SparkStreaming+Kafka •kafka是什么,有哪些特点 •SparkStreaming+Kafka有什么好处 –解耦 –缓冲


消息列队的特点 生产者消费者模式 •可靠性保证 –自己不丢数据 –消费者不丢数据:“至少一次,严格一次”
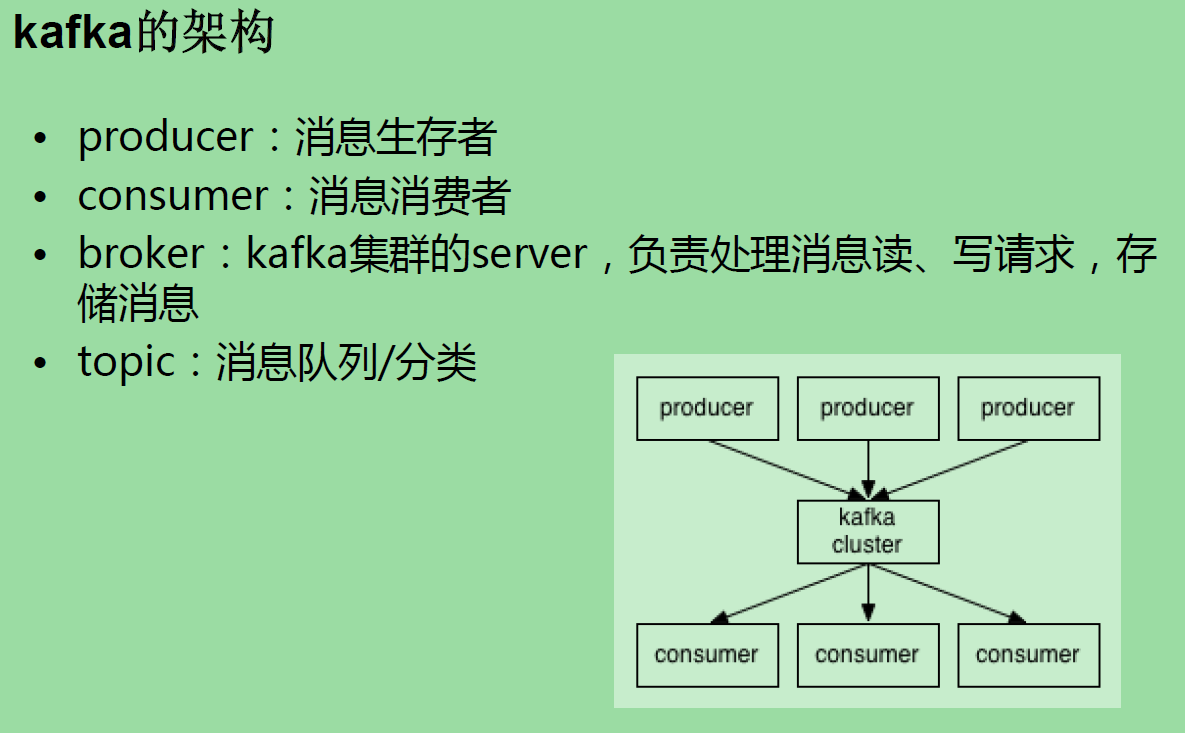
broker n. 经纪人,掮客 vt. 以中间人等身分安排... vi. 作为权力经纪人进行谈判

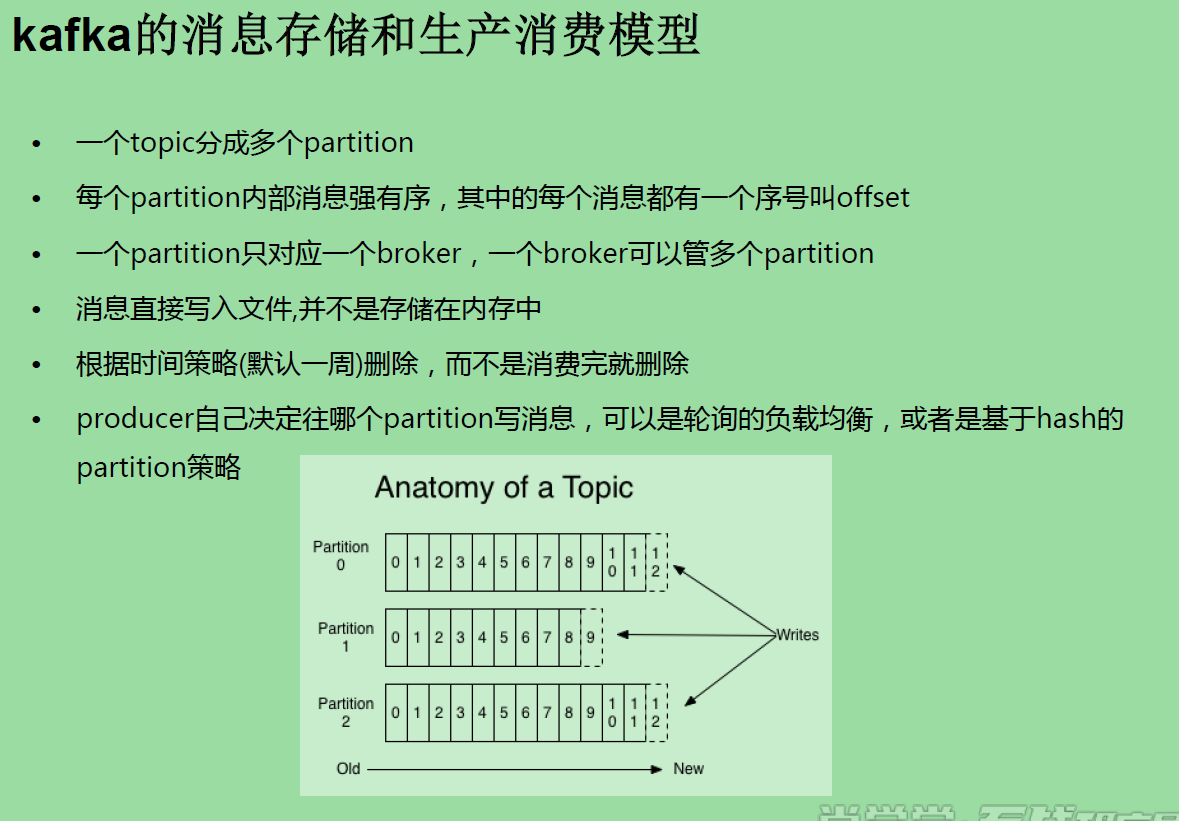

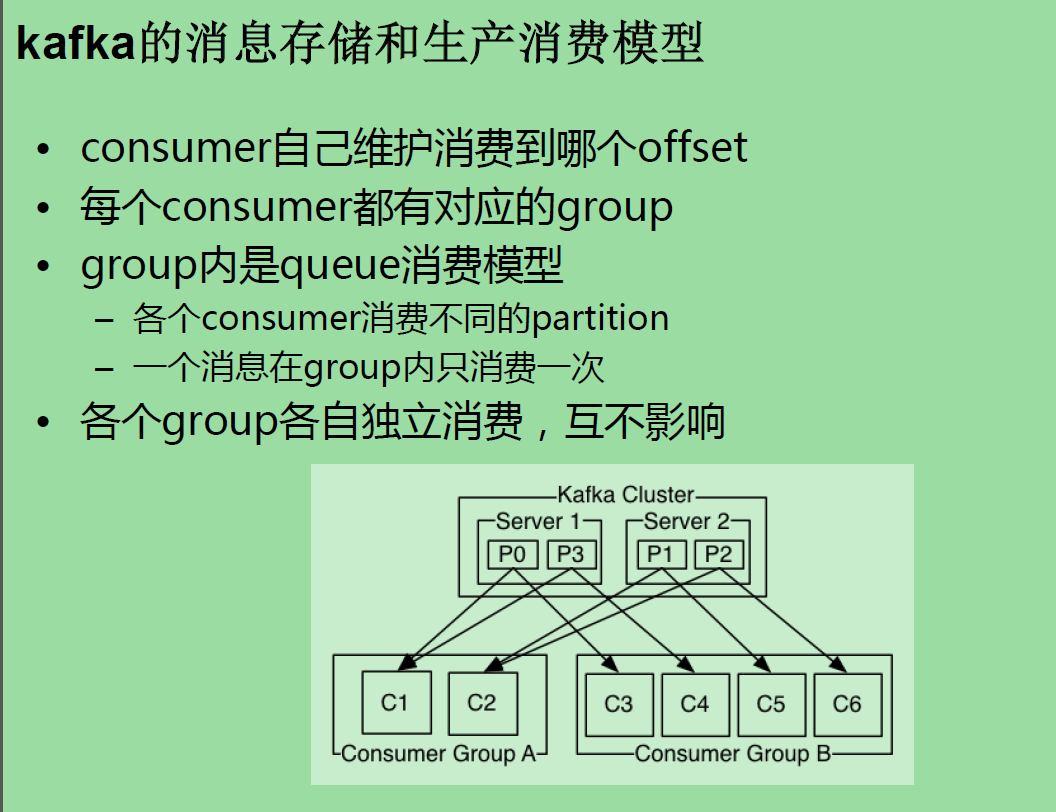


kafka部署 node2,3,4 基于zookeeper 启动 三台 zookeeper /opt/sxt/zookeeper-3.4.6/bin/zkServer.sh start 配置kafka tar -zxvf kafka_2.10-0.8.2.2.tgz -C /opt/sxt/ kafka_2.10-0.8.2.2/config/ vi server.properties broker.id=0 ## node2为0 node3为1 node4为2 log.dirs=/kafka-logs zookeeper.connect=node2:2181,node3:2181,node4:2181 ## scp 到node3,node4,并且修改 broker.id=0 node2 kafka bin下 尝试启动一台 ./kafka-server-start.sh ../config/server.properties ##编写脚本 使用后台启动 [root@node2 shells]# pwd /root/shells [root@node2 shells]# cat start-kafka.sh cd /opt/sxt/kafka_2.10-0.8.2.2 nohup bin/kafka-server-start.sh config/server.properties >kafka.log 2>&1 & ## scp 到node3,4 ## 批量执行 node2,3,4 /root/shells/start-kafka.sh ##启动三台kafka集群成功。

如何创建topic 并且生产者生产数据,消费者消费数据 node,2,3,4 是broker node1 作为producer,node5 作为consumer. scp kafka 到node1,node5,作为客户端准备
创建topic:
./kafka-topics.sh -zookeeper node2:2181,node3,node4 --create --topic t0425 --partitions 3 --replication-factor 3
[root@node1 bin]# ./kafka-console-producer.sh --topic t0425 --broker-list node2:9092,node3:9092,node4:9092
[2019-09-28 10:35:33,341] WARN Property topic is not valid (kafka.utils.VerifiableProperties)
hello ## 生产数据
world
hello
world
a
b
c
d
e
[root@node5 bin]# ./kafka-console-consumer.sh --zookeeper node2,node3:2181,node4 --topic t0425
world ## 消费数据
hello
world
a
b
c
d ## ....
