nimbus 英 [ˈnɪmbəs] 美 [ˈnɪmbəs] n. (大片的)雨云;光环
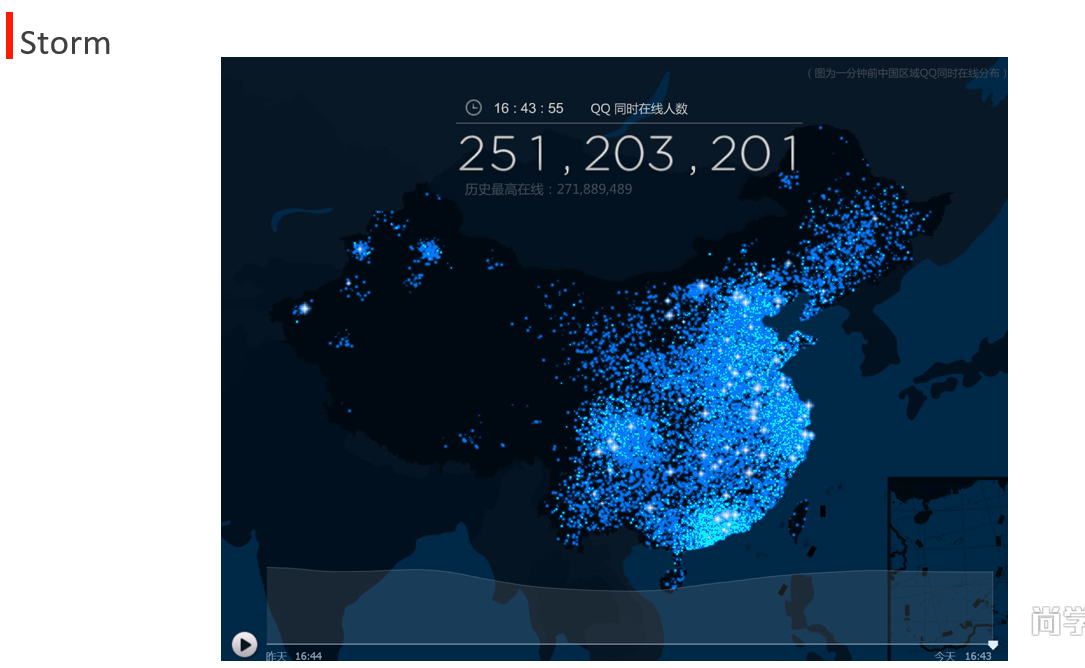
strom 分布式实时的流式计算框架
strom如下图右侧,来一个数据,处理一个,单位时间内处理的数据量不能太大,以保证它的正常运行,但是一旦启动一直运行。
批处理则不同,spark则是微批处理框架的计算框架,也能够达到实时性。
MR 做不到实时性,数量级是TB,PB级的,频繁操作磁盘,频繁启停job.





ETL(数据清洗)extracted transform load
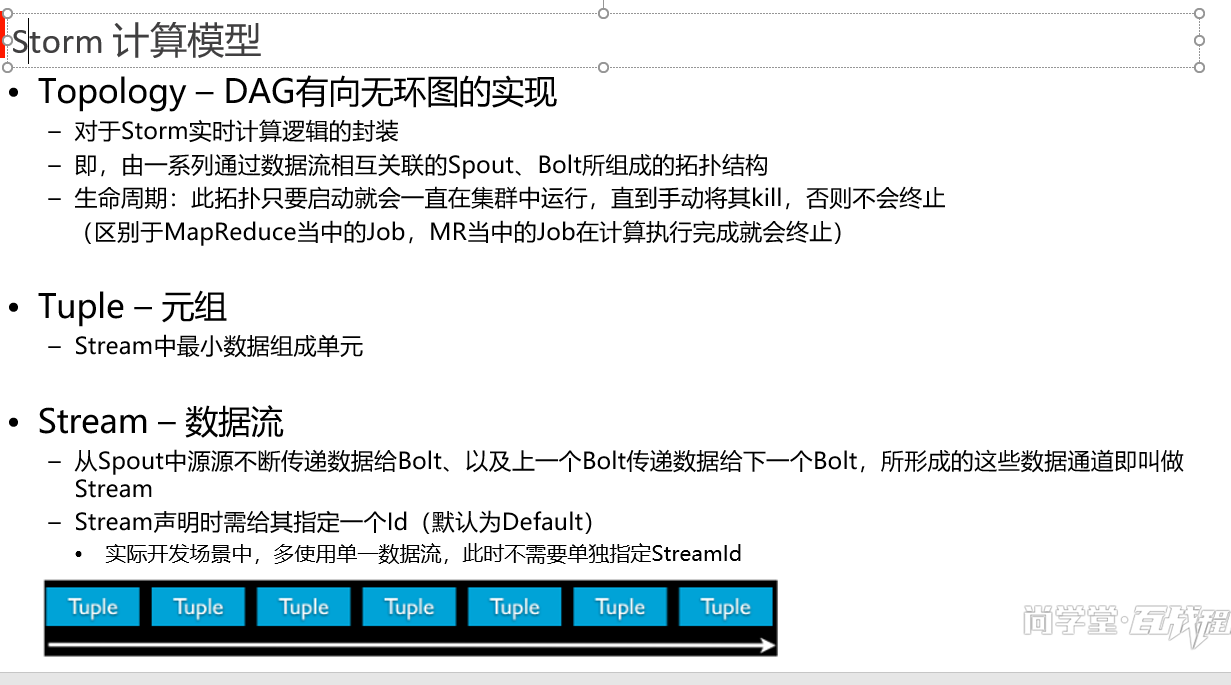
Spout
英 [spaʊt] 美 [spaʊt]
壶嘴;喷出;喷口;管口;龙卷
bolt
英 [bəʊlt] 美 [boʊlt]
n.
(门窗的)闩,插v.
用插销闩上;能被闩上;用螺栓把(甲和乙)固定在一起;(马等受惊)脱缰 adv. 突然地;像箭似地;直立地
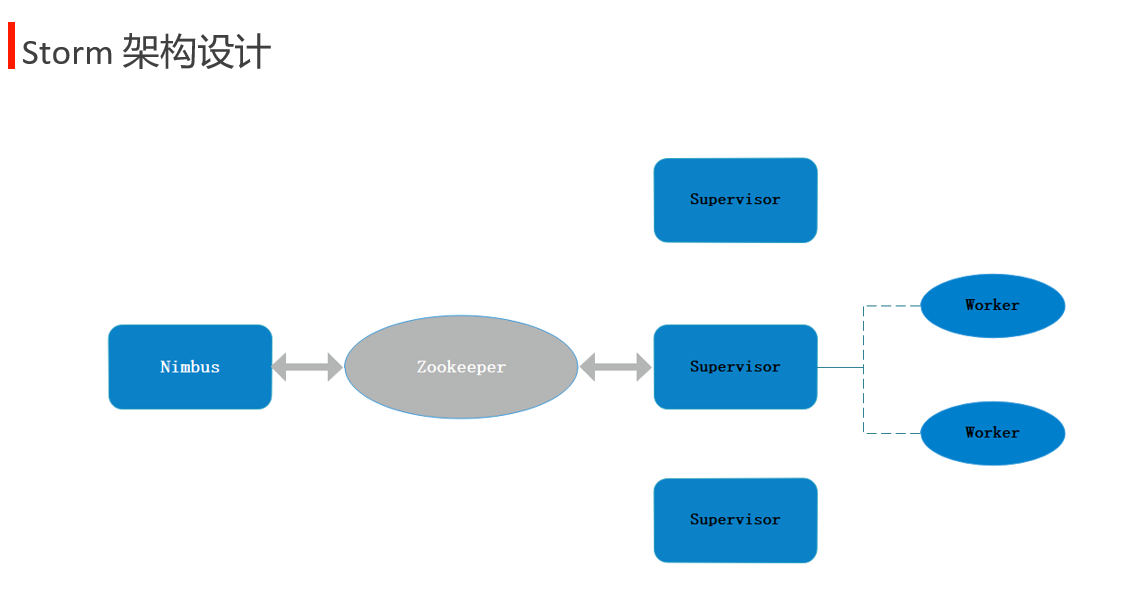
Nimbus 类似于 master supervisor 类似于 slave
worker task







strom 数据累加 strom 运行模式 strom local 模式, strom 集群运行 jar


本地模式运行strom程序
// 累加案例
package com.bjsxt.sum;
import java.util.List;
import java.util.Map;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.utils.Utils;
public class WsSpout extends BaseRichSpout {
Map map;
int i =0;
TopologyContext context;
SpoutOutputCollector collector;
/**
* 配置初始化spout类
*/
@Override
public void open(Map map, TopologyContext context, SpoutOutputCollector collector) {
this.map = map;
this.context = context;
this.collector = collector;
}
/**
* 采集并向后推送数据
*/
@Override
public void nextTuple() {
i++;
List<Object> num = new Values(i);
this.collector.emit(num);
System.out.println("spout--------------" + i);
Utils.sleep(1000);
}
/**
* 向接收数据的逻辑处理单元声明发送数据的字段名称
* @param arg0
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("num"));
}
}
package com.bjsxt.sum;
import java.util.Map;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichBolt;
import backtype.storm.tuple.Tuple;
public class WsBolt extends BaseRichBolt {
Map stormConf;
TopologyContext context;
OutputCollector collector;
int sum = 0;
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.stormConf = stormConf;
this.context = context;
this.collector = collector;
}
/**
* 获取数据,(有必要的话,向后发送数据)
*/
@Override
public void execute(Tuple input) {
// input.getInteger(0);// offset
Integer num = input.getIntegerByField("num");
sum += num;
// 展示积累的数据
System.out.println("bolt------------ sum=" + sum);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// TODO Auto-generated method stub
}
}
package com.bjsxt.sum;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
public class Test {
/**
* 建立拓扑结构,放入集群运行
* @param args 命令行参数
*/
public static void main(String[] args) {
// 构建strom拓扑结构
TopologyBuilder tb = new TopologyBuilder();
tb.setSpout("wsspout", new WsSpout());
// 规定上一步的分发策略 shuffleGrouping cpoutid
tb.setBolt("wsblot", new WsBolt()).shuffleGrouping("wsspout");
// 创建本地strom集群
LocalCluster lc = new LocalCluster();
lc.submitTopology("wordsum", new Config(), tb.createTopology());
}
}
// word count 案例,多个bolt
package com.bjsxt.wc;
import java.util.Map;
import java.util.Random;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.utils.Utils;
public class WcSpout extends BaseRichSpout {
SpoutOutputCollector collector;
// 准备原始数据
String[] text = {
"helo sxt bj",
"sxt nihao world",
"bj nihao hi"
};
Random r = new Random();
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
}
// 随机发送每一行字符串
@Override
public void nextTuple() {
Values line = new Values(text[r.nextInt(text.length)]);
this.collector.emit(line);
System.out.println("spout emit ---------" + line);
Utils.sleep(1000);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("line"));
}
}
package com.bjsxt.wc;
import java.util.List;
import java.util.Map;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
public class WsplitBolt extends BaseRichBolt{
OutputCollector collector;
/**
* 获取tuple每一行数据
*/
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple input) {
String line = input.getString(0);
// 切割
String[] words = line.split(" ");
for (String w : words) {
List wd = new Values(w);
this.collector.emit(wd);
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("w"));
}
}
package com.bjsxt.wc;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
public class WcountBolt extends BaseRichBolt{
Map<String,Integer> wcMap = new HashMap<>(); // key 出现的单词, value 出现的次数
/**
* 获取tuple每一行数据
*/
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
}
/**
* 获取tuple每一个单词,并且按照单词统计输出出现的次数
*/
@Override
public void execute(Tuple input) {
// 获取单词
String word = input.getStringByField("w");
Integer count = 1;
// 如果map中已经出现过该单词,
if(wcMap.containsKey(word)){
count = (int)wcMap.get(word) + 1;
}
wcMap.put(word, count);
System.out.println("("+word + ","+ count +")" );
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
package com.bjsxt.wc;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.tuple.Fields;
public class Test {
/**
* 建立拓扑结构,放入集群运行
* @param args 命令行参数
*/
public static void main(String[] args) {
// 构建strom拓扑结构
TopologyBuilder tb = new TopologyBuilder();
tb.setSpout("wcspout", new WcSpout());
tb.setBolt("wsplitblot", new WsplitBolt()).shuffleGrouping("wcspout");
// 多个bolt 各自统计,map中各自有一部分统计数据
// 使用fieldsGrouping则可以按fields统计// 只要有一个单词在某一个bolt上,第二次也必须分发到这个bolt上,
// 1个并行度,如下会统计有错
// tb.setBolt("wcountbolt", new WcountBolt()).shuffleGrouping("wsplitblot");
// 3个并行度,如下会统计有错
// tb.setBolt("wcountbolt", new WcountBolt(),3).shuffleGrouping("wsplitblot");
// 多个并行度,按如下统计
tb.setBolt("wcountbolt", new WcountBolt(),3).fieldsGrouping("wsplitblot", new Fields("w"));
// 创建本地strom集群
LocalCluster lc = new LocalCluster();
lc.submitTopology("wordcount", new Config(), tb.createTopology());
}
}
// 分发策略演示
trace.log
www.taobao.com XXYH6YCGFJYERTT834R52FDXV9U34 2017-02-21 12:40:49
www.taobao.com XXYH6YCGFJYERTT834R52FDXV9U34 2017-02-21 09:40:49
www.taobao.com XXYH6YCGFJYERTT834R52FDXV9U34 2017-02-21 08:40:51
www.taobao.com VVVYH6Y4V4SFXZ56JIPDPB4V678 2017-02-21 12:40:49
www.taobao.com BBYH61456FGHHJ7JL89RG5VV9UYU7 2017-02-21 08:40:51
package com.sxt.storm.grouping;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.util.Map;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichSpout;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
public class MySpout implements IRichSpout {
private static final long serialVersionUID = 1L;
FileInputStream fis;
InputStreamReader isr;
BufferedReader br;
SpoutOutputCollector collector = null;
String str = null;
@Override
public void nextTuple() {
try {
while ((str = this.br.readLine()) != null) {
// 过滤动作
collector.emit(new Values(str, str.split(" ")[1]));
}
} catch (Exception e) {
}
}
@Override
public void close() {
try {
br.close();
isr.close();
fis.close();
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
try {
this.collector = collector;
this.fis = new FileInputStream("track.log");
this.isr = new InputStreamReader(fis, "UTF-8");
this.br = new BufferedReader(isr);
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// 发送几个元素,需要对应几个字段
declarer.declare(new Fields("log", "session_id"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
@Override
public void ack(Object msgId) {
System.out.println("spout ack:" + msgId.toString());
}
@Override
public void activate() {
}
@Override
public void deactivate() {
}
@Override
public void fail(Object msgId) {
System.out.println("spout fail:" + msgId.toString());
}
}
package com.sxt.storm.grouping;
import java.util.Map;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
public class MyBolt implements IRichBolt {
private static final long serialVersionUID = 1L;
OutputCollector collector = null;
int num = 0;
String valueString = null;
@Override
public void cleanup() {
}
@Override
public void execute(Tuple input) {
try {
valueString = input.getStringByField("log");
if (valueString != null) {
num++;
System.err.println(input.getSourceStreamId() + " " + Thread.currentThread().getName() + "--id="
+ Thread.currentThread().getId() + " lines :" + num + " session_id:"
+ valueString.split(" ")[1]);
}
collector.ack(input);
// Thread.sleep(2000);
} catch (Exception e) {
collector.fail(input);
e.printStackTrace();
}
}
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields(""));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}
package com.sxt.storm.grouping;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.StormSubmitter;
import backtype.storm.generated.AlreadyAliveException;
import backtype.storm.generated.InvalidTopologyException;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.tuple.Fields;
public class Main {
/**
* @param args
*/
public static void main(String[] args) {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout", new MySpout(), 1);
// shuffleGrouping其实就是随机往下游去发,不自觉的做到了负载均衡
// builder.setBolt("bolt", new MyBolt(), 2).shuffleGrouping("spout");
// fieldsGrouping其实就是MapReduce里面理解的Shuffle,根据fields求hash来取模
// builder.setBolt("bolt", new MyBolt(), 2).fieldsGrouping("spout", new Fields("session_id"));
// 只往一个里面发,往taskId小的那个里面去发送
// builder.setBolt("bolt", new MyBolt(), 2).globalGrouping("spout");
// 等于shuffleGrouping
// builder.setBolt("bolt", new MyBolt(), 2).noneGrouping("spout");
// 广播
builder.setBolt("bolt", new MyBolt(), 2).allGrouping("spout");
// Map conf = new HashMap();
// conf.put(Config.TOPOLOGY_WORKERS, 4);
Config conf = new Config();
conf.setDebug(false);
conf.setMessageTimeoutSecs(30);
if (args.length > 0) { // 集群中运行时,执行此处
try {
StormSubmitter.submitTopology(args[0], conf, builder.createTopology());
} catch (AlreadyAliveException e) {
e.printStackTrace();
} catch (InvalidTopologyException e) {
e.printStackTrace();
}
} else {
LocalCluster localCluster = new LocalCluster();
localCluster.submitTopology("mytopology", conf, builder.createTopology());
}
}
}

