// 验证pipeline计算模式
val rdd1 = sc.parallelize(Array("zhangsan","lisi","wangwu"))
val rdd2 = rdd1.map(name=>{
println("***map " + name)
name + "~"
})
val rdd3 = rdd2.filter(name =>{
println("===filter " + name )
true
})
rdd3.collect()
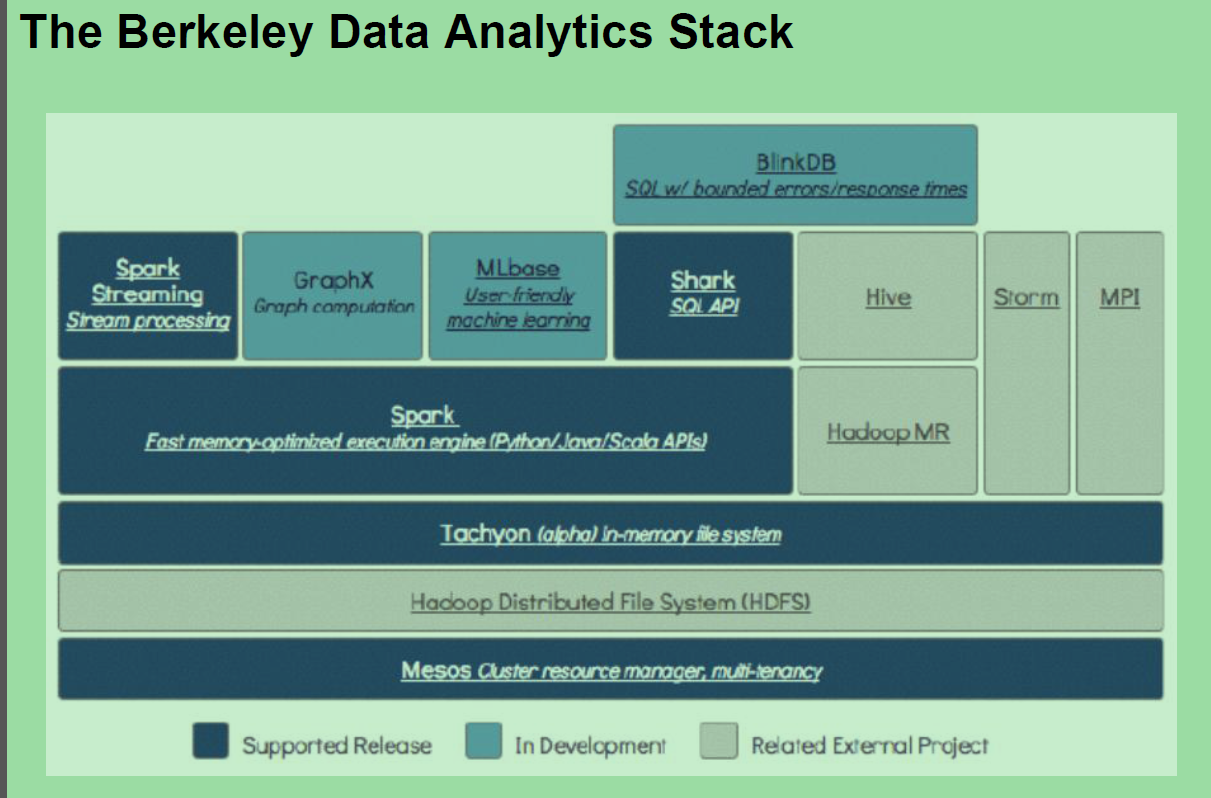
http://spark.apache.org/ RM spark 1:100 内存; 1:10磁盘。 DAG You can run Spark using its standalone cluster mode, on EC2, on Hadoop YARN, on Mesos, or on Kubernetes. Access data in HDFS, Alluxio, Apache Cassandra, Apache HBase, Apache Hive, and hundreds of other data sources. Mesos resilient 英 [rɪ'zɪlɪənt] 美 [rɪ'zɪlɪənt] adj. 弹回的,有弹力的 stom 流式处理, 数据在源源不断的输入,源源不断的产生。 spark streaming :流式处理 spark core : 批处理。 spark sql : 即席处理。(sql查询)
spark官方配置项 http://spark.apache.org/docs/latest/configuration.html
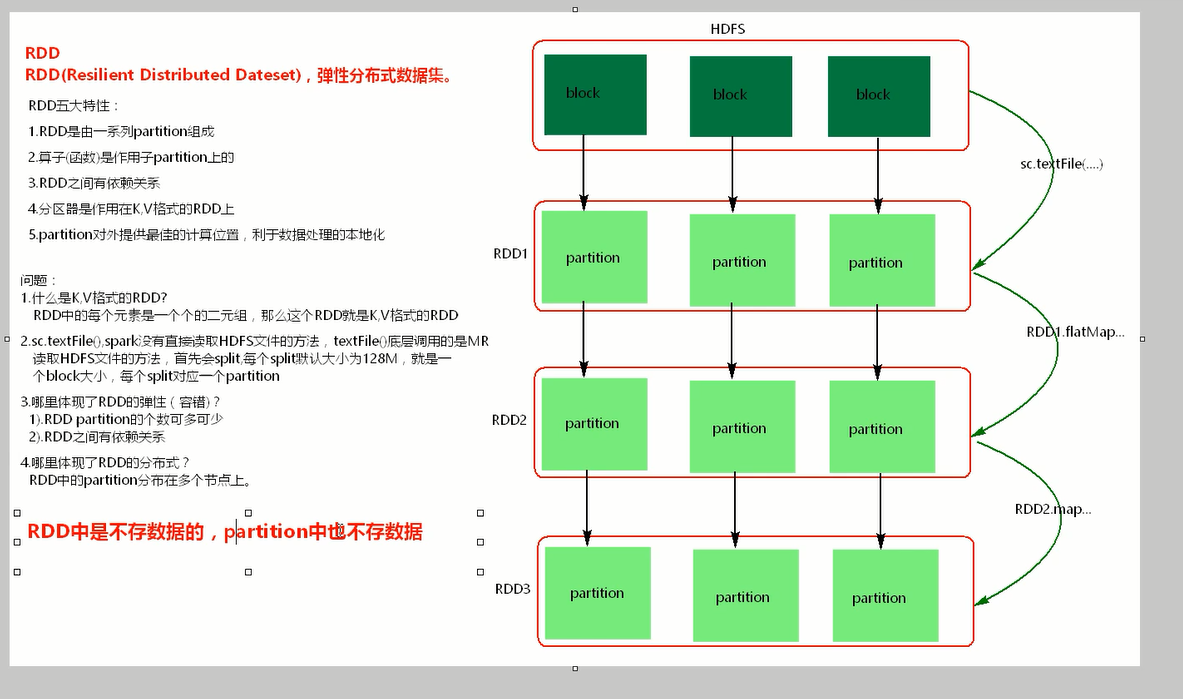
pair n. 一对,一双,一副 vt. 把…组成一对 RDD(Resilient Distributed Datasets) [1] ,弹性分布式数据集, 是分布式内存的一个抽象概念,RDD提供了一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,只能通过在其他RDD执行确定的转换操作(如map、join和group by)而创建,然而这些限制使得实现容错的开销很低。对开发者而言,RDD可以看作是Spark的一个对象,它本身运行于内存中,如读文件是一个RDD,对文件计算是一个RDD,结果集也是一个RDD ,不同的分片、 数据之间的依赖 、key-value类型的map数据都可以看做RDD。
## scala WC排序
package com.bjsxt.spark
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
object ScalaWordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("ScalaWordCount")
val sc = new SparkContext(conf)
val lines: RDD[String] = sc.textFile("src/words") // 一行行读取的
val words:RDD[String] = lines.flatMap(line =>{
line.split(" ")
})
val pairWords:RDD[(String, Int)] = words.map(word =>{
new Tuple2(word,1)
})
/**
* reduceByKey 先分组,后对每一组内的kye对应的value去聚合
*/
val reduce = pairWords.reduceByKey((v1:Int,v2:Int) => { v1 + v2 })
// val result = reduce.sortBy(tuple =>{tuple._2},false)
val reduce2:RDD[(Int, String)] = reduce.map(tuple=>{tuple.swap}); // string,int ==> int,string
// sortByKey 按key降序
val result = reduce2.sortByKey(false).map(_.swap);
result.foreach(tuple =>{println(tuple)})
sc.stop()
// 简化版
// val conf = new SparkConf().setMaster("local").setAppName("ScalaWordCount")