## 查看topic
[root@node5 bin]# ./kafka-topics.sh --zookeeper node2:2181,node4,node5 --list
t0425
[root@node2 bin]# cd /opt/sxt/zookeeper-3.4.6/bin/zkCli.sh ##在node2上查看topic和维护的数据
[zk: localhost:2181(CONNECTED) 1] ls /
[zk: localhost:2181(CONNECTED) 8] ls /brokers/topics/t0425/partitions/0/state
[zk: localhost:2181(CONNECTED) 9] get /brokers/topics/t0425/partitions/0/state
{"controller_epoch":7,"leader":1,"version":1,"leader_epoch":0,"isr":[1,2,0]}
## isr":[1,2,0]用于检查数据的完整性
[zk: localhost:2181(CONNECTED) 16] get /consumers/console-consumer-66598/offsets/t0425/0
11 ## 表示分区管理的数据条数
[zk: localhost:2181(CONNECTED) 17] get /consumers/console-consumer-66598/offsets/t0425/1
5
[zk: localhost:2181(CONNECTED) 18] get /consumers/console-consumer-66598/offsets/t0425/2
0
## 过10分钟左右在生产数据,其他分区如1分区的数据会增长,相当于切换hash一次分区
## 如何删除topic
[root@node5 bin]# ./kafka-topics.sh --zookeeper node2:2181,node4,node5 --delete --topic t0425
[root@node5 bin]# ./kafka-topics.sh --zookeeper node2:2181,node4,node5 --list
t0425 - marked for deletion
[root@node2 bin]# cd /kafka-logs/
[root@node2 kafka-logs]# rm -rf ./t0425*
[root@node3 ~]# cd /kafka-logs/
[root@node3 kafka-logs]# rm -rf ./t0425*
[root@node4 ~]# cd /kafka-logs/
[root@node4 kafka-logs]# rm -rf ./t0425*
[root@node2 bin]# ./zkCli.sh
[zk: localhost:2181(CONNECTED) 3] rmr /brokers/topics/t0425
[zk: localhost:2181(CONNECTED) 5] rmr /admin/delete_topics/t0425
## 接下来过一周之后topic会自动删除。但是目前也还可以继续使用。
## 查看描述情况
[root@node5 bin]# ./kafka-topics.sh --zookeeper node2:2181,node4,node5 --describe
Topic:t0425 PartitionCount:3 ReplicationFactor:3 Configs:
Topic: t0425 Partition: 0 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
Topic: t0425 Partition: 1 Leader: 2 Replicas: 2,0,1 Isr: 2,0,1
Topic: t0425 Partition: 2 Leader: 0 Replicas: 0,1,2 Isr: 0,1,2
[root@node5 bin]# ./kafka-topics.sh --zookeeper node2:2181,node4,node5 --describe --topic t0425 ## 查看指定topic的订阅情况
Topic:t0425 PartitionCount:3 ReplicationFactor:3 Configs:
Topic: t0425 Partition: 0 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
Topic: t0425 Partition: 1 Leader: 2 Replicas: 2,0,1 Isr: 2,0,1
Topic: t0425 Partition: 2 Leader: 0 Replicas: 0,1,2 Isr: 0,1,2
## Replicas: 1,2,0 备份点,Isr: 1,2,0数据完整性检查点
## kafka leader 均衡的机制。 如上: 每一个分区属于一个leader,当leader0挂掉之后,kafka会自动寻找leader,继续完成接收producer,处理comsumer请求。当leader0恢复正常后,kafka会将partition0自动释放给leader0
[root@node1 bin]# ./kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list node2:9092 --topic t0426 --time -1 ## 查看各个分区的消息数量 t0426:0:0 t0426:1:0 t0426:2:0
SparkStreaming + kafka 整合有两种模式 Receiver Direct 模式。 官网: http://kafka.apache.org/documentation/#producerapi http://kafka.apache.org/082/documentation.html 0.8 版本

package com.bjsxt.sparkstreaming;
import java.util.Arrays;
import java.util.HashMap;
import java.util.Map;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.storage.StorageLevel;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaPairReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka.KafkaUtils;
import scala.Tuple2;
/**
* receiver 模式并行度是由blockInterval决定的
* @author root
*
*/
public class SparkStreamingOnKafkaReceiver {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("SparkStreamingOnKafkaReceiver")
.setMaster("local[2]");
//开启预写日志 WAL机制
conf.set("spark.streaming.receiver.writeAheadLog.enable","true");
JavaStreamingContext jsc = new JavaStreamingContext(conf, Durations.seconds(5));
jsc.checkpoint("./receivedata");
Map<String, Integer> topicConsumerConcurrency = new HashMap<String, Integer>();
/**
* 设置读取的topic和接受数据的线程数
*/
topicConsumerConcurrency.put("t0426", 1);
/**
* 第一个参数是StreamingContext
* 第二个参数是ZooKeeper集群信息(接受Kafka数据的时候会从Zookeeper中获得Offset等元数据信息)
* 第三个参数是Consumer Group 消费者组
* 第四个参数是消费的Topic以及并发读取Topic中Partition的线程数
*
* 注意:
* KafkaUtils.createStream 使用五个参数的方法,设置receiver的存储级别
*/
// JavaPairReceiverInputDStream<String,String> lines = KafkaUtils.createStream(
// jsc,
// "node2:2181,node3:2181,node3:2181",
// "MyFirstConsumerGroup",
// topicConsumerConcurrency);
JavaPairReceiverInputDStream<String,String> lines = KafkaUtils.createStream(
jsc,
"node2:2181,node3:2181,node3:2181",
"MyFirstConsumerGroup",
topicConsumerConcurrency/*,
StorageLevel.MEMORY_AND_DISK()*/);
JavaDStream<String> words = lines.flatMap(new FlatMapFunction<Tuple2<String,String>, String>() {
/**
*
*/
private static final long serialVersionUID = 1L;
public Iterable<String> call(Tuple2<String,String> tuple) throws Exception {
System.out.println("key = " + tuple._1);
System.out.println("value = " + tuple._2);
return Arrays.asList(tuple._2.split(" "));
}
});
JavaPairDStream<String, Integer> pairs = words.mapToPair(new PairFunction<String, String, Integer>() {
/**
*
*/
private static final long serialVersionUID = 1L;
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String, Integer>(word, 1);
}
});
JavaPairDStream<String, Integer> wordsCount = pairs.reduceByKey(new Function2<Integer, Integer, Integer>() {
//对相同的Key,进行Value的累计(包括Local和Reducer级别同时Reduce)
/**
*
*/
private static final long serialVersionUID = 1L;
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
