] 2 a = 2000 3 b = 2000 4 print(a is b) # 在py文件里面是True
但在命令行中:
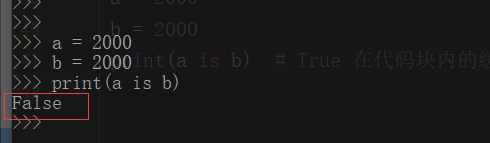
原因: 在代码块内的缓存机制是不一样的 故在py文件里面是True 在command模式中是False
数据池不必纠结,了解会用就好,官方也没详细解释。
编码 转码:
python3中使用的是unicode,python2中使用的是ascii码,但unicode 太长适合计算不适合存储. utf-8适合存储和传输.因此需要用用到编码转换.
编码: .encode()
注意编码和解码时都需要制定编码格式.
1 #.encode() 2 s = "嘿en哈" 3 s0 = "JJ" 4 bs = s.encode("utf-8") # 制定utf-8格式 5 bs0 = s0.encode("utf-8") 6 # 英文编码之后结果和源字符串一致.中文编码之后的结果根据编码不同.编码结果不同. 7 print(bs0) # b'JJ' 英文编码后和原来一致 8 print(bs) # b'xe5x98xbfenxe5x93x88' 一个中文utf-8三字节 9 bs0 = s0.encode("gbk") 10 bs = s.encode("gbk") 11 print(bs0) # b'JJ' 12 print(bs) # b'xbaxd9enxb9xfe' 一个中文gbk 两字节
解码:.decode()
1 j = b'xbaxd9enxb9xfe' 2 j1 = j.decode("gbk") 3 print(j1)
编码:存储和传输时 encode()
解码:接收数据时 decode()
b'xxxxx'这种格式的数据是bytes类型的数据 bytes是python中的最小数据单元
数据传输(包括文字/图片/视频)都是bytes(如直播)————流程:编码——推流——解码——用户
1 # 练习 把一个utf-8编码变成GBK编码 2 bm = b'xe5x98xbfenxe5x93x88' 3 4 bm0 = bm.decode() # 先解码成Unicode 5 bm1 = bm0.encode("gbk") # 再编码成gbk 6 print(bm1)