// new SparkContext(conf).textFile("src/words").flatMap(_.split(" ")).map((_,1)).reduceByKey(_ + _).foreach(println(_))
}
}
java spark WC 排序
package com.bjsxt.spark;
import java.util.Arrays;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import scala.Tuple2;
public class JavaSparkWorkCount {
public static void main(String[] args) {
/**
* conf
* 1.可以设置spark的运行环境,
* 2.可以设置spark在webui中显示的application的名称
* 3.可以设置当前spark application 运行的资源(内存+core:核心)
* 如4核8线程 与spark核不一样;可以最多提供给spark 8个core;spark的核只能跑一个task
* 物理机4核8线程;表示核双线程:表示某一时刻可以同时跑两个线程;不存在cpu争抢
*
*
* spark运行模式:
* 1.local --zai1eclipse,IDEA中开发spark程序要用local模式,本地模式,多用于测试
* 2.standlone -- spark 自带的资源调度框架,支持分布式搭建,Spark任务可以依赖standlone调度资源
* 3.yarn -- hadoop 生态圈中资源调度框架。Spark也可以基于yarn调度资源
* 4.mesos -- 资源调度框架
*/
SparkConf conf = new SparkConf();
conf.setMaster("local");
conf.setAppName("JavaSparkWorkCount");
conf.set("内存", "10G");
/**
* SparkContext 是通往集群的唯一通道
*/
JavaSparkContext sc = new JavaSparkContext(conf);
// 读取文件
JavaRDD<String> lines = sc.textFile("./words");
// 一对多;进来一条数据,出多条数据
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
/**
* FlatMapFunction<String, String> == line,word
*/
private static final long serialVersionUID = 1L;
@Override
public Iterable<String> call(String line) throws Exception {
return Arrays.asList(line.split(" "));
}
});
// 在java中如果想让某个RDD转换为K,V格式,使用xxxToPair
// K,V 格式的RDD:JavaPairRDD<String,Integer>
// JavaRDD<String> ==> JavaRDD<k,v>
JavaPairRDD<String,Integer> pairWords = words.mapToPair(new PairFunction<String, String, Integer>() {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String, Integer>(word, 1);
}
});
/**
* reduceByKey
* 1.先将相同的key分组
* 2.对每一组的key对应的value去按照你的逻辑去处理
*/
// <Integer, Integer, Integer> 进来一个,进来一个, 出去一个
JavaPairRDD<String, Integer> reduce = pairWords.reduceByKey(new Function2<Integer, Integer, Integer>() {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
// v1 v2 进来后返回给v1;再看有没有v3,如果有v3,v1(v1+v2)和v3进来。
return v1 + v2;
}
});
JavaPairRDD<Integer, String> mapToPair = reduce.mapToPair(new PairFunction<Tuple2<String,Integer>, Integer, String>() {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public Tuple2<Integer, String> call(Tuple2<String, Integer> tuple)