wordsCount.print(100);
jsc.start();
jsc.awaitTermination();
jsc.close();
}
}
package com.bjsxt.sparkstreaming;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Properties;
import java.util.Random;
import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
import kafka.serializer.StringEncoder;
/**
* 向kafka中生产数据
* @author root
*
*/
public class SparkStreamingDataManuallyProducerForKafka extends Thread{
static String[] channelNames = new String[]{
"Spark","Scala","Kafka","Flink","Hadoop","Storm",
"Hive","Impala","HBase","ML"
};
static String[] actionNames = new String[]{"View", "Register"};
private String topic; //发送给Kafka的数据,topic
private Producer<String, String> producerForKafka;
private static String dateToday;
private static Random random;
public SparkStreamingDataManuallyProducerForKafka(String topic){
dateToday = new SimpleDateFormat("yyyy-MM-dd").format(new Date());
this.topic = topic;
random = new Random();
Properties properties = new Properties();
properties.put("metadata.broker.list","node2:9092,node3:9092,node4:9092");
//发送消息key的编码格式
properties.put("key.serializer.class", StringEncoder.class.getName());
//发送消息value的编码格式
properties.put("serializer.class", StringEncoder.class.getName());
producerForKafka = new Producer<String, String>(new ProducerConfig(properties)) ;
}
@Override
public void run() {
int counter = 0;
while(true){
counter++;
String userLog = userlogs();
// System.out.println("product:"+userLog+" ");
producerForKafka.send(new KeyedMessage<String, String>(topic,userLog));
producerForKafka.send(new KeyedMessage<String, String>(topic,"key-" + counter,userLog));
//每两条数据暂停2秒
if(0 == counter%2){
// counter = 0;
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public static void main( String[] args ){
new SparkStreamingDataManuallyProducerForKafka("t0426").start();
}
//生成随机数据
private static String userlogs() {
StringBuffer userLogBuffer = new StringBuffer("");
int[] unregisteredUsers = new int[]{1, 2, 3, 4, 5, 6, 7, 8};
long timestamp = new Date().getTime();
Long userID = 0L;
long pageID = 0L;
//随机生成的用户ID
if(unregisteredUsers[random.nextInt(8)] == 1) {
userID = null;
} else {
userID = (long) random.nextInt(2000);
}
//随机生成的页面ID
pageID = random.nextInt(2000);
//随机生成Channel
String channel = channelNames[random.nextInt(10)];
//随机生成action行为
String action = actionNames[random.nextInt(2)];
userLogBuffer.append(dateToday)
.append(" ")
.append(timestamp)
.append(" ")
.append(userID)
.append(" ")
.append(pageID)
.append(" ")
.append(channel)
.append(" ")
.append(action);
// .append("
");
System.out.println(userLogBuffer.toString());
return userLogBuffer.toString();
}
}
supervise
v. 监督;管理;指导;主管;照看
Direct 模式
package com.bjsxt.sparkstreaming.util;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.UUID;
/**
* 此复制文件的程序是模拟在data目录下动态生成相同格式的txt文件,用于给sparkstreaming 中 textFileStream提供输入流。
* @author root
*
*/
public class CopyFile_data {
public static void main(String[] args) throws IOException, InterruptedException {
while(true){
Thread.sleep(5000);
String uuid = UUID.randomUUID().toString();
System.out.println(uuid);
copyFile(new File("words.txt"),new File(".\data\"+uuid+"----words.txt"));
}
}
public static void copyFile(File fromFile, File toFile) throws IOException {
FileInputStream ins = new FileInputStream(fromFile);
FileOutputStream out = new FileOutputStream(toFile);
byte[] b = new byte[1024*1024];
@SuppressWarnings("unused")
int n = 0;
while ((n = ins.read(b)) != -1) {
out.write(b, 0, b.length);
}
ins.close();
out.close();
}
}
// 监控checkpoint 目录,运行如下代码一次,停止,再运行,读取checkpoint目录恢复数据,不在打印new context
package com.bjsxt.sparkstreaming;
import java.util.Arrays;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.api.java.JavaStreamingContextFactory;
import scala.Tuple2;
/**
*
* Spark standalone or Mesos with cluster deploy mode only:
* 在提交application的时候 添加 --supervise 选项 如果Driver挂掉 会自动启动一个Driver
*
*/
public class SparkStreamingOnHDFS {
public static void main(String[] args) {
final SparkConf conf = new SparkConf().setMaster("local").setAppName("SparkStreamingOnHDFS");
// final String checkpointDirectory = "hdfs://node1:9000/spark/SparkStreaming/CheckPoint2017";
final String checkpointDirectory = "./checkpoint";
JavaStreamingContextFactory factory = new JavaStreamingContextFactory() {
@Override
public JavaStreamingContext create() {
return createContext(checkpointDirectory,conf);
}
};
/**
* 获取JavaStreamingContext 先去指定的checkpoint目录中去恢复JavaStreamingContext
* 如果恢复不到,通过factory创建
*/
JavaStreamingContext jsc = JavaStreamingContext.getOrCreate(checkpointDirectory, factory);
jsc.start();
jsc.awaitTermination();
jsc.close();
}
// @SuppressWarnings("deprecation")
private static JavaStreamingContext createContext(String checkpointDirectory,SparkConf conf) {
// If you do not see this printed, that means the StreamingContext has
// been loaded
// from the new checkpoint
System.out.println("Creating new context");
SparkConf sparkConf = conf;
// Create the context with a 1 second batch size
JavaStreamingContext ssc = new JavaStreamingContext(sparkConf, Durations.seconds(5));