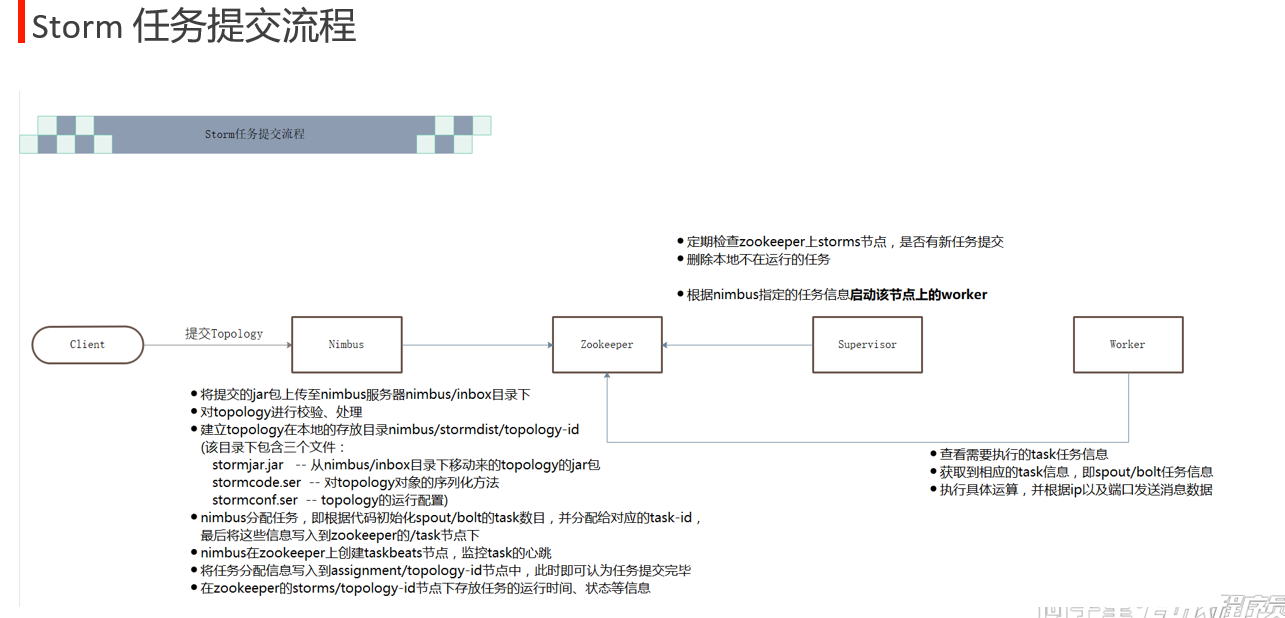
worker 直接从zookeeper中获取任务




Strom 伪分布式部署 node1 nimbus , zookeeper supervisor worker 都在node1上。 步骤: [root@node1 software]# tar -zxvf apache-storm-0.10.0.tar.gz -C /opt/sxt/ [root@node1 sxt]# cd apache-storm-0.10.0/ [root@node1 apache-storm-0.10.0]# mkdir logs ## 存储日志文件 [root@node1 apache-storm-0.10.0]# ./bin/storm help [root@node1 apache-storm-0.10.0]# ./bin/storm dev-zookeeper >> ./logs/dev-zookeeper.out 2>&1 & ## 启动自带zookeeper程序 [root@node1 apache-storm-0.10.0]# jps ## 查看程序,还在配置中,未启动完成 6838 Jps 6828 config_value [root@node1 apache-storm-0.10.0]# jps ## 启动成功, 6795 dev_zookeeper 6859 Jps [root@node1 apache-storm-0.10.0]# ./bin/storm nimbus >> ./logs/nimbus.out 2>&1 & [2] 6873 [root@node1 apache-storm-0.10.0]# jps 6884 config_value 6795 dev_zookeeper 6894 Jps [root@node1 apache-storm-0.10.0]# jps 6981 Jps 6873 nimbus 6795 dev_zookeeper [root@node1 apache-storm-0.10.0]# ./bin/storm supervisor >> ./logs/supervisor.out 2>&1 & [root@node1 apache-storm-0.10.0]# ./bin/storm ui >> ./logs/ui.out 2>&1 & [root@node1 apache-storm-0.10.0]# jps 7104 core ## ui 7191 Jps 6873 nimbus 6795 dev_zookeeper 7004 supervisor [root@node1 apache-storm-0.10.0]# ss -nal tcp LISTEN 0 50 :::8080 http://node1:8080 ui首页

准备提交任务到storm
// 修改wordcount代码:
// 如果args传参表示提交到strom
package com.bjsxt.wc;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.StormSubmitter;
import backtype.storm.generated.AlreadyAliveException;
import backtype.storm.generated.InvalidTopologyException;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.tuple.Fields;
public class Test {
/**
* 建立拓扑结构,放入集群运行
* @param args 命令行参数
*/
public static void main(String[] args) {
// 构建strom拓扑结构
TopologyBuilder tb = new TopologyBuilder();
tb.setSpout("wcspout", new WcSpout());
tb.setBolt("wsplitblot", new WsplitBolt()).shuffleGrouping("wcspout");
// 多个bolt 各自统计,map中各自有一部分统计数据
// 使用fieldsGrouping则可以按fields统计// 只要有一个单词在某一个bolt上,第二次也必须分发到这个bolt上,
// 1个并行度,如下会统计有错
// tb.setBolt("wcountbolt", new WcountBolt()).shuffleGrouping("wsplitblot");
// 3个并行度,如下会统计有错
// tb.setBolt("wcountbolt", new WcountBolt(),3).shuffleGrouping("wsplitblot");
// 多个并行度,按如下统计
tb.setBolt("wcountbolt", new WcountBolt(),3).fieldsGrouping("wsplitblot", new Fields("w"));
Config conf = new Config();
if(args.length > 0){ // 如果传入参数,则是提交到集群
try {
StormSubmitter.submitTopology(args[0], conf, tb.createTopology());
} catch (AlreadyAliveException | InvalidTopologyException e) {
e.printStackTrace();
}
}else{
// 创建本地strom集群
LocalCluster lc = new LocalCluster();
lc.submitTopology("wordcount", conf, tb.createTopology());
}
}
}
## 将wordcount 打包,上传到node1
[root@node1 apache-storm-0.10.0]# pwd
/opt/sxt/apache-storm-0.10.0
[root@node1 apache-storm-0.10.0]# ./bin/storm help jar ## 查看帮助
Syntax: [storm jar topology-jar-path class ...]
##演示 运行程序,
[root@node1 apache-storm-0.10.0]# ./bin/storm jar ~/software/WCDemo.jar
com.bjsxt.wc.Test
##演示提交程序 wc 标识args.length > 0 ,提交
[root@node1 apache-storm-0.10.0]# ./bin/storm jar ~/software/WCDemo.jar com.bjsxt.wc.Test wc
## 查看提交的topology [root@node1 apache-storm-0.10.0]# cd /opt/sxt/apache-storm-0.10.0/storm-local/nimbus/inbox/ [root@node1 inbox]# ls stormjar-e2c773e5-be65-4ede-a243-7d51e52371c4.jar