throws Exception {
// return new Tuple2<Integer, String>(tuple._2,tuple._1);
return tuple.swap();
}
});
JavaPairRDD<Integer,String> sortByKey = mapToPair.sortByKey(false);
JavaPairRDD<String,Integer> mapToPair2 = sortByKey.mapToPair(new PairFunction<Tuple2<Integer,String>, String, Integer>() {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, Integer> call(Tuple2<Integer, String> tuple)
throws Exception {
return tuple.swap();
}
});
mapToPair2.foreach(new VoidFunction<Tuple2<String,Integer>>() {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public void call(Tuple2<String, Integer> tuple) throws Exception {
System.out.println(tuple);
}
});
sc.stop();
}
}
lineage n. 血统;家系,[遗] 世系

heap n. 堆;许多;累积 vt. 堆;堆积 vi. 堆起来

序列化级别
MEMORY_ONLY : 只放在内存中,放不下,则全部放在磁盘
MEMORY_AND_DISK: 内存放不下,剩余部分放在磁盘
有向无环图,即Directed Acyclic Graph(DAG)
checkpoint: 将rdd数据存储到disk;切断与前边的rdd的依赖。app运行完之后checkpoint数据还存在(persist则没有了);某些特定场景必须用checkpoint
优化 : checkpoint 之前先cache一下。
算子分类:
transformation,cache persist ,checkpoint
package com.bjsxt.spark;
import java.util.List;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
public class TransformationTest {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setMaster("local");
conf.setAppName("JavaSparkWorkCount");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> lines = sc.textFile("./words");
// List<String> collect = lines.collect();
// String first = lines.first();
//
// List<String> take = lines.take(5);
// for (String string : take) {
// System.out.println(string);
// }
// JavaRDD<String> sample = lines.sample(true, 0.1);
sc.stop();
}
}
package com.bjsxt.spark
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
object TransformationsTest {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("test")
val sc = new SparkContext(conf)
val lines = sc.textFile("./words")
val result:Array[String] = lines.take(5) // 取前5行
result.foreach { println }
// val result = lines.first() // 取第一行
// println(result)
// collect foreach count 会将结果回收到driver端,数据太多会出现outOfMemory