// ssc.sparkContext().setLogLevel("WARN");
/**
* checkpoint 保存:
* 1.配置信息
* 2.DStream操作逻辑
* 3.job的执行进度
* 4.offset
*/
ssc.checkpoint(checkpointDirectory);
/**
* 监控的是HDFS上的一个目录,监控文件数量的变化 文件内容如果追加监控不到。
* 只监控文件夹下新增的文件,减少的文件时监控不到的,文件的内容有改动也监控不到。
*/
// JavaDStream<String> lines = ssc.textFileStream("hdfs://node1:9000/spark/sparkstreaming");
JavaDStream<String> lines = ssc.textFileStream("./data");
JavaDStream<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public Iterable<String> call(String s) {
return Arrays.asList(s.split(" "));
}
});
JavaPairDStream<String, Integer> ones = words.mapToPair(new PairFunction<String, String, Integer>() {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, Integer> call(String s) {
return new Tuple2<String, Integer>(s.trim(), 1);
}
});
JavaPairDStream<String, Integer> counts = ones.reduceByKey(new Function2<Integer, Integer, Integer>() {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public Integer call(Integer i1, Integer i2) {
return i1 + i2;
}
});
counts.print();
// counts.filter(new Function<Tuple2<String,Integer>, Boolean>() {
//
// /**
// *
// */
// private static final long serialVersionUID = 1L;
//
// @Override
// public Boolean call(Tuple2<String, Integer> v1) throws Exception {
// System.out.println("*************************");
// return true;
// }
// }).print();
return ssc;
}
}
package com.bjsxt.sparkstreaming;
import java.util.Arrays;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
import kafka.serializer.DefaultEncoder;
import kafka.serializer.StringDecoder;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaPairInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka.KafkaUtils;
import scala.Tuple2;
/**
* 并行度:
* 1、linesDStram里面封装到的是RDD, RDD里面有partition与读取topic的parititon数是一致的。
* 2、从kafka中读来的数据封装一个DStram里面,可以对这个DStream重分区 reaprtitions(numpartition)
*
* @author root
*
*/
public class SparkStreamingOnKafkaDirected {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setMaster("local").setAppName("SparkStreamingOnKafkaDirected");
// conf.set("spark.streaming.backpressure.enabled", "false");
// conf.set("spark.streaming.kafka.maxRatePerPartition ", "100");
JavaStreamingContext jsc = new JavaStreamingContext(conf, Durations.seconds(5));
/**
* 可以不设置checkpoint 不设置不保存offset,offset默认在内存中有一份,如果设置checkpoint在checkpoint也有一份offset, 一般要设置。
*/
jsc.checkpoint("./checkpoint");
Map<String, String> kafkaParameters = new HashMap<String, String>();
kafkaParameters.put("metadata.broker.list", "node2:9092,node3:9092,node4:9092");
// kafkaParameters.put("auto.offset.reset", "smallest");
HashSet<String> topics = new HashSet<String>();
topics.add("t0426");
JavaPairInputDStream<String,String> lines = KafkaUtils.createDirectStream(jsc,
String.class,
String.class,
StringDecoder.class,
StringDecoder.class,
kafkaParameters,
topics);
JavaDStream<String> words = lines.flatMap(new FlatMapFunction<Tuple2<String,String>, String>() { //如果是Scala,由于SAM转换,所以可以写成val words = lines.flatMap { line => line.split(" ")}
/**
*
*/
private static final long serialVersionUID = 1L;
public Iterable<String> call(Tuple2<String,String> tuple) throws Exception {
return Arrays.asList(tuple._2.split(" "));
}
});
JavaPairDStream<String, Integer> pairs = words.mapToPair(new PairFunction<String, String, Integer>() {
/**
*
*/
private static final long serialVersionUID = 1L;
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String, Integer>(word, 1);
}
});
JavaPairDStream<String, Integer> wordsCount = pairs.reduceByKey(new Function2<Integer, Integer, Integer>() { //对相同的Key,进行Value的累计(包括Local和Reducer级别同时Reduce)
/**
*
*/
private static final long serialVersionUID = 1L;
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
wordsCount.print();
jsc.start();
jsc.awaitTermination();
jsc.close();
}
}
如何搭建Driver Ha ? * Spark standalone or Mesos with cluster deploy mode only: * 在提交application的时候 添加 --supervise 选项 如果Driver挂掉 会自动启动一个Driver Direct 模式,如何管理SparkStreaming 读取的zookeeper的消息offset
Direct 自动管理
生产部份数据
package com.bjsxt.sparkstreaming;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Properties;
import java.util.Random;
import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
import kafka.serializer.StringEncoder;
/**
* 向kafka中生产数据
* @author root
*
*/
public class SparkStreamingDataManuallyProducerForKafka extends Thread{
static String[] channelNames = new String[]{
"Spark","Scala","Kafka","Flink","Hadoop","Storm",
"Hive","Impala","HBase","ML"
};
static String[] actionNames = new String[]{"View", "Register"};
private String topic; //发送给Kafka的数据,topic
private Producer<String, String> producerForKafka;
private static String dateToday;
private static Random random;
public SparkStreamingDataManuallyProducerForKafka(String topic){
dateToday = new SimpleDateFormat("yyyy-MM-dd").format(new Date());
this.topic = topic;
random = new Random();
Properties properties = new Properties();
properties.put("metadata.broker.list","node2:9092,node3:9092,node4:9092");
//发送消息key的编码格式
properties.put("key.serializer.class", StringEncoder.class.getName());
//发送消息value的编码格式
properties.put("serializer.class", StringEncoder.class.getName());