如下拓扑图

strom 依赖 jdk1.6以上,python2.6.6+
分布式部署:
node2,3,4 有zookeeper
node2 nimbus node3,node4 supervisor. ( 各自自己本机拥有4个worker)
[root@node2 software]# python
Python 2.7.5 (default, Oct 30 2018, 23:45:53)
[root@node2 software]# java -version
java version "1.8.0_221"
node2
tar -zxvf apache-storm-0.10.0.tar.gz -C /opt/sxt/
cd apache-storm-0.10.0/conf/
vi storm.yaml
[root@node2 conf]# cat storm.yaml
## 增加如下配置 supervisor.slots.ports 表示每个supervisor下的worker,
storm.zookeeper.servers:
- "node2"
- "node3"
- "node4"
#
nimbus.host: "node2"
storm.local.dir: "/var/storm"
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
#
[root@node2 apache-storm-0.10.0]# mkdir logs
分发到node3,4
[root@node2 sxt]# scp -r apache-storm-0.10.0 node3:`pwd`
启动node,2,3,4 zk
/opt/sxt/zookeeper-3.4.6/bin/zkServer.sh start
## node2 nimbus
[root@node2 apache-storm-0.10.0]# ./bin/storm nimbus >> ./logs/nimbus.out 2>&1 &
[root@node2 apache-storm-0.10.0]# ./bin/storm ui >> ./logs/ui.out 2>&1 &
## node3,4 各自启动supervisor
[root@node4 apache-storm-0.10.0]# ./bin/storm supervisor >> ./logs/supervisor.out 2>&1 &
[root@node3 apache-storm-0.10.0]# ./bin/storm supervisor >> ./logs/supervisor.out 2>&1 &
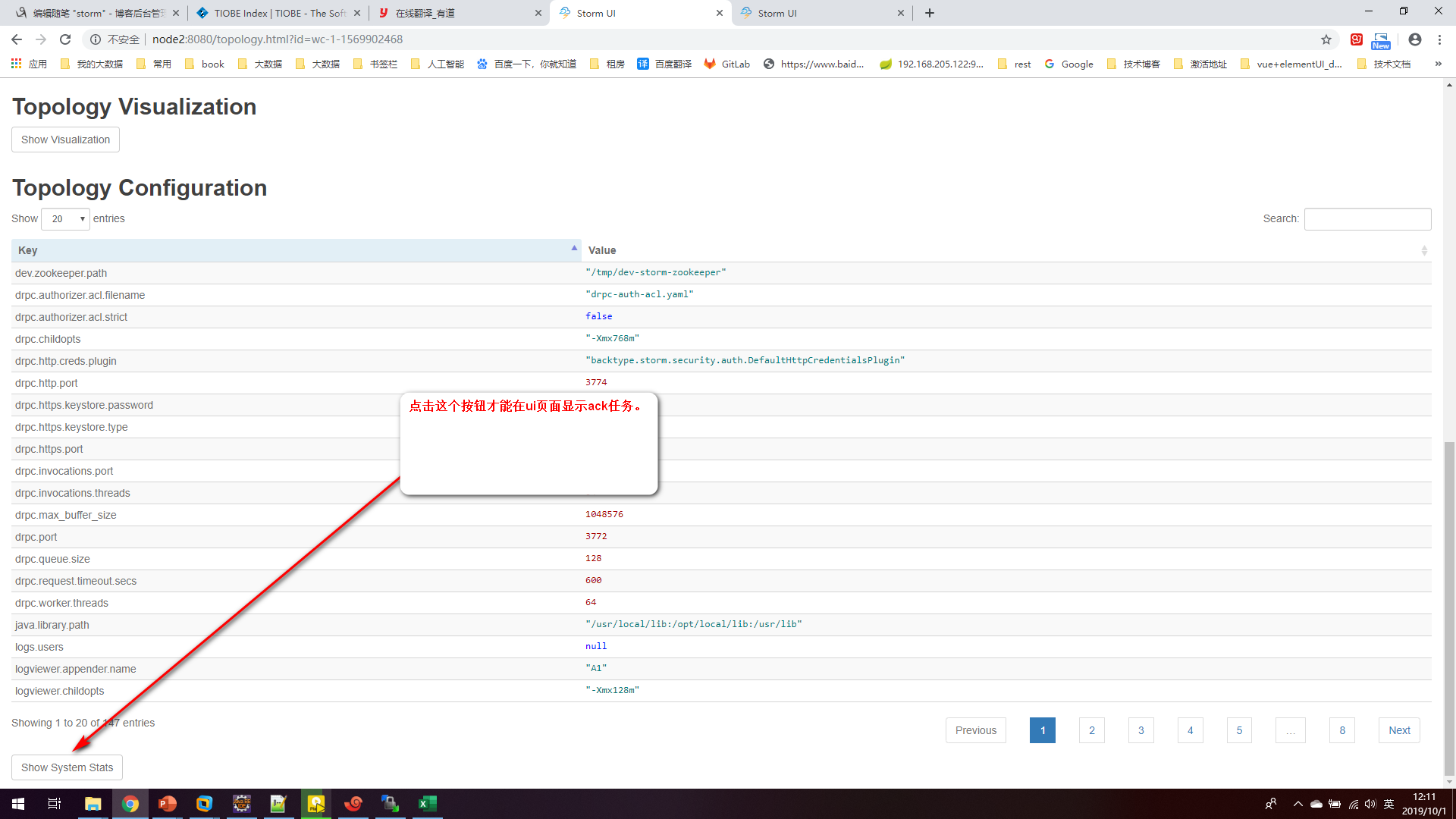
// 提交任务 修改wordcount 如下:
package com.bjsxt.wc;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.StormSubmitter;
import backtype.storm.generated.AlreadyAliveException;
import backtype.storm.generated.InvalidTopologyException;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.tuple.Fields;
public class Test {
/**
* 建立拓扑结构,放入集群运行
* @param args 命令行参数
*/
// public static void main(String[] args) {
//
// // 构建strom拓扑结构
// TopologyBuilder tb = new TopologyBuilder();
//
// tb.setSpout("wcspout", new WcSpout());
//
// tb.setBolt("wsplitblot", new WsplitBolt()).shuffleGrouping("wcspout");
// // 多个bolt 各自统计,map中各自有一部分统计数据
// // 使用fieldsGrouping则可以按fields统计// 只要有一个单词在某一个bolt上,第二次也必须分发到这个bolt上,
// // 1个并行度,如下会统计有错
//// tb.setBolt("wcountbolt", new WcountBolt()).shuffleGrouping("wsplitblot");
// // 3个并行度,如下会统计有错
//// tb.setBolt("wcountbolt", new WcountBolt(),3).shuffleGrouping("wsplitblot");
// // 多个并行度,按如下统计
// tb.setBolt("wcountbolt", new WcountBolt(),3).fieldsGrouping("wsplitblot", new Fields("w"));
//
//
// Config conf = new Config();
// if(args.length > 0){ // 如果传入参数,则是提交到集群
// try {
// StormSubmitter.submitTopology(args[0], conf, tb.createTopology());
// } catch (AlreadyAliveException | InvalidTopologyException e) {
// e.printStackTrace();
// }
// }else{
// // 创建本地strom集群
// LocalCluster lc = new LocalCluster();
// lc.submitTopology("wordcount", conf, tb.createTopology());
// }
//
// }
//
/**
* 建立拓扑结构,放入集群运行
* @param args 命令行参数
*/
public static void main(String[] args) {
// 构建strom拓扑结构
TopologyBuilder tb = new TopologyBuilder();
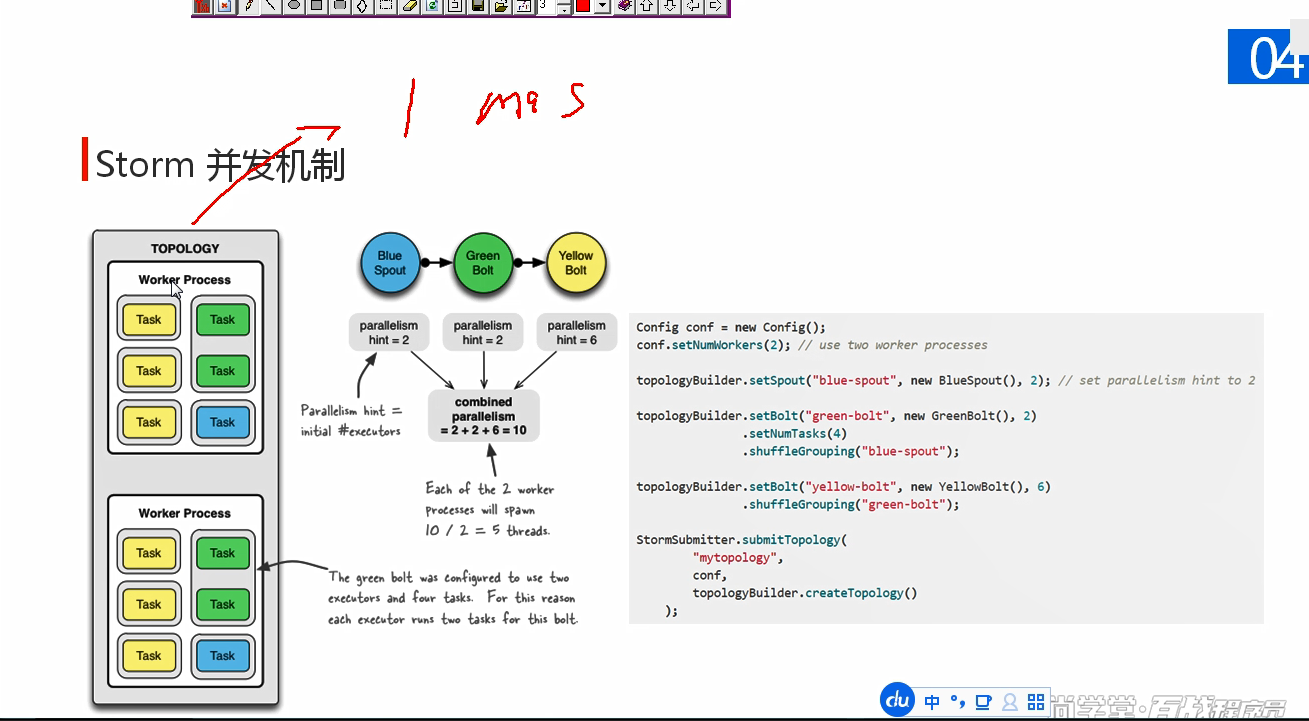
tb.setSpout("wcspout", new WcSpout(),2);
tb.setBolt("wsplitblot", new WsplitBolt(),4).shuffleGrouping("wcspout");
tb.setBolt("wcountbolt", new WcountBolt(),2).setNumTasks(4).fieldsGrouping("wsplitblot", new Fields("w"));
// 共10个任务
Config conf = new Config();
conf.setNumWorkers(2);
if(args.length > 0){ // 如果传入参数,则是提交到集群
try {
StormSubmitter.submitTopology(args[0], conf, tb.createTopology());
} catch (AlreadyAliveException | InvalidTopologyException e) {
e.printStackTrace();
}
}else{
// 创建本地strom集群
LocalCluster lc = new LocalCluster();
lc.submitTopology("wordcount", conf, tb.createTopology());
}
}
}
[root@node3 apache-storm-0.10.0]# ./bin/storm jar ~/software/WCDemo.jar com.bjsxt.wc.Test wc
## 在主节点上才能查看到上传的jar包
[root@node2 apache-storm-0.10.0]# cd /var/storm/nimbus/inbox/
[root@node2 inbox]# ls
stormjar-992586f4-b8a5-442a-828c-d41c1f828dd4.jar
## ui页面查看wc executor task ## 其中每个worker上都有ack也会拥有executor
## 修改wcountbolt executor数量
[root@node2 apache-storm-0.10.0]# ./bin/storm help rebalance
[root@node2 apache-storm-0.10.0]# ./bin/storm rebalance wc -n 4 -e wcountbolt=4
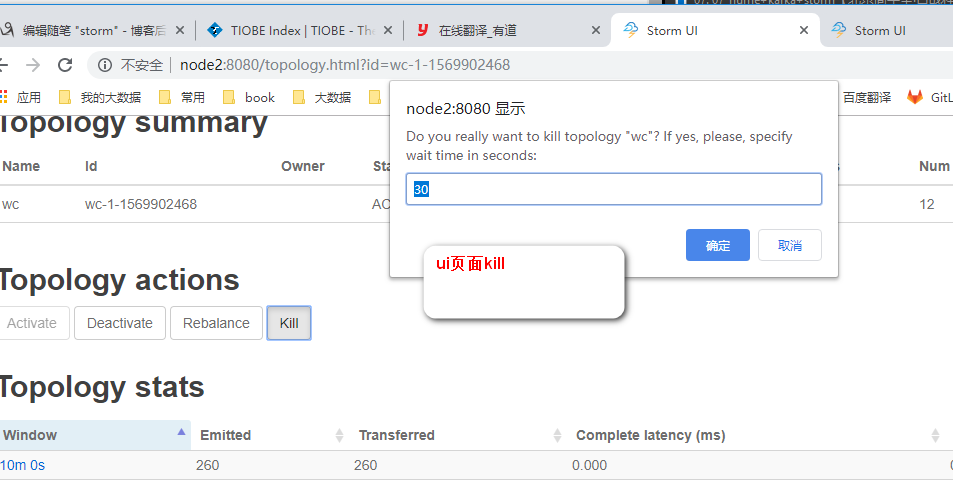
kill后的结果


上图表示两个线程共跑四个任务。


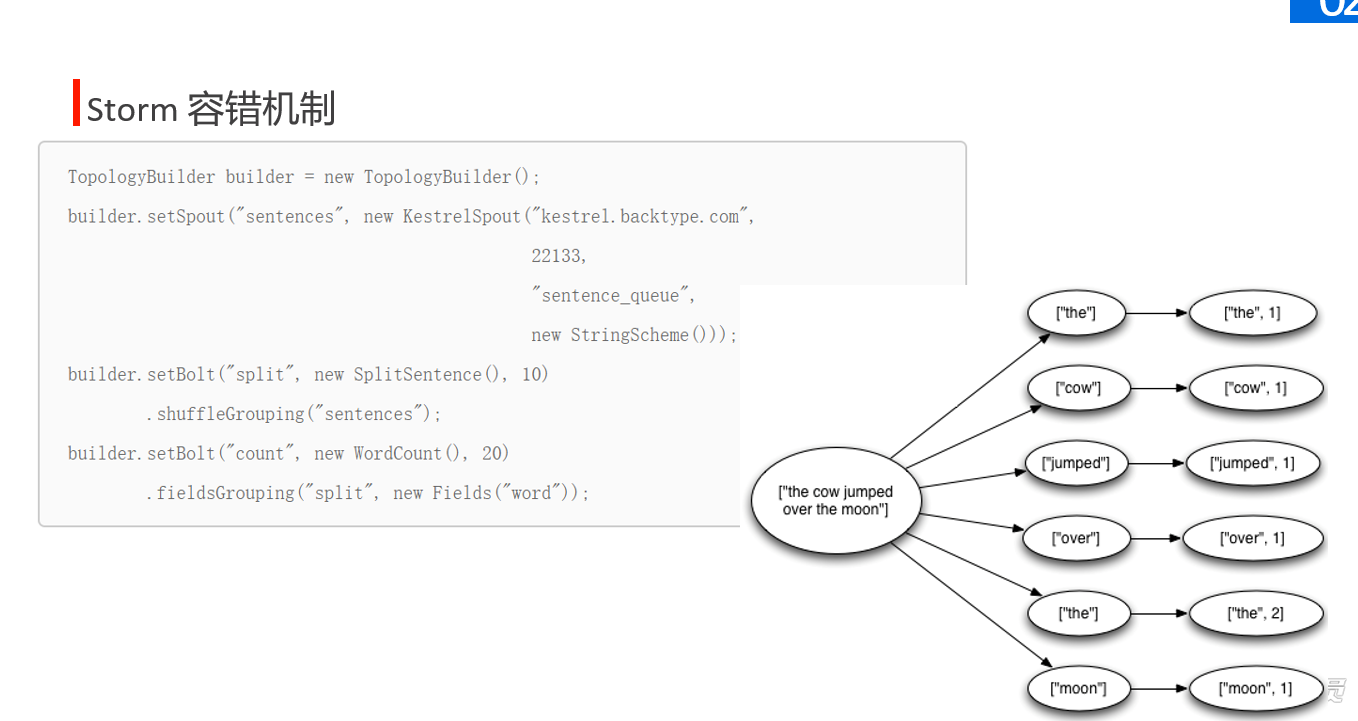
ack机制无法保证数据不被重复计算,但是可以保证数据至少被正确处理一次。(可能因错误,引发非错误数据重发被计算两次)
package com.sxt.storm.ack;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.util.Map;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichSpout;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
public class MySpout implements IRichSpout{
private static final long serialVersionUID = 1L;
int index = 0;
FileInputStream fis;
InputStreamReader isr;
BufferedReader br;
SpoutOutputCollector collector = null;
String str = null;
@Override
public void nextTuple() {
try {
if ((str = this.br.readLine()) != null) {
// 过滤动作
index++;
collector.emit(new Values(str), index);
// collector.emit(new Values(str));
}
} catch (Exception e) {
}
}
@Override
public void close() {
try {
br.close();
isr.close();
fis.close();
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
public void open(Map conf, TopologyContext context,
SpoutOutputCollector collector) {
try {
this.collector = collector;
this.fis = new FileInputStream("track.log");
this.isr = new InputStreamReader(fis, "UTF-8");
this.br = new BufferedReader(isr);
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("log"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
@Override
public void ack(Object msgId) {
System.err.println(" [" + Thread.currentThread().getName() + "] "+ " spout ack:"+msgId.toString());
}
@Override
public void activate() {
}
@Override
public void deactivate() {
}
@Override
public void fail(Object msgId) {
System.err.println(" [" + Thread.currentThread().getName() + "] "+ " spout fail:"+msgId.toString());
}
}
package com.sxt.storm.ack;
import java.util.Map;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
public class MyBolt implements IRichBolt {
private static final long serialVersionUID = 1L;
OutputCollector collector = null;
@Override
public void cleanup() {
}
int num = 0;
String valueString = null;
@Override
public void execute(Tuple input) {
try {
valueString = input.getStringByField("log") ;
if(valueString != null) {
num ++ ;
System.err.println(Thread.currentThread().getName()+" lines :"+num +" session_id:"+valueString.split(" ")[1]);
}
collector.emit(input, new Values(valueString));
// collector.emit(new Values(valueString));
collector.ack(input);
Thread.sleep(2000);
} catch (Exception e) {
collector.fail(input);
e.printStackTrace();
}
}
@Override
public void prepare(Map stormConf, TopologyContext context,
OutputCollector collector) {
this.collector = collector ;
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("session_id")) ;
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}
package com.sxt.storm.ack;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.StormSubmitter;
import backtype.storm.generated.AlreadyAliveException;
import backtype.storm.generated.InvalidTopologyException;
import backtype.storm.topology.TopologyBuilder;
public class Main {
/**
* @param args
*/
public static void main(String[] args) {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout", new MySpout(), 1);
builder.setBolt("bolt", new MyBolt(), 2).shuffleGrouping("spout");
// Map conf = new HashMap();
// conf.put(Config.TOPOLOGY_WORKERS, 4);
Config conf = new Config() ;
conf.setDebug(true);
conf.setMessageTimeoutSecs(conf, 100);
conf.setNumAckers(4);
if (args.length > 0) {
try {
StormSubmitter.submitTopology(args[0], conf, builder.createTopology());
} catch (AlreadyAliveException e) {
e.printStackTrace();
} catch (InvalidTopologyException e) {
e.printStackTrace();
}
}else {
LocalCluster localCluster = new LocalCluster();
localCluster.submitTopology("mytopology", conf, builder.createTopology());
}
}
}