producerForKafka = new Producer<String, String>(new ProducerConfig(properties)) ;
}
@Override
public void run() {
int counter = 0;
while(true){
counter++;
String userLog = userlogs();
// System.out.println("product:"+userLog+" ");
producerForKafka.send(new KeyedMessage<String, String>(topic,userLog));
producerForKafka.send(new KeyedMessage<String, String>(topic,"key-" + counter,userLog));
//每两条数据暂停2秒
if(0 == counter%2){
// counter = 0;
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public static void main( String[] args ){
new SparkStreamingDataManuallyProducerForKafka("t0426").start();
}
//生成随机数据
private static String userlogs() {
StringBuffer userLogBuffer = new StringBuffer("");
int[] unregisteredUsers = new int[]{1, 2, 3, 4, 5, 6, 7, 8};
long timestamp = new Date().getTime();
Long userID = 0L;
long pageID = 0L;
//随机生成的用户ID
if(unregisteredUsers[random.nextInt(8)] == 1) {
userID = null;
} else {
userID = (long) random.nextInt(2000);
}
//随机生成的页面ID
pageID = random.nextInt(2000);
//随机生成Channel
String channel = channelNames[random.nextInt(10)];
//随机生成action行为
String action = actionNames[random.nextInt(2)];
userLogBuffer.append(dateToday)
.append(" ")
.append(timestamp)
.append(" ")
.append(userID)
.append(" ")
.append(pageID)
.append(" ")
.append(channel)
.append(" ")
.append(action);
// .append("
");
System.out.println(userLogBuffer.toString());
return userLogBuffer.toString();
}
}
自定义管理offset 主函数
package com.manage;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.concurrent.atomic.AtomicReference;
import com.google.common.collect.ImmutableMap;
import com.manage.getOffset.GetTopicOffsetFromKafkaBroker;
import com.manage.getOffset.GetTopicOffsetFromZookeeper;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.retry.RetryUntilElapsed;
import org.apache.log4j.Logger;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaInputDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.api.java.JavaStreamingContextFactory;
import org.apache.spark.streaming.kafka.HasOffsetRanges;
import org.apache.spark.streaming.kafka.KafkaUtils;
import org.apache.spark.streaming.kafka.OffsetRange;
import kafka.cluster.Broker;
import com.fasterxml.jackson.databind.ObjectMapper;
import kafka.api.PartitionOffsetRequestInfo;
import kafka.common.TopicAndPartition;
import kafka.javaapi.OffsetRequest;
import kafka.javaapi.OffsetResponse;
import kafka.javaapi.PartitionMetadata;
import kafka.javaapi.TopicMetadata;
import kafka.javaapi.TopicMetadataRequest;
import kafka.javaapi.TopicMetadataResponse;
import kafka.javaapi.consumer.SimpleConsumer;
import kafka.message.MessageAndMetadata;
import kafka.serializer.StringDecoder;
import scala.Tuple2;
public class UseZookeeperManageOffset {
/**
* 使用log4j打印日志,“UseZookeeper.class” 设置日志的产生类
*/
static final Logger logger = Logger.getLogger(UseZookeeperManageOffset.class);
public static void main(String[] args) {
/**
* 加载log4j的配置文件,方便打印日志
*/
ProjectUtil.LoadLogConfig();
logger.info("project is starting...");
/**
* 从kafka集群中得到topic每个分区中生产消息的最大偏移量位置
*/
Map<TopicAndPartition, Long> topicOffsets = GetTopicOffsetFromKafkaBroker.getTopicOffsets("node2:9092,node3:9092,node4:9092", "t0426");
/**
* 从zookeeper中获取当前topic每个分区 consumer 消费的offset位置
*/
Map<TopicAndPartition, Long> consumerOffsets =
GetTopicOffsetFromZookeeper.getConsumerOffsets("node2:2181,node3:2181,node4:2181","ConsumerGroup","t0426");
/**
* 合并以上得到的两个offset ,
* 思路是:
* 如果zookeeper中读取到consumer的消费者偏移量,那么就zookeeper中当前的offset为准。
* 否则,如果在zookeeper中读取不到当前消费者组消费当前topic的offset,就是当前消费者组第一次消费当前的topic,
* offset设置为topic中消息的最大位置。
*/
if(null!=consumerOffsets && consumerOffsets.size()>0){
topicOffsets.putAll(consumerOffsets);
}
/**
* 如果将下面的代码解开,是将topicOffset 中当前topic对应的每个partition中消费的消息设置为0,就是从头开始。
*/
// for(Map.Entry<TopicAndPartition, Long> item:topicOffsets.entrySet()){
// item.setValue(0l);
// }
/**
* 构建SparkStreaming程序,从当前的offset消费消息
*/
JavaStreamingContext jsc = SparkStreamingDirect.getStreamingContext(topicOffsets,"ConsumerGroup");
jsc.start();
jsc.awaitTermination();
jsc.close();
}
}
package com.manage;
import java.io.IOException;
import java.io.InputStream;
import java.util.Properties;
import org.apache.log4j.Logger;
import org.apache.log4j.PropertyConfigurator;
public class ProjectUtil {
/**
* 使用log4j配置打印日志
*/
static final Logger logger = Logger.getLogger(UseZookeeperManageOffset.class);
/**
* 加载配置的log4j.properties,默认读取的路径在src下,如果将log4j.properties放在别的路径中要手动加载
*/
public static void LoadLogConfig() {
PropertyConfigurator.configure("./resource/log4j.properties");
// PropertyConfigurator.configure("d:/eclipse4.7WS/SparkStreaming_Kafka_Manage/resource/log4j.properties");
}
/**
* 加载配置文件
* 需要将放config.properties的目录设置成资源目录
* @return
*/
public static Properties loadProperties() {
Properties props = new Properties();
InputStream inputStream = Thread.currentThread().getContextClassLoader().getResourceAsStream("config.properties");
if(null != inputStream) {
try {
props.load(inputStream);
} catch (IOException e) {
logger.error(String.format("Config.properties file not found in the classpath"));