单点故障, flume ha 单点瓶颈, load balance http://flume.apache.org/FlumeUserGuide.html#scribe-source 美团日志收集系统架构 https://tech.meituan.com/2013/12/09/meituan-flume-log-system-architecture-and-design.html 实例: 电话掉话率,(非正常挂断:没有声音了,不在服务区)
中国移动项目架构图:
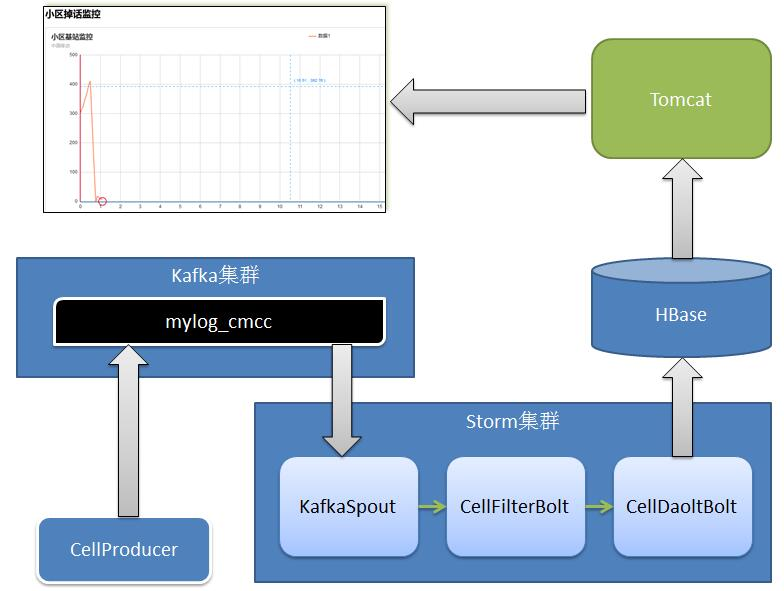
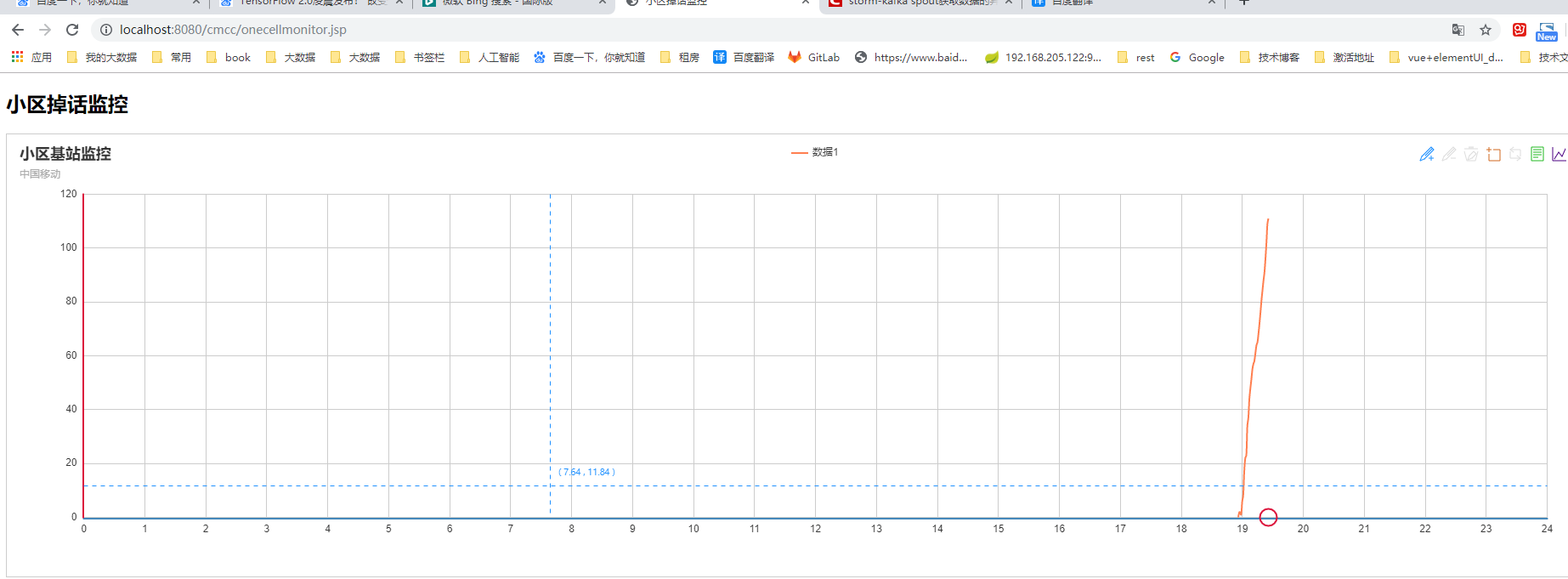
步骤: cmccstormjk02 1 producer 生产数据放到kafka的topic中。 2.strom spout 到kafka topic 中获取数据。 filterbolt 过滤, bolt 计算。 3.将计算结果:掉话数和通话数 每隔一段时间保存一次到hbase. cmcc02_hbase 4. 另外一个项目到hbase中获取指定时段的数据,展示到前端echart中。 准备: 配置 node,2,3,4 的kafka,启动 zk,启动kafka. 1.创建topic
./kafka-topics.sh --zookeeper node2:2181,node3:2181,node4:2181 --create --replication-factor 2 --partitions 3 --topic mylog_cmcc
2. comsumer 消费监控用于临时查看
./kafka-console-consumer.sh --zookeeper node2:2181,node3:2181,node4:2181 --from-beginning --topic mylog_cmcc
3 创建hbase 表
[root@node1 shells]# start-dfs.sh
[root@node1 shells]# ./start-yarn-ha.sh ## 自己写的ha yarn 启动脚本
[root@node1 ~]# cat shells/start-yarn-ha.sh
start-yarn.sh
ssh root@node3 "$HADOOP_HOME/sbin/yarn-daemon.sh start resourcemanager"
ssh root@node4 "$HADOOP_HOME/sbin/yarn-daemon.sh start resourcemanager"
[root@node1 shells]# start-hbase.sh
[root@node1 shells]# hbase shell
hbase(main):003:0> create 'cell_monitor_table','cf' ## ctrl+backspace 回退删除字符
## cmccstormjk02 项目 代码
/**
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package kafka.productor;
import java.util.Properties;
import java.util.Random;
import backtype.storm.utils.Utils;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
import tools.DateFmt;
/***
* 模拟发送数据到kafka中
*
* @author hadoop
*
*/
public class CellProducer extends Thread {
// bin/kafka-topics.sh --create --zookeeper localhost:2181
// --replication-factor 3 --partitions 5 --topic cmcccdr
private final kafka.javaapi.producer.Producer<Integer, String> producer;
private final String topic;
private final Properties props = new Properties();
public CellProducer(String topic) {
props.put("serializer.class", "kafka.serializer.StringEncoder");// 字符串消息
props.put("metadata.broker.list", KafkaProperties.broker_list);
producer = new kafka.javaapi.producer.Producer<Integer, String>(new ProducerConfig(props));
this.topic = topic;
}
/*
* public void run() { // order_id,order_amt,create_time,province_id Random
* random = new Random(); String[] cell_num = { "29448-37062",
* "29448-51331", "29448-51331","29448-51333", "29448-51343" }; String[]
* drop_num = { "0","1","2"};//掉话1(信号断断续续) 断话2(完全断开)
*
* // Producer.java // record_time, imei, cell,
* ph_num,call_num,drop_num,duration,drop_rate,net_type,erl // 2011-06-28
* 14:24:59.867,356966,29448-37062,0,0,0,0,0,G,0 // 2011-06-28
* 14:24:59.867,352024,29448-51331,0,0,0,0,0,G,0 // 2011-06-28
* 14:24:59.867,353736,29448-51331,0,0,0,0,0,G,0 // 2011-06-28
* 14:24:59.867,353736,29448-51333,0,0,0,0,0,G,0 // 2011-06-28
* 14:24:59.867,351545,29448-51333,0,0,0,0,0,G,0 // 2011-06-28
* 14:24:59.867,353736,29448-51343,1,0,0,8,0,G,0 int i =0 ; NumberFormat nf
* = new DecimalFormat("000000"); while(true) { i ++ ; // String messageStr
* = i+" "+cell_num[random.nextInt(cell_num.length)]+" "+DateFmt.
* getCountDate(null,
* DateFmt.date_long)+" "+drop_num[random.nextInt(drop_num.length)] ;
* String testStr = nf.format(random.nextInt(10)+1);
*
* String messageStr =
* i+" "+("29448-"+testStr)+" "+DateFmt.getCountDate(null,
* DateFmt.date_long)+" "+drop_num[random.nextInt(drop_num.length)] ;
*
* System.out.println("product:"+messageStr); producer.send(new
* KeyedMessage<Integer, String>(topic, messageStr)); Utils.sleep(1000) ; //
* if (i==500) { // break; // } }
*
* }
*/
public void run() {
Random random = new Random();
String[] cell_num = { "29448-37062", "29448-51331", "29448-51331", "29448-51333", "29448-51343" };
// 正常0; 掉话1(信号断断续续); 断话2(完全断开)
String[] drop_num = { "0", "1", "2" };
int i = 0;
while (true) {
i++;
String testStr = String.format("%06d", random.nextInt(10) + 1);
// messageStr: 2494 29448-000003 2016-01-05 10:25:17 1
//
String messageStr = i + " " + ("29448-" + testStr) + " " + DateFmt.getCountDate(null, DateFmt.date_long)
+ " " + drop_num[random.nextInt(drop_num.length)];
System.out.println("product:" + messageStr);
producer.send(new KeyedMessage<Integer, String>(topic, messageStr));
Utils.sleep(1000);
// if(i == 500) {
// break;
// }
}
}
public static void main(String[] args) {
// topic设置
CellProducer producerThread = new CellProducer(KafkaProperties.Cell_Topic);
// 启动线程生成数据
producerThread.start();
}
}
package bolt;
import java.util.Map;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.IBasicBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
import tools.DateFmt;
public class CellFilterBolt implements IBasicBolt {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public void execute(Tuple input, BasicOutputCollector collector) {
String logString = input.getString(0);
try {
if (input != null) {
String arr[] = logString.split("\t");
// messageStr格式:消息编号 小区编号 时间 状态
// 例: 2494 29448-000003 2016-01-05 10:25:17 1
// DateFmt.date_short是yyyy-MM-dd,把2016-01-05 10:25:17格式化2016-01-05
// 发出的数据格式: 时间, 小区编号, 掉话状态
collector.emit(new Values(DateFmt.getCountDate(arr[2], DateFmt.date_short), arr[1], arr[3]));
}
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("date", "cell_num", "drop_num"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
@Override
public void cleanup() {
// TODO Auto-generated method stub
}
@Override
public void prepare(Map map, TopologyContext arg1) {
// TODO Auto-generated method stub
}
}
package bolt;
import java.util.Calendar;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.IBasicBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
import cmcc.hbase.dao.HBaseDAO;
import cmcc.hbase.dao.impl.HBaseDAOImp;
import tools.DateFmt;
public class CellDaoltBolt implements IBasicBolt {
private static final long serialVersionUID = 1L;
HBaseDAO dao = null;
long beginTime = System.currentTimeMillis();
long endTime = 0;
// 通话总数
Map<String, Long> cellCountMap = new HashMap<String, Long>();
// 掉话数 >0
Map<String, Long> cellDropCountMap = new HashMap<String, Long>();
String todayStr = null;
@Override
public void execute(Tuple input, BasicOutputCollector collector) {
// input为2016-01-05,29448-000003,1
if (input != null) {
String dateStr = input.getString(0);
String cellNum = input.getString(1);
String dropNum = input.getString(2);
// 判断是否是当天,不是当天 就清除map 避免内存过大
// 基站数目 大概5-10万(北京市)
// http://bbs.c114.net/thread-793707-1-1.html
todayStr = DateFmt.getCountDate(null, DateFmt.date_short);
// 跨天的处理,大于当天的数据来了,就清空两个map
// 思考: 如果程序崩溃了,map清零了,如果不出问题,一直做同一个cellid的累加
// 这个逻辑不好,应该换成一个线程定期的清除map数据,而不是这里判断
if (todayStr != dateStr && todayStr.compareTo(dateStr) < 0) {
cellCountMap.clear();
cellDropCountMap.clear();
}
// 当前cellid的通话数统计
Long cellAll = cellCountMap.get(cellNum);
if (cellAll == null) {
cellAll = 0L;
}
cellCountMap.put(cellNum, ++cellAll);
// 掉话数统计,大于0就是掉话
Long cellDropAll = cellDropCountMap.get(cellNum);
int t = Integer.parseInt(dropNum);
if (t > 0) {
if (cellDropAll == null) {
cellDropAll = 0L;
}
cellDropCountMap.put(cellNum, ++cellDropAll);
}
// 1.定时写库.为了防止写库过于频繁 这里间隔一段时间写一次
// 2.也可以检测map里面数据size 写数据到 hbase
// 3.自己可以设计一些思路 ,当然 采用redis 也不错
// 4.采用tick定时存储也是一个思路
endTime = System.currentTimeMillis();
// flume+kafka 集成
// 当前掉话数
// 1.每小时掉话数目
// 2.每小时 通话数据
// 3.每小时 掉话率
// 4.昨天的历史轨迹
// 5.同比去年今天的轨迹(如果有数据)
// hbase 按列存储的数据()
// 10万
// rowkey cellnum+ day
if (endTime - beginTime >= 5000) {
// 5s 写一次库
if (cellCountMap.size() > 0 && cellDropCountMap.size() > 0) {
// x轴,相对于小时的偏移量,格式为 时:分,数值 数值是时间的偏移
String arr[] = this.getAxsi();
// 当前日期
String today = DateFmt.getCountDate(null, DateFmt.date_short);
// 当前分钟
String today_minute = DateFmt.getCountDate(null, DateFmt.date_minute);
// cellCountMap为通话数据的map
Set<String> keys = cellCountMap.keySet();
for (Iterator iterator = keys.iterator(); iterator.hasNext();) {
String key_cellnum = (String) iterator.next();
System.out.println("key_cellnum: " + key_cellnum + "***"
+ arr[0] + "---"
+ arr[1] + "---"
+ cellCountMap.get(key_cellnum) + "----"
+ cellDropCountMap.get(key_cellnum));
//写入HBase数据,样例: {time_title:"10:45",xAxis:10.759722222222223,call_num:140,call_drop_num:91}
dao.insert("cell_monitor_table",
key_cellnum + "_" + today,
"cf",
new String[] { today_minute },
new String[] { "{" + "time_title:"" + arr[0] + "",xAxis:" + arr[1] + ",call_num:"
+ cellCountMap.get(key_cellnum) + ",call_drop_num:" + cellDropCountMap.get(key_cellnum) + "}" }
);
}
}
// 需要重置初始时间
beginTime = System.currentTimeMillis();
}
}
}
@Override
public void prepare(Map stormConf, TopologyContext context) {
// TODO Auto-generated method stub
dao = new HBaseDAOImp();
Calendar calendar = Calendar.getInstance();
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// TODO Auto-generated method stub
}
@Override
public Map<String, Object> getComponentConfiguration() {
// TODO Auto-generated method stub
return null;
}
// 获取X坐标,就是当前时间的坐标,小时是单位
public String[] getAxsi() {
// 取当前时间
Calendar c = Calendar.getInstance();
int hour = c.get(Calendar.HOUR_OF_DAY);
int minute = c.get(Calendar.MINUTE);
int sec = c.get(Calendar.SECOND);
// 总秒数
int curSecNum = hour * 3600 + minute * 60 + sec;
// (12*3600+30*60+0)/3600=12.5
Double xValue = (double) curSecNum / 3600;
// 时:分,数值 数值是时间的偏移
String[] end = { hour + ":" + minute, xValue.toString() };
return end;
}
@Override
public void cleanup() {
}
}
package cmcc.constant;
public class Constants {
// public static final String HBASE_ZOOKEEPER_LIST = "node4:2181";
public static final String HBASE_ZOOKEEPER_LIST = "node2:2181,node3:2181,node4:2181";
public static final String KAFKA_ZOOKEEPER_LIST = "node2:2181,node3:2181,node4:2181";
public static final String BROKER_LIST = "node2:9092,node3:9092,node4:9092";
public static final String ZOOKEEPERS = "node2,node3,node4";
}
package topo;
import java.util.ArrayList;
import java.util.List;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.StormSubmitter;
import backtype.storm.generated.AlreadyAliveException;
import backtype.storm.generated.InvalidTopologyException;
import backtype.storm.spout.SchemeAsMultiScheme;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.tuple.Fields;
import bolt.CellDaoltBolt;
import bolt.CellFilterBolt;
import cmcc.constant.Constants;
import kafka.productor.KafkaProperties;
import storm.kafka.KafkaSpout;
import storm.kafka.SpoutConfig;
import storm.kafka.StringScheme;
import storm.kafka.ZkHosts;
public class KafkaOneCellMonintorTopology {
/**
* @param args
*/
public static void main(String[] args) {
TopologyBuilder builder = new TopologyBuilder();
ZkHosts zkHosts = new ZkHosts(Constants.KAFKA_ZOOKEEPER_LIST);
SpoutConfig spoutConfig = new SpoutConfig(zkHosts,
"mylog_cmcc",
"/MyKafka", // 偏移量offset的根目录
"MyTrack"); // 对应一个应用
List<String> zkServers = new ArrayList<String>();
System.out.println(zkHosts.brokerZkStr);
for (String host : zkHosts.brokerZkStr.split(",")) {
zkServers.add(host.split(":")[0]);
}
spoutConfig.zkServers = zkServers;
spoutConfig.zkPort = 2181;
// 是否从头开始消费
spoutConfig.forceFromStart = false;
spoutConfig.socketTimeoutMs = 60 * 1000;
// String
spoutConfig.scheme = new SchemeAsMultiScheme(new StringScheme());
builder.setSpout("spout", new KafkaSpout(spoutConfig), 3);
builder.setBolt("cellBolt", new CellFilterBolt(), 3).shuffleGrouping("spout");
builder.setBolt("CellDaoltBolt", new CellDaoltBolt(), 5)
.fieldsGrouping("cellBolt", new Fields("cell_num"));
Config conf = new Config();
conf.setDebug(false);
conf.setNumWorkers(5);
if (args.length > 0) {
try {
StormSubmitter.submitTopology(args[0], conf, builder.createTopology());
} catch (AlreadyAliveException e) {
e.printStackTrace();
} catch (InvalidTopologyException e) {
e.printStackTrace();
}
} else {
System.out.println("Local running");
LocalCluster localCluster = new LocalCluster();
localCluster.submitTopology("mytopology", conf, builder.createTopology());
}
}
}
package cmcc.hbase.dao.impl;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.KeyValue;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.ZooKeeperConnectionException;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HConnection;
import org.apache.hadoop.hbase.client.HConnectionManager;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.HTableInterface;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.filter.PrefixFilter;
import cmcc.constant.Constants;
import cmcc.hbase.dao.HBaseDAO;
public class HBaseDAOImp implements HBaseDAO {
HConnection hTablePool = null;
static Configuration conf = null;
public HBaseDAOImp() {
conf = new Configuration();
// ZooKeeper连接
String zk_list = Constants.HBASE_ZOOKEEPER_LIST;
conf.set("hbase.zookeeper.quorum", zk_list);
try {
hTablePool = HConnectionManager.createConnection(conf);
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public void save(Put put, String tableName) {
// TODO Auto-generated method stub
HTableInterface table = null;
try {
table = hTablePool.getTable(tableName);
table.put(put);
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
table.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
@Override
public void insert(String tableName, String rowKey, String family, String quailifer, String value) {
// TODO Auto-generated method stub
HTableInterface table = null;
try {
table = hTablePool.getTable(tableName);
Put put = new Put(rowKey.getBytes());
put.add(family.getBytes(), quailifer.getBytes(), value.getBytes());
table.put(put);
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
table.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
@Override
public void insert(String tableName, String rowKey, String family, String quailifer[], String value[]) {
HTableInterface table = null;
try {
table = hTablePool.getTable(tableName);
Put put = new Put(rowKey.getBytes());
// 批量添加
for (int i = 0; i < quailifer.length; i++) {
String col = quailifer[i];
String val = value[i];
put.add(family.getBytes(), col.getBytes(), val.getBytes());
}
table.put(put);
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
table.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
@Override
public void save(List<Put> Put, String tableName) {
// TODO Auto-generated method stub
HTableInterface table = null;
try {
table = hTablePool.getTable(tableName);
table.put(Put);
} catch (Exception e) {
// TODO: handle exception
} finally {
try {
table.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
@Override
public Result getOneRow(String tableName, String rowKey) {
// TODO Auto-generated method stub
HTableInterface table = null;
Result rsResult = null;
try {
table = hTablePool.getTable(tableName);
Get get = new Get(rowKey.getBytes());
rsResult = table.get(get);
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
table.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return rsResult;
}
@Override
public List<Result> getRows(String tableName, String rowKeyLike) {
// TODO Auto-generated method stub
HTableInterface table = null;
List<Result> list = null;
try {
table = hTablePool.getTable(tableName);
PrefixFilter filter = new PrefixFilter(rowKeyLike.getBytes());
Scan scan = new Scan();
scan.setFilter(filter);
ResultScanner scanner = table.getScanner(scan);
list = new ArrayList<Result>();
for (Result rs : scanner) {
list.add(rs);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
table.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return list;
}
@Override
public List<Result> getRows(String tableName, String rowKeyLike, String cols[]) {
// TODO Auto-generated method stub
HTableInterface table = null;
List<Result> list = null;
try {
table = hTablePool.getTable(tableName);
PrefixFilter filter = new PrefixFilter(rowKeyLike.getBytes());
Scan scan = new Scan();
for (int i = 0; i < cols.length; i++) {
scan.addColumn("cf".getBytes(), cols[i].getBytes());
}
scan.setFilter(filter);
ResultScanner scanner = table.getScanner(scan);
list = new ArrayList<Result>();
for (Result rs : scanner) {
list.add(rs);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
table.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return list;
}
@Override
public List<Result> getRows(String tableName, String startRow, String stopRow) {
HTableInterface table = null;
List<Result> list = null;
try {
table = hTablePool.getTable(tableName);
Scan scan = new Scan();
scan.setStartRow(startRow.getBytes());
scan.setStopRow(stopRow.getBytes());
ResultScanner scanner = table.getScanner(scan);
list = new ArrayList<Result>();
for (Result rsResult : scanner) {
list.add(rsResult);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
table.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return list;
}
@Override
public void deleteRecords(String tableName, String rowKeyLike) {
HTableInterface table = null;
try {
table = hTablePool.getTable(tableName);
PrefixFilter filter = new PrefixFilter(rowKeyLike.getBytes());
Scan scan = new Scan();
scan.setFilter(filter);
ResultScanner scanner = table.getScanner(scan);
List<Delete> list = new ArrayList<Delete>();
for (Result rs : scanner) {
Delete del = new Delete(rs.getRow());
list.add(del);
}
table.delete(list);
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
table.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
public void createTable(String tableName, String[] columnFamilys) {
try {
// admin 对象
HBaseAdmin admin = new HBaseAdmin(conf);
if (admin.tableExists(tableName)) {
System.err.println("此表,已存在!");
} else {
HTableDescriptor tableDesc = new HTableDescriptor(TableName.valueOf(tableName));
for (String columnFamily : columnFamilys) {
tableDesc.addFamily(new HColumnDescriptor(columnFamily));
}
admin.createTable(tableDesc);
System.err.println("建表成功!");
}
admin.close();// 关闭释放资源
} catch (MasterNotRunningException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (ZooKeeperConnectionException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
/**
* 删除一个表
*
* @param tableName
* 删除的表名
*/
public void deleteTable(String tableName) {
try {
HBaseAdmin admin = new HBaseAdmin(conf);
if (admin.tableExists(tableName)) {
admin.disableTable(tableName);// 禁用表
admin.deleteTable(tableName);// 删除表
System.err.println("删除表成功!");
} else {
System.err.println("删除的表不存在!");
}
admin.close();
} catch (MasterNotRunningException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (ZooKeeperConnectionException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
/**
* 查询表中所有行
*
* @param tablename
*/
public void scaner(String tablename) {
try {
HTable table = new HTable(conf, tablename);
Scan s = new Scan();
ResultScanner rs = table.getScanner(s);
for (Result r : rs) {
KeyValue[] kv = r.raw();
for (int i = 0; i < kv.length; i++) {
System.out.print(new String(kv[i].getRow()) + "");
System.out.print(new String(kv[i].getFamily()) + ":");
System.out.print(new String(kv[i].getQualifier()) + "");
System.out.print(kv[i].getTimestamp() + "");
System.out.println(new String(kv[i].getValue()));
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
HBaseDAO dao = new HBaseDAOImp();
// 创建表
// String tableName="test";
// String cfs[] = {"cf"};
// dao.createTable(tableName,cfs);
// 存入一条数据
// Put put = new Put("bjsxt".getBytes());
// put.add("cf".getBytes(), "name".getBytes(), "cai10".getBytes()) ;
// dao.save(put, "test") ;
// 插入多列数据
// Put put = new Put("bjsxt".getBytes());
// List<Put> list = new ArrayList<Put>();
// put.add("cf".getBytes(), "addr".getBytes(), "shanghai1".getBytes()) ;
// put.add("cf".getBytes(), "age".getBytes(), "30".getBytes()) ;
// put.add("cf".getBytes(), "tel".getBytes(), "13889891818".getBytes())
// ;
// list.add(put) ;
// dao.save(list, "test");
// 插入单行数据
// dao.insert("test", "testrow", "cf", "age", "35") ;
// dao.insert("test", "testrow", "cf", "cardid", "12312312335") ;
// dao.insert("test", "testrow", "cf", "tel", "13512312345") ;
List<Result> list = dao.getRows("test", "testrow", new String[] { "age" });
for (Result rs : list) {
for (Cell cell : rs.rawCells()) {
System.out.println("RowName:" + new String(CellUtil.cloneRow(cell)) + " ");
System.out.println("Timetamp:" + cell.getTimestamp() + " ");
System.out.println("column Family:" + new String(CellUtil.cloneFamily(cell)) + " ");
System.out.println("row Name:" + new String(CellUtil.cloneQualifier(cell)) + " ");
System.out.println("value:" + new String(CellUtil.cloneValue(cell)) + " ");
}
}
Result rs = dao.getOneRow("test", "testrow");
System.out.println(new String(rs.getValue("cf".getBytes(), "age".getBytes())));
}
}
cmcc02_hbase 页面获取hbase 数据
package cmcc.hbase.dao.impl;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.ZooKeeperConnectionException;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HConnection;
import org.apache.hadoop.hbase.client.HConnectionManager;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.HTableInterface;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.filter.BinaryComparator;
import org.apache.hadoop.hbase.filter.CompareFilter.CompareOp;
import org.apache.hadoop.hbase.filter.Filter;
import org.apache.hadoop.hbase.filter.PrefixFilter;
import org.apache.hadoop.hbase.filter.RowFilter;
import org.apache.hadoop.hbase.filter.SubstringComparator;
import org.apache.hadoop.hbase.util.Bytes;
import cmcc.hbase.dao.HBaseDAO;
public class HBaseDAOImp implements HBaseDAO {
HConnection hTablePool = null;
static Configuration conf = null;
public HBaseDAOImp() {
conf = new Configuration();
// 设置HBase的ZooKeeper
// String zk_list = "node4:2181";
String zk_list = "node2:2181,node3:2181,node4:2181";
conf.set("hbase.zookeeper.quorum", zk_list);
try {
hTablePool = HConnectionManager.createConnection(conf);
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public void save(Put put, String tableName) {
// TODO Auto-generated method stub
HTableInterface table = null;
try {
table = hTablePool.getTable(tableName);
table.put(put);
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
table.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
@Override
public void insert(String tableName, String rowKey, String family, String quailifer, String value) {
// TODO Auto-generated method stub
HTableInterface table = null;
try {
table = hTablePool.getTable(tableName);
Put put = new Put(rowKey.getBytes());
put.add(family.getBytes(), quailifer.getBytes(), value.getBytes());
table.put(put);
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
table.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
@Override
public void insert(String tableName, String rowKey, String family, String quailifer[], String value[]) {
HTableInterface table = null;
try {
table = hTablePool.getTable(tableName);
Put put = new Put(rowKey.getBytes());
// 批量添加
for (int i = 0; i < quailifer.length; i++) {
String col = quailifer[i];
String val = value[i];
put.add(family.getBytes(), col.getBytes(), val.getBytes());
}
table.put(put);
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
table.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
@Override
public void save(List<Put> Put, String tableName) {
// TODO Auto-generated method stub
HTableInterface table = null;
try {
table = hTablePool.getTable(tableName);
table.put(Put);
} catch (Exception e) {
// TODO: handle exception
} finally {
try {
table.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
@Override
public Result getOneRow(String tableName, String rowKey) {
// TODO Auto-generated method stub
HTableInterface table = null;
Result rsResult = null;
try {
table = hTablePool.getTable(tableName);
Get get = new Get(rowKey.getBytes());
rsResult = table.get(get);
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
table.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return rsResult;
}
@Override
public Result getOneRowAndMultiColumn(String tableName, String rowKey, String[] cols) {
// TODO Auto-generated method stub
HTableInterface table = null;
Result rsResult = null;
try {
table = hTablePool.getTable(tableName);
Get get = new Get(rowKey.getBytes());
for (int i = 0; i < cols.length; i++) {
get.addColumn("cf".getBytes(), cols[i].getBytes());
}
rsResult = table.get(get);
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
table.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return rsResult;
}
@Override
public List<Result> getRows(String tableName, String rowKeyLike) {
// TODO Auto-generated method stub
HTableInterface table = null;
List<Result> list = null;
try {
table = hTablePool.getTable(tableName);
PrefixFilter filter = new PrefixFilter(rowKeyLike.getBytes());
Scan scan = new Scan();
scan.setFilter(filter);
ResultScanner scanner = table.getScanner(scan);
list = new ArrayList<Result>();
for (Result rs : scanner) {
list.add(rs);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
table.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return list;
}
@Override
public List<Result> getRows(String tableName, String rowKeyLike, String cols[]) {
// TODO Auto-generated method stub
HTableInterface table = null;
List<Result> list = null;
try {
table = hTablePool.getTable(tableName);
PrefixFilter filter = new PrefixFilter(rowKeyLike.getBytes());
Scan scan = new Scan();
for (int i = 0; i < cols.length; i++) {
scan.addColumn("cf".getBytes(), cols[i].getBytes());
}
scan.setFilter(filter);
ResultScanner scanner = table.getScanner(scan);
list = new ArrayList<Result>();
for (Result rs : scanner) {
list.add(rs);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
table.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return list;
}
@Override
public List<Result> getRowsByOneKey(String tableName, String rowKeyLike, String cols[]) {
// TODO Auto-generated method stub
HTableInterface table = null;
List<Result> list = null;
try {
table = hTablePool.getTable(tableName);
PrefixFilter filter = new PrefixFilter(rowKeyLike.getBytes());
Scan scan = new Scan();
for (int i = 0; i < cols.length; i++) {
scan.addColumn("cf".getBytes(), cols[i].getBytes());
}
scan.setFilter(filter);
ResultScanner scanner = table.getScanner(scan);
list = new ArrayList<Result>();
for (Result rs : scanner) {
list.add(rs);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
table.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return list;
}
@Override
public List<Result> getRows(String tableName, String startRow, String stopRow) {
HTableInterface table = null;
List<Result> list = null;
try {
table = hTablePool.getTable(tableName);
Scan scan = new Scan();
scan.setStartRow(startRow.getBytes());
scan.setStopRow(stopRow.getBytes());
ResultScanner scanner = table.getScanner(scan);
list = new ArrayList<Result>();
for (Result rsResult : scanner) {
list.add(rsResult);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
table.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return list;
}
@Override
public void deleteRecords(String tableName, String rowKeyLike) {
HTableInterface table = null;
try {
table = hTablePool.getTable(tableName);
PrefixFilter filter = new PrefixFilter(rowKeyLike.getBytes());
Scan scan = new Scan();
scan.setFilter(filter);
ResultScanner scanner = table.getScanner(scan);
List<Delete> list = new ArrayList<Delete>();
for (Result rs : scanner) {
Delete del = new Delete(rs.getRow());
list.add(del);
}
table.delete(list);
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
table.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
public void createTable(String tableName, String[] columnFamilys) {
try {
// admin 对象
HBaseAdmin admin = new HBaseAdmin(conf);
if (admin.tableExists(tableName)) {
System.err.println("此表,已存在!");
} else {
HTableDescriptor tableDesc = new HTableDescriptor(TableName.valueOf(tableName));
for (String columnFamily : columnFamilys) {
tableDesc.addFamily(new HColumnDescriptor(columnFamily));
}
admin.createTable(tableDesc);
System.err.println("建表成功!");
}
admin.close();// 关闭释放资源
} catch (MasterNotRunningException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (ZooKeeperConnectionException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
/**
* 删除一个表
*
* @param tableName
* 删除的表名
*/
public void deleteTable(String tableName) {
try {
HBaseAdmin admin = new HBaseAdmin(conf);
if (admin.tableExists(tableName)) {
admin.disableTable(tableName);// 禁用表
admin.deleteTable(tableName);// 删除表
System.err.println("删除表成功!");
} else {
System.err.println("删除的表不存在!");
}
admin.close();
} catch (MasterNotRunningException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (ZooKeeperConnectionException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
/**
* 查询表中所有行
*
* @param tablename
*/
public void scaner(String tablename) {
try {
HTable table = new HTable(conf, tablename);
Scan s = new Scan();
// s.addColumn(family, qualifier)
// s.addColumn(family, qualifier)
ResultScanner rs = table.getScanner(s);
for (Result r : rs) {
for (Cell cell : r.rawCells()) {
System.out.println("RowName:" + new String(CellUtil.cloneRow(cell)) + " ");
System.out.println("Timetamp:" + cell.getTimestamp() + " ");
System.out.println("column Family:" + new String(CellUtil.cloneFamily(cell)) + " ");
System.out.println("row Name:" + new String(CellUtil.cloneQualifier(cell)) + " ");
System.out.println("value:" + new String(CellUtil.cloneValue(cell)) + " ");
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
public void scanerByColumn(String tablename) {
try {
HTable table = new HTable(conf, tablename);
Scan s = new Scan();
s.addColumn("cf".getBytes(), "201504052237".getBytes());
s.addColumn("cf".getBytes(), "201504052237".getBytes());
ResultScanner rs = table.getScanner(s);
for (Result r : rs) {
for (Cell cell : r.rawCells()) {
System.out.println("RowName:" + new String(CellUtil.cloneRow(cell)) + " ");
System.out.println("Timetamp:" + cell.getTimestamp() + " ");
System.out.println("column Family:" + new String(CellUtil.cloneFamily(cell)) + " ");
System.out.println("row Name:" + new String(CellUtil.cloneQualifier(cell)) + " ");
System.out.println("value:" + new String(CellUtil.cloneValue(cell)) + " ");
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
HBaseDAO dao = new HBaseDAOImp();
// 创建表
// String tableName="test";
// String cfs[] = {"cf"};
// dao.createTable(tableName,cfs);
// 存入一条数据
// Put put = new Put("bjsxt".getBytes());
// put.add("cf".getBytes(), "name".getBytes(), "cai10".getBytes()) ;
// dao.save(put, "test") ;
// 插入多列数据
// Put put = new Put("bjsxt".getBytes());
// List<Put> list = new ArrayList<Put>();
// put.add("cf".getBytes(), "addr".getBytes(), "shanghai1".getBytes()) ;
// put.add("cf".getBytes(), "age".getBytes(), "30".getBytes()) ;
// put.add("cf".getBytes(), "tel".getBytes(), "13889891818".getBytes())
// ;
// list.add(put) ;
// dao.save(list, "test");
// 插入单行数据
// dao.insert("test", "testrow", "cf", "age", "35") ;
// dao.insert("test", "testrow", "cf", "cardid", "12312312335") ;
// dao.insert("test", "testrow", "cf", "tel", "13512312345") ;
// List<Result> list = dao.getRows("test", "testrow",new
// String[]{"age"}) ;
// for(Result rs : list)
// {
// for(Cell cell:rs.rawCells()){
// System.out.println("RowName:"+new String(CellUtil.cloneRow(cell))+"
// ");
// System.out.println("Timetamp:"+cell.getTimestamp()+" ");
// System.out.println("column Family:"+new
// String(CellUtil.cloneFamily(cell))+" ");
// System.out.println("row Name:"+new
// String(CellUtil.cloneQualifier(cell))+" ");
// System.out.println("value:"+new String(CellUtil.cloneValue(cell))+"
// ");
// }
// }
// Result rs = dao.getOneRow("test", "testrow");
// System.out.println(new String(rs.getValue("cf".getBytes(),
// "age".getBytes())));
// Result rs = dao.getOneRowAndMultiColumn("cell_monitor_table",
// "29448-513332015-04-05", new
// String[]{"201504052236","201504052237"});
// for(Cell cell:rs.rawCells()){
// System.out.println("RowName:"+new String(CellUtil.cloneRow(cell))+"
// ");
// System.out.println("Timetamp:"+cell.getTimestamp()+" ");
// System.out.println("column Family:"+new
// String(CellUtil.cloneFamily(cell))+" ");
// System.out.println("row Name:"+new
// String(CellUtil.cloneQualifier(cell))+" ");
// System.out.println("value:"+new String(CellUtil.cloneValue(cell))+"
// ");
// }
dao.deleteTable("cell_monitor_table");
// 创建表
String tableName = "cell_monitor_table";
String cfs[] = { "cf" };
dao.createTable(tableName, cfs);
}
public static void testRowFilter(String tableName) {
try {
HTable table = new HTable(conf, tableName);
Scan scan = new Scan();
scan.addColumn(Bytes.toBytes("column1"), Bytes.toBytes("qqqq"));
Filter filter1 = new RowFilter(CompareOp.LESS_OR_EQUAL, new BinaryComparator(Bytes.toBytes("laoxia157")));
scan.setFilter(filter1);
ResultScanner scanner1 = table.getScanner(scan);
for (Result res : scanner1) {
System.out.println(res);
}
scanner1.close();
//
// Filter filter2 = new RowFilter(CompareFilter.CompareOp.EQUAL,new
// RegexStringComparator("laoxia4\d{2}"));
// scan.setFilter(filter2);
// ResultScanner scanner2 = table.getScanner(scan);
// for (Result res : scanner2) {
// System.out.println(res);
// }
// scanner2.close();
Filter filter3 = new RowFilter(CompareOp.EQUAL, new SubstringComparator("laoxia407"));
scan.setFilter(filter3);
ResultScanner scanner3 = table.getScanner(scan);
for (Result res : scanner3) {
System.out.println(res);
}
scanner3.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
目录树位置
SpoutConfig spoutConfig = new SpoutConfig(zkHosts, "mylog_cmcc", "/MyKafka", // 偏移量offset的根目录 "MyTrack"); // 对应一个应用 ack 是信息完整性保护线程。