}
}
return props;
}
public static void main(String[] args) {
Properties props = loadProperties();
String value = props.getProperty("hello");
System.out.println(value);
}
}
package com.manage.getOffset;
import java.util.Arrays;
import java.util.HashMap;
import java.util.Map;
import java.util.Map.Entry;
import java.util.Set;
import com.google.common.collect.ImmutableMap;
import kafka.api.PartitionOffsetRequestInfo;
import kafka.cluster.Broker;
import kafka.common.TopicAndPartition;
import kafka.javaapi.OffsetRequest;
import kafka.javaapi.OffsetResponse;
import kafka.javaapi.PartitionMetadata;
import kafka.javaapi.TopicMetadata;
import kafka.javaapi.TopicMetadataRequest;
import kafka.javaapi.TopicMetadataResponse;
import kafka.javaapi.consumer.SimpleConsumer;
/**
* 测试之前需要启动kafka
* @author root
*
*/
public class GetTopicOffsetFromKafkaBroker {
public static void main(String[] args) {
Map<TopicAndPartition, Long> topicOffsets = getTopicOffsets("node2:9092,node3:9092,node4:9092", "t0426");
Set<Entry<TopicAndPartition, Long>> entrySet = topicOffsets.entrySet();
for(Entry<TopicAndPartition, Long> entry : entrySet) {
TopicAndPartition topicAndPartition = entry.getKey();
Long offset = entry.getValue();
String topic = topicAndPartition.topic();
int partition = topicAndPartition.partition();
System.out.println("topic = "+topic+",partition = "+partition+",offset = "+offset);
}
}
/**
* 从kafka集群中得到当前topic,生产者在每个分区中生产消息的偏移量位置
* @param KafkaBrokerServer
* @param topic
* @return
*/
public static Map<TopicAndPartition,Long> getTopicOffsets(String KafkaBrokerServer, String topic){
Map<TopicAndPartition,Long> retVals = new HashMap<TopicAndPartition,Long>();
for(String broker:KafkaBrokerServer.split(",")){
SimpleConsumer simpleConsumer = new SimpleConsumer(broker.split(":")[0],Integer.valueOf(broker.split(":")[1]), 64*10000,1024,"consumer");
TopicMetadataRequest topicMetadataRequest = new TopicMetadataRequest(Arrays.asList(topic));
TopicMetadataResponse topicMetadataResponse = simpleConsumer.send(topicMetadataRequest);
for (TopicMetadata metadata : topicMetadataResponse.topicsMetadata()) {
for (PartitionMetadata part : metadata.partitionsMetadata()) {
Broker leader = part.leader();
if (leader != null) {
TopicAndPartition topicAndPartition = new TopicAndPartition(topic, part.partitionId());
PartitionOffsetRequestInfo partitionOffsetRequestInfo = new PartitionOffsetRequestInfo(kafka.api.OffsetRequest.LatestTime(), 10000);
OffsetRequest offsetRequest = new OffsetRequest(ImmutableMap.of(topicAndPartition, partitionOffsetRequestInfo), kafka.api.OffsetRequest.CurrentVersion(), simpleConsumer.clientId());
OffsetResponse offsetResponse = simpleConsumer.getOffsetsBefore(offsetRequest);
if (!offsetResponse.hasError()) {
long[] offsets = offsetResponse.offsets(topic, part.partitionId());
retVals.put(topicAndPartition, offsets[0]);
}
}
}
}
simpleConsumer.close();
}
return retVals;
}
}
package com.manage;
import java.util.Arrays;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.atomic.AtomicReference;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.retry.RetryUntilElapsed;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaInputDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka.HasOffsetRanges;
import org.apache.spark.streaming.kafka.KafkaUtils;
import org.apache.spark.streaming.kafka.OffsetRange;
import com.fasterxml.jackson.databind.ObjectMapper;
import kafka.common.TopicAndPartition;
import kafka.message.MessageAndMetadata;
import kafka.serializer.StringDecoder;
import scala.Tuple2;
public class SparkStreamingDirect {
public static JavaStreamingContext getStreamingContext(Map<TopicAndPartition, Long> topicOffsets,String groupID){
// local == local[1]
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("SparkStreamingOnKafkaDirect");
conf.set("spark.streaming.kafka.maxRatePerPartition", "10"); // 每个分区每批次读取10条
JavaStreamingContext jsc = new JavaStreamingContext(conf, Durations.seconds(5));
// jsc.checkpoint("/checkpoint");
Map<String, String> kafkaParams = new HashMap<String, String>();
kafkaParams.put("metadata.broker.list","node2:9092,node3:9092,node4:9092");
// kafkaParams.put("group.id","MyFirstConsumerGroup");
for(Map.Entry<TopicAndPartition,Long> entry:topicOffsets.entrySet()){
System.out.println(entry.getKey().topic()+" "+entry.getKey().partition()+" "+entry.getValue());
}
JavaInputDStream<String> message = KafkaUtils.createDirectStream(
jsc,
String.class,
String.class,
StringDecoder.class,
StringDecoder.class,
String.class,
kafkaParams,
topicOffsets,
new Function<MessageAndMetadata<String,String>,String>() {
/**
*
*/
private static final long serialVersionUID = 1L;
public String call(MessageAndMetadata<String, String> v1)throws Exception {
return v1.message();
}
}
);
final AtomicReference<OffsetRange[]> offsetRanges = new AtomicReference<>();
JavaDStream<String> lines = message.transform(new Function<JavaRDD<String>, JavaRDD<String>>() {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public JavaRDD<String> call(JavaRDD<String> rdd) throws Exception {