/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package com.sxt.storm.drpc;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.LocalDRPC;
import backtype.storm.StormSubmitter;
import backtype.storm.drpc.LinearDRPCTopologyBuilder;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
/**
* This topology is a basic example of doing distributed RPC on top of Storm. It
* implements a function that appends a "!" to any string you send the DRPC
* function.
* <p/>
* See https://github.com/nathanmarz/storm/wiki/Distributed-RPC for more
* information on doing distributed RPC on top of Storm.
*/
public class BasicDRPCTopology {
public static class ExclaimBolt extends BaseBasicBolt {
@Override
public void execute(Tuple tuple, BasicOutputCollector collector) {
String input = tuple.getString(1);
collector.emit(new Values(tuple.getValue(0), input + "!"));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("id", "result"));
}
}
public static void main(String[] args) throws Exception {
LinearDRPCTopologyBuilder builder = new LinearDRPCTopologyBuilder("exclamation");
builder.addBolt(new ExclaimBolt(), 3);
Config conf = new Config();
if (args == null || args.length == 0) {
LocalDRPC drpc = new LocalDRPC();
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("drpc-demo", conf, builder.createLocalTopology(drpc));
for (String word : new String[] { "hello", "goodbye" }) {
System.err.println("Result for "" + word + "": " + drpc.execute("exclamation", word));
}
cluster.shutdown();
drpc.shutdown();
} else {
conf.setNumWorkers(3);
StormSubmitter.submitTopologyWithProgressBar(args[0], conf, builder.createRemoteTopology());
}
}
}
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package com.sxt.storm.drpc;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.LocalDRPC;
import backtype.storm.drpc.DRPCSpout;
import backtype.storm.drpc.ReturnResults;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
public class ManualDRPC {
public static class ExclamationBolt extends BaseBasicBolt {
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("result", "return-info"));
}
@Override
public void execute(Tuple tuple, BasicOutputCollector collector) {
String arg = tuple.getString(0);
Object retInfo = tuple.getValue(1);
collector.emit(new Values(arg + "!!!", retInfo));
}
}
public static void main(String[] args) {
TopologyBuilder builder = new TopologyBuilder();
LocalDRPC drpc = new LocalDRPC();
DRPCSpout spout = new DRPCSpout("exclamation", drpc);
builder.setSpout("drpc", spout);
builder.setBolt("exclaim", new ExclamationBolt(), 3).shuffleGrouping("drpc");
builder.setBolt("return", new ReturnResults(), 3).shuffleGrouping("exclaim");
LocalCluster cluster = new LocalCluster();
Config conf = new Config();
cluster.submitTopology("exclaim", conf, builder.createTopology());
System.err.println(drpc.execute("exclamation", "aaa"));
System.err.println(drpc.execute("exclamation", "bbb"));
}
}

配置和演示drpc
[root@node2 conf]# vi storm.yaml
drpc.servers:
- "node2"
## scp 到node3,4
启动strom和drpc
[root@node2 conf]# cd /opt/sxt/apache-storm-0.10.0
[root@node2 apache-storm-0.10.0]# ./bin/storm nimbus >> ./logs/nimbus.out 2>&1 &
./bin/storm ui >> ./logs/ui.out 2>&1 &
[root@node2 apache-storm-0.10.0]# ./bin/storm drpc >> ./logs/drpc.out 2>&1 &"
"supervisor
#node3,4
./bin/storm supervisor >> ./logs/supervisor.out 2>&1 &"
"supervisor
## 将BasicDRPCTopology.java 打为jar包
## 上传
[root@node2 apache-storm-0.10.0]# ./bin/storm jar ~/software/DRPCDemo.jar com.sxt.storm.drpc.BasicDRPCTopology drpc
## 在eclipse中使用客户端调用
package com.sxt.storm.drpc;
import org.apache.thrift7.TException;
import backtype.storm.generated.DRPCExecutionException;
import backtype.storm.utils.DRPCClient;
public class MyDRPCclient {
/**
* @param args
*/
public static void main(String[] args) {
DRPCClient client = new DRPCClient("node2", 3772);
try {
String result = client.execute("exclamation", "11,22");
System.out.println(result);
} catch (TException e) {
e.printStackTrace();
} catch (DRPCExecutionException e) {
e.printStackTrace();
}
}
}
## 上表代码输出 11!!!,22!!!