OffsetRange[] offsets = ((HasOffsetRanges) rdd.rdd()).offsetRanges();
offsetRanges.set(offsets);
return rdd;
}
}
);
message.foreachRDD(new VoidFunction<JavaRDD<String>>(){
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public void call(JavaRDD<String> t) throws Exception {
ObjectMapper objectMapper = new ObjectMapper();
CuratorFramework curatorFramework = CuratorFrameworkFactory.builder()
.connectString("node2:2181,node3:2181,node4:2181").connectionTimeoutMs(1000)
.sessionTimeoutMs(10000).retryPolicy(new RetryUntilElapsed(1000, 1000)).build();
curatorFramework.start();
for (OffsetRange offsetRange : offsetRanges.get()) {
String topic = offsetRange.topic();
int partition = offsetRange.partition();
long fromOffset = offsetRange.fromOffset();
long untilOffset = offsetRange.untilOffset();
final byte[] offsetBytes = objectMapper.writeValueAsBytes(offsetRange.untilOffset());
String nodePath = "/consumers/"+groupID+"/offsets/" + offsetRange.topic()+ "/" + offsetRange.partition();
System.out.println("nodePath = "+nodePath);
System.out.println("topic="+topic + ",partition + "+partition + ",fromOffset = "+fromOffset+",untilOffset="+untilOffset);
if(curatorFramework.checkExists().forPath(nodePath)!=null){
curatorFramework.setData().forPath(nodePath,offsetBytes);
}else{
curatorFramework.create().creatingParentsIfNeeded().forPath(nodePath, offsetBytes);
}
}
curatorFramework.close();
}
});
lines.print();
return jsc;
}
}
package com.manage;
import java.util.Arrays;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.atomic.AtomicReference;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.retry.RetryUntilElapsed;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaInputDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka.HasOffsetRanges;
import org.apache.spark.streaming.kafka.KafkaUtils;
import org.apache.spark.streaming.kafka.OffsetRange;
import com.fasterxml.jackson.databind.ObjectMapper;
import kafka.common.TopicAndPartition;
import kafka.message.MessageAndMetadata;
import kafka.serializer.StringDecoder;
import scala.Tuple2;
public class SparkStreamingDirect {
public static JavaStreamingContext getStreamingContext(Map<TopicAndPartition, Long> topicOffsets,String groupID){
// local == local[1]
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("SparkStreamingOnKafkaDirect");
conf.set("spark.streaming.kafka.maxRatePerPartition", "10"); // 每个分区每批次读取10条
JavaStreamingContext jsc = new JavaStreamingContext(conf, Durations.seconds(5));
// jsc.checkpoint("/checkpoint");
Map<String, String> kafkaParams = new HashMap<String, String>();
kafkaParams.put("metadata.broker.list","node2:9092,node3:9092,node4:9092");
// kafkaParams.put("group.id","MyFirstConsumerGroup");
for(Map.Entry<TopicAndPartition,Long> entry:topicOffsets.entrySet()){
System.out.println(entry.getKey().topic()+" "+entry.getKey().partition()+" "+entry.getValue());
}
JavaInputDStream<String> message = KafkaUtils.createDirectStream(
jsc,
String.class,
String.class,
StringDecoder.class,
StringDecoder.class,
String.class,
kafkaParams,
topicOffsets,
new Function<MessageAndMetadata<String,String>,String>() {
/**
*
*/
private static final long serialVersionUID = 1L;
public String call(MessageAndMetadata<String, String> v1)throws Exception {
return v1.message();
}
}
);
final AtomicReference<OffsetRange[]> offsetRanges = new AtomicReference<>();
JavaDStream<String> lines = message.transform(new Function<JavaRDD<String>, JavaRDD<String>>() {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public JavaRDD<String> call(JavaRDD<String> rdd) throws Exception {
OffsetRange[] offsets = ((HasOffsetRanges) rdd.rdd()).offsetRanges();
offsetRanges.set(offsets);
return rdd;
}
}
);
message.foreachRDD(new VoidFunction<JavaRDD<String>>(){
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public void call(JavaRDD<String> t) throws Exception {
ObjectMapper objectMapper = new ObjectMapper();
CuratorFramework curatorFramework = CuratorFrameworkFactory.builder()
.connectString("node2:2181,node3:2181,node4:2181").connectionTimeoutMs(1000)
.sessionTimeoutMs(10000).retryPolicy(new RetryUntilElapsed(1000, 1000)).build();
curatorFramework.start();
for (OffsetRange offsetRange : offsetRanges.get()) {
String topic = offsetRange.topic();
int partition = offsetRange.partition();
long fromOffset = offsetRange.fromOffset();
long untilOffset = offsetRange.untilOffset();
final byte[] offsetBytes = objectMapper.writeValueAsBytes(offsetRange.untilOffset());
String nodePath = "/consumers/"+groupID+"/offsets/" + offsetRange.topic()+ "/" + offsetRange.partition();
System.out.println("nodePath = "+nodePath);
System.out.println("topic="+topic + ",partition + "+partition + ",fromOffset = "+fromOffset+",untilOffset="+untilOffset);
if(curatorFramework.checkExists().forPath(nodePath)!=null){
curatorFramework.setData().forPath(nodePath,offsetBytes);
}else{
curatorFramework.create().creatingParentsIfNeeded().forPath(nodePath, offsetBytes);
}
}
curatorFramework.close();
}
});
lines.print();
return jsc;
}
}
自己手动管理,offset, 如保存到zookeeper,mysql.当sparkstreamimg逻辑变化,代码修改后,可以从自己保存的位置在顺延消费数据。