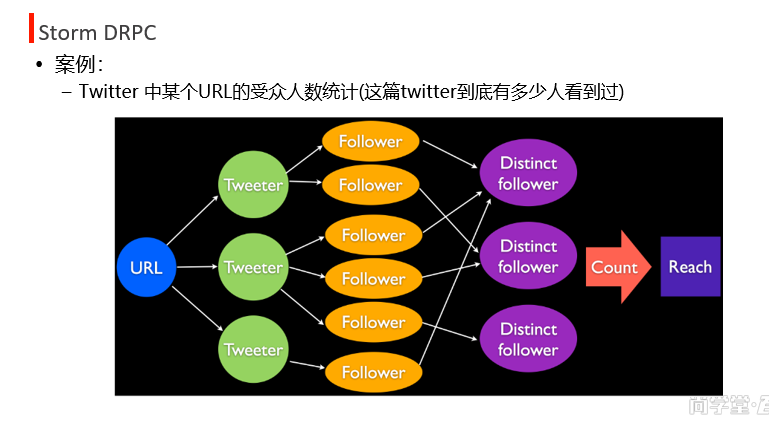
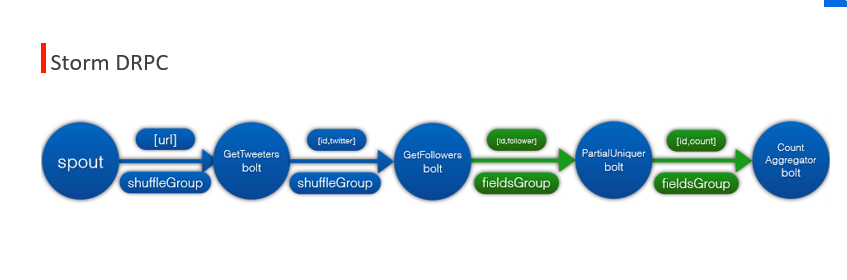
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package com.sxt.storm.drpc;
import java.util.Arrays;
import java.util.HashMap;
import java.util.HashSet;
import java.util.List;
import java.util.Map;
import java.util.Set;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.LocalDRPC;
import backtype.storm.StormSubmitter;
import backtype.storm.coordination.BatchOutputCollector;
import backtype.storm.drpc.LinearDRPCTopologyBuilder;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.topology.base.BaseBatchBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
/**
* This is a good example of doing complex Distributed RPC on top of Storm. This
* program creates a topology that can compute the reach for any URL on Twitter
* in realtime by parallelizing the whole computation.
* <p/>
* Reach is the number of unique people exposed to a URL on Twitter. To compute
* reach, you have to get all the people who tweeted the URL, get all the
* followers of all those people, unique that set of followers, and then count
* the unique set. It's an intense computation that can involve thousands of
* database calls and tens of millions of follower records.
* <p/>
* This Storm topology does every piece of that computation in parallel, turning
* what would be a computation that takes minutes on a single machine into one
* that takes just a couple seconds.
* <p/>
* For the purposes of demonstration, this topology replaces the use of actual
* DBs with in-memory hashmaps.
* <p/>
* See https://github.com/nathanmarz/storm/wiki/Distributed-RPC for more
* information on Distributed RPC.
*/
public class ReachTopology {
public static Map<String, List<String>> TWEETERS_DB = new HashMap<String, List<String>>() {
{
put("foo.com/blog/1", Arrays.asList("sally", "bob", "tim", "george", "nathan"));
put("engineering.twitter.com/blog/5", Arrays.asList("adam", "david", "sally", "nathan"));
put("tech.backtype.com/blog/123", Arrays.asList("tim", "mike", "john"));
}
};
public static Map<String, List<String>> FOLLOWERS_DB = new HashMap<String, List<String>>() {
{
put("sally", Arrays.asList("bob", "tim", "alice", "adam", "jim", "chris", "jai"));
put("bob", Arrays.asList("sally", "nathan", "jim", "mary", "david", "vivian"));
put("tim", Arrays.asList("alex"));
put("nathan", Arrays.asList("sally", "bob", "adam", "harry", "chris", "vivian", "emily", "jordan"));
put("adam", Arrays.asList("david", "carissa"));
put("mike", Arrays.asList("john", "bob"));
put("john", Arrays.asList("alice", "nathan", "jim", "mike", "bob"));
}
};
public static class GetTweeters extends BaseBasicBolt {
@Override
public void execute(Tuple tuple, BasicOutputCollector collector) {
Object id = tuple.getValue(0);
String url = tuple.getString(1);
List<String> tweeters = TWEETERS_DB.get(url);
if (tweeters != null) {
for (String tweeter : tweeters) {
collector.emit(new Values(id, tweeter));
}
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("id", "tweeter"));
}
}
public static class GetFollowers extends BaseBasicBolt {
@Override
public void execute(Tuple tuple, BasicOutputCollector collector) {
Object id = tuple.getValue(0);
String tweeter = tuple.getString(1);
List<String> followers = FOLLOWERS_DB.get(tweeter);
if (followers != null) {
for (String follower : followers) {
collector.emit(new Values(id, follower));
}
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("id", "follower"));
}
}
public static class PartialUniquer extends BaseBatchBolt {
BatchOutputCollector _collector;
Object _id;
Set<String> _followers = new HashSet<String>();
@Override
public void prepare(Map conf, TopologyContext context, BatchOutputCollector collector, Object id) {
_collector = collector;
_id = id;
}
@Override
public void execute(Tuple tuple) {
_followers.add(tuple.getString(1));
}
@Override
public void finishBatch() {
_collector.emit(new Values(_id, _followers.size()));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("id", "partial-count"));
}
}
public static class CountAggregator extends BaseBatchBolt {
BatchOutputCollector _collector;
Object _id;
int _count = 0;
@Override
public void prepare(Map conf, TopologyContext context, BatchOutputCollector collector, Object id) {
_collector = collector;
_id = id;
}
@Override
public void execute(Tuple tuple) {
_count += tuple.getInteger(1);
}
@Override
public void finishBatch() {
_collector.emit(new Values(_id, _count));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("id", "reach"));
}
}
public static LinearDRPCTopologyBuilder construct() {
LinearDRPCTopologyBuilder builder = new LinearDRPCTopologyBuilder("reach");
builder.addBolt(new GetTweeters(), 4);
builder.addBolt(new GetFollowers(), 12).shuffleGrouping();
// builder.addBolt(new PartialUniquer(), 6).fieldsGrouping(new Fields("id", "follower"));
builder.addBolt(new PartialUniquer(), 6).fieldsGrouping(new Fields("id"));
builder.addBolt(new CountAggregator(), 3).fieldsGrouping(new Fields("id"));
return builder;
}
public static void main(String[] args) throws Exception {
LinearDRPCTopologyBuilder builder = construct();
Config conf = new Config();
if (args == null || args.length == 0) {
conf.setMaxTaskParallelism(3);
LocalDRPC drpc = new LocalDRPC();
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("reach-drpc", conf, builder.createLocalTopology(drpc));
String[] urlsToTry = new String[] { "foo.com/blog/1", "engineering.twitter.com/blog/5", "notaurl.com" };
for (String url : urlsToTry) {
System.err.println("Reach of " + url + ": " + drpc.execute("reach", url));
}
cluster.shutdown();
drpc.shutdown();
} else {
conf.setNumWorkers(6);
StormSubmitter.submitTopologyWithProgressBar(args[0], conf, builder.createRemoteTopology());
}
}
}
kafka comsumer 两个消费者可以消费同一条数据。与生活中的吃包子不一样。(相当于查看数据),各个分区之间的数据不一定有序,分区内的数据有序

./kafka-topics.sh --zookeeper node2:2181,node3:2181,node4:2181 --create --replication-factor 2 --partitions 3 --topic test ./kafka-topics.sh --zookeeper node2:2181,node3:2181,node4:2181 --describe --topic test ./kafka-console-producer.sh --broker-list node2:9092,node3:9092,node4:9092 --topic test ./kafka-console-consumer.sh --zookeeper node2:2181,node3:2181,node4:2181 --from-beginning --topic test
storm kafka 集成文档 https://github.com/apache/storm/tree/master/external/storm-kafka
https://www.tutorialspoint.com/apache_kafka/apache_kafka_integration_storm.htm
flume + kafka
http://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html#kafka-sink
[root@node2 conf]# cat flume-env.sh | grep export export JAVA_HOME=/usr/java/jdk1.8.0_221 [root@node2 conf]# cat fk.conf a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = avro a1.sources.r1.bind = node2 a1.sources.r1.port = 41414 # Describe the sink a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink a1.sinks.k1.topic = testflume a1.sinks.k1.brokerList = node2:9092,node3:9092,node3:9092 a1.sinks.k1.requiredAcks = 1 a1.sinks.k1.batchSize = 20 # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000000 a1.channels.c1.transactionCapacity = 10000 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 [root@node2 conf]# pwd /opt/sxt/apache-flume-1.6.0-bin/conf
## 启动zk
## 启动kafka
## 启动 flume
[root@node2 apache-flume-1.6.0-bin]# bin/flume-ng agent -n a1 -c conf -f conf/fk.conf -Dflume.root.logger=DEBUG,console
## 消费 kafka topic testflume
[root@node3 bin]# ./kafka-console-consumer.sh --zookeeper node2:2181,node3:2181,node4:2181 --from-beginning --topic testflume
## 运行程序
package com.sxt.flume;
import org.apache.flume.Event;
import org.apache.flume.EventDeliveryException;
import org.apache.flume.api.RpcClient;
import org.apache.flume.api.RpcClientFactory;
import org.apache.flume.event.EventBuilder;
import java.nio.charset.Charset;
/**
* Flume官网案例
* http://flume.apache.org/FlumeDeveloperGuide.html
* @author root
*/
public class RpcClientDemo {
public static void main(String[] args) {
MyRpcClientFacade client = new MyRpcClientFacade();
// Initialize client with the remote Flume agent's host and port
client.init("node2", 41414);
// Send 10 events to the remote Flume agent. That agent should be
// configured to listen with an AvroSource.
for (int i = 10; i < 20; i++) {
String sampleData = "Hello Flume!ERROR" + i;
client.sendDataToFlume(sampleData);
System.out.println("发送数据:" + sampleData);
}
client.cleanUp();
}
}
class MyRpcClientFacade {
private RpcClient client;
private String hostname;
private int port;
public void init(String hostname, int port) {
// Setup the RPC connection
this.hostname = hostname;
this.port = port;
this.client = RpcClientFactory.getDefaultInstance(hostname, port);
// Use the following method to create a thrift client (instead of the
// above line):
// this.client = RpcClientFactory.getThriftInstance(hostname, port);
}
public void sendDataToFlume(String data) {
// Create a Flume Event object that encapsulates the sample data
Event event = EventBuilder.withBody(data, Charset.forName("UTF-8"));
// Send the event
try {
client.append(event);
} catch (EventDeliveryException e) {
// clean up and recreate the client
client.close();
client = null;
client = RpcClientFactory.getDefaultInstance(hostname, port);
// Use the following method to create a thrift client (instead of
// the above line):
// this.client = RpcClientFactory.getThriftInstance(hostname, port);
}
}
public void cleanUp() {
// Close the RPC connection
client.close();
}
}
## kafka 消费如下内容
[root@node3 bin]# ./kafka-console-consumer.sh --zookeeper node2:2181,node3:2181,node4:2181 --from-beginning --topic testflume
Hello Flume!ERROR10
Hello Flume!ERROR11
Hello Flume!ERROR12
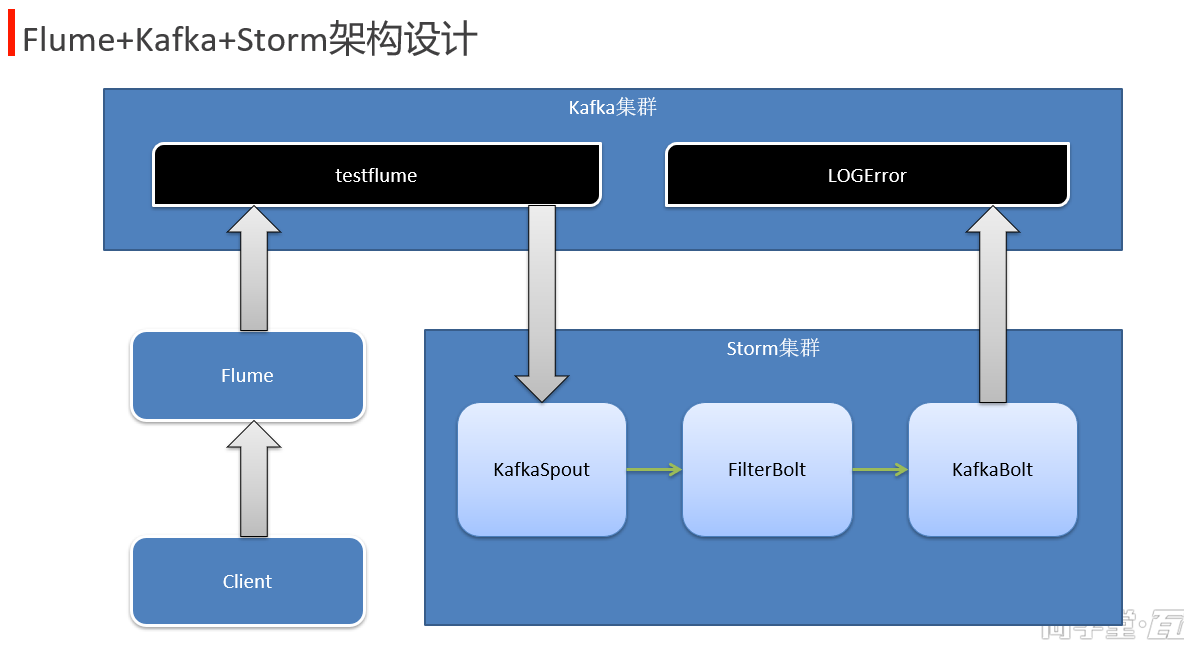
[root@node3 bin]# ./kafka-topics.sh --zookeeper node2:2181,node3:2181,node4:2181 --create --replication-factor 2 --partitions 1 --topic LogError
Created topic "LogError".
## 为kafkaBolt做准备
[root@node3 bin]# ./kafka-topics.sh --zookeeper node2:2181,node3:2181,node4:2181 --list
LogError
[root@node3 bin]# ./kafka-console-consumer.sh --zookeeper node2:2181,node3:2181,node4:2181 --from-beginning --topic testflume
[root@node4 bin]# ./kafka-console-consumer.sh --zookeeper node2:2181,node3:2181,node4:2181 --from-beginning --topic LogError
## 首先运行
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package com.sxt.storm.logfileter;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.Properties;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.spout.SchemeAsMultiScheme;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
import storm.kafka.KafkaSpout;
import storm.kafka.SpoutConfig;
import storm.kafka.StringScheme;
import storm.kafka.ZkHosts;
import storm.kafka.bolt.KafkaBolt;
import storm.kafka.bolt.mapper.FieldNameBasedTupleToKafkaMapper;
import storm.kafka.bolt.selector.DefaultTopicSelector;
/**
* This topology demonstrates Storm's stream groupings and multilang
* capabilities.
*/
public class LogFilterTopology {
public static class FilterBolt extends BaseBasicBolt {
@Override
public void execute(Tuple tuple, BasicOutputCollector collector) {
String line = tuple.getString(0);
System.err.println("Accept: " + line);
// 包含ERROR的行留下
if (line.contains("ERROR")) {
System.err.println("Filter: " + line);
collector.emit(new Values(line));
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// 定义message提供给后面FieldNameBasedTupleToKafkaMapper使用
declarer.declare(new Fields("message"));
}
}
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
// https://github.com/apache/storm/tree/master/external/storm-kafka
// config kafka spout,话题
String topic = "testflume";
ZkHosts zkHosts = new ZkHosts("node2:2181,node3:2181,node4:2181");
// /MyKafka,偏移量offset的根目录,记录队列取到了哪里
SpoutConfig spoutConfig = new SpoutConfig(zkHosts, topic, "/MyKafka", "MyTrack");// 对应一个应用
List<String> zkServers = new ArrayList<String>();
System.out.println(zkHosts.brokerZkStr);
for (String host : zkHosts.brokerZkStr.split(",")) {
zkServers.add(host.split(":")[0]);
}
spoutConfig.zkServers = zkServers;
spoutConfig.zkPort = 2181;
// 是否从头开始消费
spoutConfig.forceFromStart = true;
spoutConfig.socketTimeoutMs = 60 * 1000;
// StringScheme将字节流转解码成某种编码的字符串
spoutConfig.scheme = new SchemeAsMultiScheme(new StringScheme());
KafkaSpout kafkaSpout = new KafkaSpout(spoutConfig);
// set kafka spout
builder.setSpout("kafka_spout", kafkaSpout, 3);
// set bolt
builder.setBolt("filter", new FilterBolt(), 8).shuffleGrouping("kafka_spout");
// 数据写出
// set kafka bolt
// withTopicSelector使用缺省的选择器指定写入的topic: LogError
// withTupleToKafkaMapper tuple==>kafka的key和message
KafkaBolt kafka_bolt = new KafkaBolt().withTopicSelector(new DefaultTopicSelector("LogError"))
.withTupleToKafkaMapper(new FieldNameBasedTupleToKafkaMapper());
builder.setBolt("kafka_bolt", kafka_bolt, 2).shuffleGrouping("filter");
Config conf = new Config();
// set producer properties.
Properties props = new Properties();
props.put("metadata.broker.list", "node2:9092,node3:9092,node4:9092");
/**
* Kafka生产者ACK机制 0 : 生产者不等待Kafka broker完成确认,继续发送下一条数据 1 :
* 生产者等待消息在leader接收成功确认之后,继续发送下一条数据 -1 :
* 生产者等待消息在follower副本接收到数据确认之后,继续发送下一条数据
*/
props.put("request.required.acks", "1");
props.put("serializer.class", "kafka.serializer.StringEncoder");
conf.put("kafka.broker.properties", props);
conf.put(Config.STORM_ZOOKEEPER_SERVERS, Arrays.asList(new String[] { "node2", "node3", "node4" }));
// 本地方式运行
LocalCluster localCluster = new LocalCluster();
localCluster.submitTopology("mytopology", conf, builder.createTopology());
}
}
## 再运行
package com.sxt.flume;
import org.apache.flume.Event;
import org.apache.flume.EventDeliveryException;
import org.apache.flume.api.RpcClient;
import org.apache.flume.api.RpcClientFactory;
import org.apache.flume.event.EventBuilder;
import java.nio.charset.Charset;
/**
* Flume官网案例
* http://flume.apache.org/FlumeDeveloperGuide.html
* @author root
*/
public class RpcClientDemo {
public static void main(String[] args) {
MyRpcClientFacade client = new MyRpcClientFacade();
// Initialize client with the remote Flume agent's host and port
client.init("node2", 41414);
// Send 10 events to the remote Flume agent. That agent should be
// configured to listen with an AvroSource.
for (int i = 10; i < 20; i++) {
// String sampleData = "Hello Flume!wawa" + i;
String sampleData = "Hello Flume!ERROR" + i;
client.sendDataToFlume(sampleData);
System.out.println("发送数据:" + sampleData);
}
client.cleanUp();
}
}
class MyRpcClientFacade {
private RpcClient client;
private String hostname;
private int port;
public void init(String hostname, int port) {
// Setup the RPC connection
this.hostname = hostname;
this.port = port;
this.client = RpcClientFactory.getDefaultInstance(hostname, port);
// Use the following method to create a thrift client (instead of the
// above line):
// this.client = RpcClientFactory.getThriftInstance(hostname, port);
}
public void sendDataToFlume(String data) {
// Create a Flume Event object that encapsulates the sample data
Event event = EventBuilder.withBody(data, Charset.forName("UTF-8"));
// Send the event
try {
client.append(event);
} catch (EventDeliveryException e) {
// clean up and recreate the client
client.close();
client = null;
client = RpcClientFactory.getDefaultInstance(hostname, port);
// Use the following method to create a thrift client (instead of
// the above line):
// this.client = RpcClientFactory.getThriftInstance(hostname, port);
}
}
public void cleanUp() {
// Close the RPC connection
client.close();
}
}
## 查看kafka监控
Storm – 事务 http://storm.apache.org/releases/1.2.3/Transactional-topologies.html http://storm.apache.org/releases/0.9.6/Transactional-topologies.html 事务性拓扑(Transactional Topologies) 保证消息(tuple)被且仅被处理一次
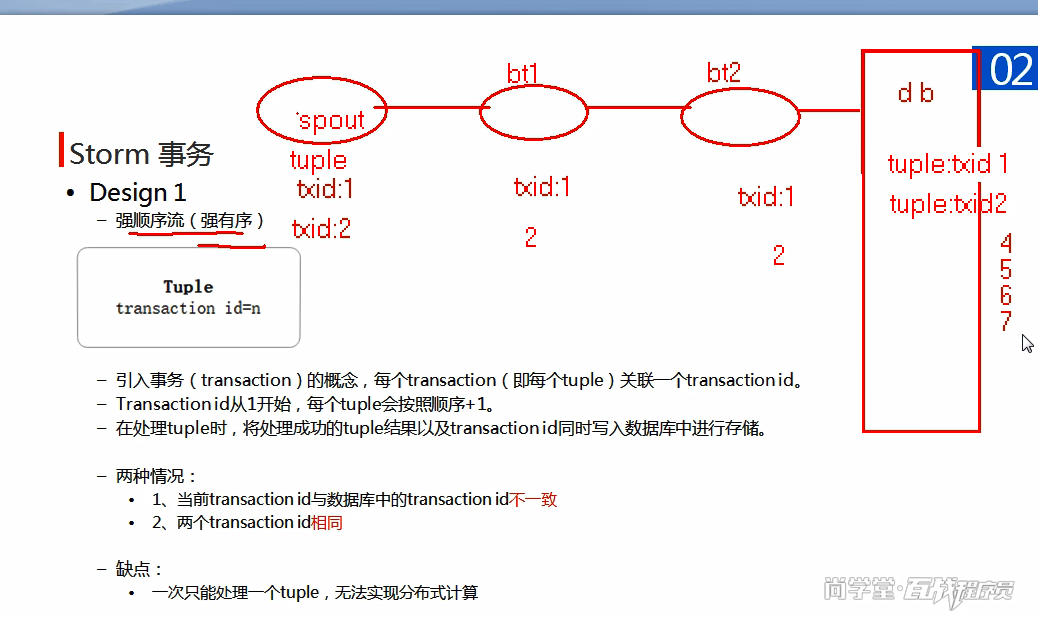
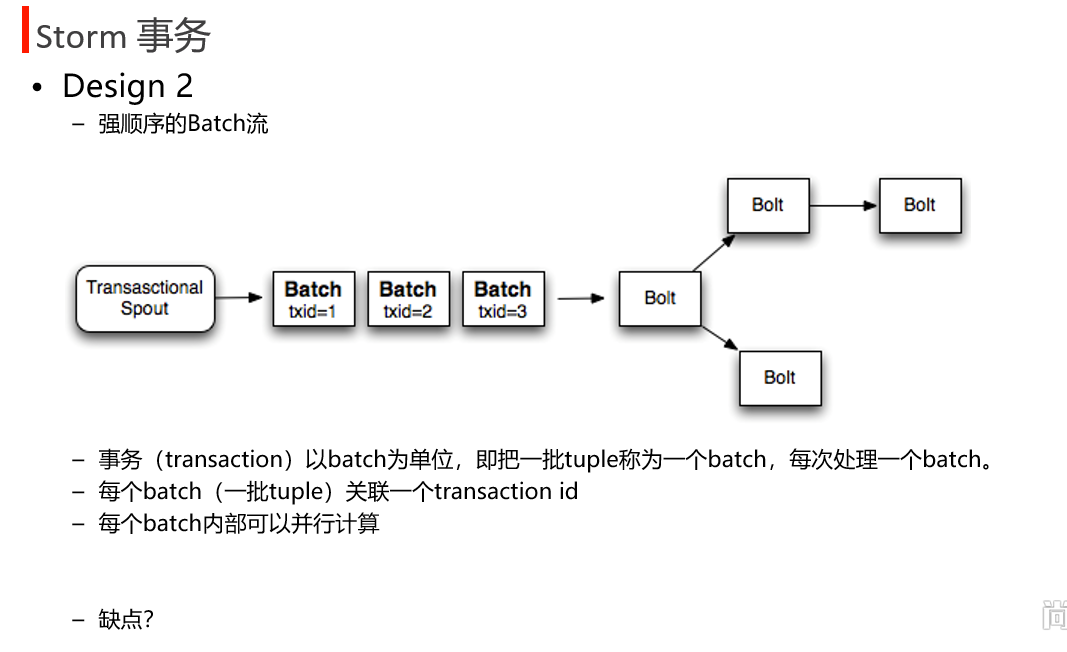

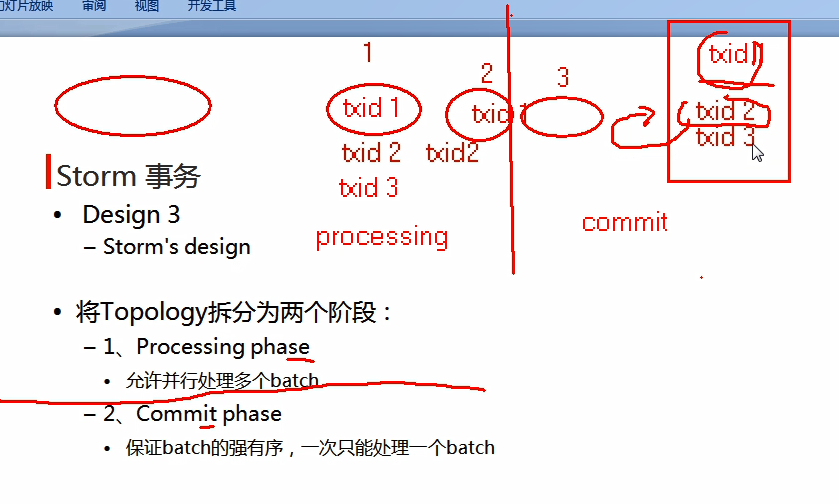


例子 package com.sxt.storm.transactional; import backtype.storm.Config; import backtype.storm.LocalCluster; import backtype.storm.StormSubmitter; import backtype.storm.generated.AlreadyAliveException; import backtype.storm.generated.InvalidTopologyException; import backtype.storm.transactional.TransactionalTopologyBuilder; public class MyTopo { /** * @param args */ public static void main(String[] args) { TransactionalTopologyBuilder builder = new TransactionalTopologyBuilder("ttbId","spoutid",new MyTxSpout(),1); builder.setBolt("bolt1", new MyTransactionBolt(),3).shuffleGrouping("spoutid"); builder.setBolt("committer", new MyCommitter(),1).shuffleGrouping("bolt1") ; Config conf = new Config() ; conf.setDebug(false); if (args.length > 0) { try { StormSubmitter.submitTopology(args[0], conf, builder.buildTopology()); } catch (AlreadyAliveException e) { e.printStackTrace(); } catch (InvalidTopologyException e) { e.printStackTrace(); } }else { LocalCluster localCluster = new LocalCluster(); localCluster.submitTopology("mytopology", conf, builder.buildTopology()); } } } package com.sxt.storm.transactional; import java.util.HashMap; import java.util.Map; import java.util.Random; import backtype.storm.task.TopologyContext; import backtype.storm.topology.OutputFieldsDeclarer; import backtype.storm.transactional.ITransactionalSpout; import backtype.storm.tuple.Fields; public class MyTxSpout implements ITransactionalSpout<MyMeta> { /** * 数据源 */ Map<Long, String> dbMap = null; public MyTxSpout() { Random random = new Random(); dbMap = new HashMap<Long, String>(); String[] hosts = { "www.taobao.com" }; String[] session_id = { "ABYH6Y4V4SCVXTG6DPB4VH9U123", "XXYH6YCGFJYERTT834R52FDXV9U34", "BBYH61456FGHHJ7JL89RG5VV9UYU7", "CYYH6Y2345GHI899OFG4V9U567", "VVVYH6Y4V4SFXZ56JIPDPB4V678" }; String[] time = { "2017-02-21 08:40:50", "2017-02-21 08:40:51", "2017-02-21 08:40:52", "2017-02-21 08:40:53", "2017-02-21 09:40:49", "2017-02-21 10:40:49", "2017-02-21 11:40:49", "2017-02-21 12:40:49" }; for (long i = 0; i < 100; i++) { dbMap.put(i, hosts[0] + " " + session_id[random.nextInt(5)] + " " + time[random.nextInt(8)]); } } private static final long serialVersionUID = 1L; @Override public backtype.storm.transactional.ITransactionalSpout.Coordinator<MyMeta> getCoordinator(Map conf, TopologyContext context) { return new MyCoordinator(); } @Override public backtype.storm.transactional.ITransactionalSpout.Emitter<MyMeta> getEmitter(Map conf, TopologyContext context) { return new MyEmitter(dbMap); } @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("tx", "log")); } @Override public Map<String, Object> getComponentConfiguration() { return null; } } package com.sxt.storm.transactional; import java.util.Map; import backtype.storm.coordination.BatchOutputCollector; import backtype.storm.task.TopologyContext; import backtype.storm.topology.OutputFieldsDeclarer; import backtype.storm.topology.base.BaseTransactionalBolt; import backtype.storm.transactional.TransactionAttempt; import backtype.storm.tuple.Fields; import backtype.storm.tuple.Tuple; import backtype.storm.tuple.Values; public class MyTransactionBolt extends BaseTransactionalBolt { /** * */ private static final long serialVersionUID = 1L; Integer count = 0; BatchOutputCollector collector; TransactionAttempt tx ; @Override public void prepare(Map conf, TopologyContext context, BatchOutputCollector collector, TransactionAttempt id) { this.collector = collector; System.err.println("MyTransactionBolt prepare txid:"+id.getTransactionId() +"; attemptid: "+id.getAttemptId()); } /** * 处理batch中每一个tuple */ @Override public void execute(Tuple tuple) { tx = (TransactionAttempt) tuple.getValue(0); System.err.println("MyTransactionBolt TransactionAttempt txid:"+tx.getTransactionId() +"; attemptid:"+tx.getAttemptId()); String log = tuple.getString(1); if (log != null && log.length()>0) { count ++ ; } } /** * 同一个batch处理完成后,会调用一次finishBatch方法 */ @Override public void finishBatch() { System.err.println("finishBatch: "+count ); collector.emit(new Values(tx,count)); } @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("tx","count")); } } package com.sxt.storm.transactional; import java.math.BigInteger; import java.util.HashMap; import java.util.Map; import backtype.storm.coordination.BatchOutputCollector; import backtype.storm.task.TopologyContext; import backtype.storm.topology.OutputFieldsDeclarer; import backtype.storm.topology.base.BaseTransactionalBolt; import backtype.storm.transactional.ICommitter; import backtype.storm.transactional.TransactionAttempt; import backtype.storm.tuple.Tuple; public class MyCommitter extends BaseTransactionalBolt implements ICommitter { /** * */ private static final long serialVersionUID = 1L; public static final String GLOBAL_KEY = "GLOBAL_KEY"; public static Map<String, DbValue> dbMap = new HashMap<String, DbValue>(); int sum = 0; TransactionAttempt id; BatchOutputCollector collector; @Override public void execute(Tuple tuple) { sum += tuple.getInteger(1); } @Override public void finishBatch() { DbValue value = dbMap.get(GLOBAL_KEY); DbValue newValue; if (value == null || !value.txid.equals(id.getTransactionId())) { // 更新数据库 newValue = new DbValue(); newValue.txid = id.getTransactionId(); if (value == null) { newValue.count = sum; } else { newValue.count = value.count + sum; } dbMap.put(GLOBAL_KEY, newValue); } else { newValue = value; } System.out.println("total==========================:" + dbMap.get(GLOBAL_KEY).count); // collector.emit(tuple) } @Override public void prepare(Map conf, TopologyContext context, BatchOutputCollector collector, TransactionAttempt id) { this.id = id; this.collector = collector; } @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { } public static class DbValue { BigInteger txid; int count = 0; } }