// val result:Array[String] = lines.collect();
// result.foreach { println }
// val count = lines.count
// println(count)
// lines.filter ( s => {
// s.equals("hello spark")
// }).foreach(println)
/**
* sample 随机抽样
* true 表示是否放回取出的数据
* 0.1抽样的比例
*
* 100 seed:Long类型的中字,针对的同一批数据,只要种子相同,每次抽样的数据结果一样。
*/
// val result = lines.sample(true, 0.1,100)
// result.foreach(println)
sc.stop()
}
}
package com.bjsxt.spark
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.rdd.RDD
/**
* 持久化算子
* cache() 默认将RDD中的数据存在内存中,懒执行算子 ;需要Action算子触发执行。
* persist() 可以手动指定持久化级别;懒执行;需要Action算子触发执行。
* rdd.persist(StorageLevel.MEMORY_ONLY) = cache() = persist()
*
*
* cache 和persist注意:
* 1.cache和persist 都是懒执行,需要Action算子触发执行。
* 2.对一个RDD cache 或者persist之后可以复制给一个变量,下次直接使用这个变量就是使用持久化的rdd
* 3.如果复制给一个变量,那么cache和persist之后不能紧跟Action算子。
rdd.cache().collect() 紧跟
rdd.cache() 不紧跟
rdd.collect()
cache persist checkpoint 持久化的单位都是partition
*/
object Cache {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("cacheTest")
val sc = new SparkContext(conf)
sc.setCheckpointDir("./checkpoint")
val rdd = sc.textFile("./words")
rdd.checkpoint()
rdd.collect();
// val conf = new SparkConf().setMaster("local").setAppName("cacheTest")
// val sc = new SparkContext(conf)
//
// // disk RAM 差别
// val rdd:RDD[String] = sc.textFile("./NASA_access_log_Aug95")
//
// rdd.cache() // rdd = rdd.cache()
// rdd.persist(StorageLevel.MEMORY_ONLY)
// val st1 = System.currentTimeMillis();
//
// val rt1 = rdd.count()
//
// val et1 = System.currentTimeMillis();
//
// println("spendTime:" + (et1 - st1))
//
// val st2 = System.currentTimeMillis();
//
// val rt2 = rdd.count()
//
// val et2 = System.currentTimeMillis();
//
// println("spendTime:" + (et2 - st2))
}
}
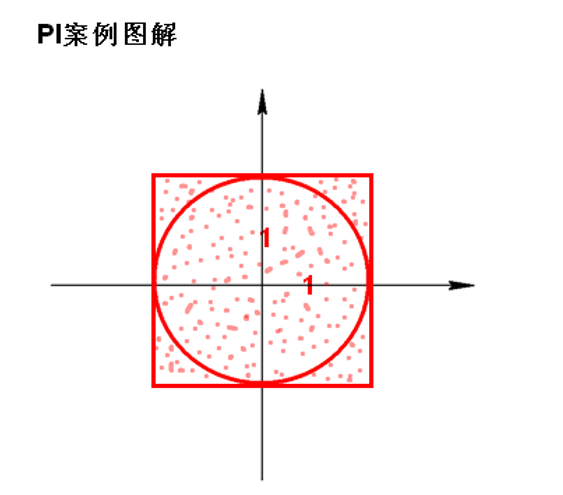
spark 集群搭建 node1 master node2,node3 worker node1: tar -zxvf spark-1.6.0-bin-hadoop2.6.tgz -C /opt/sxt/ cd /opt/sxt/ mv spark-1.6.0-bin-hadoop2.6 spark-1.6.0 cd spark-1.6.0/conf/ cp slaves.template slaves [root@node1 conf]# cat slaves node2 node3 [root@node1 conf]# cat spark-env.sh | grep export export JAVA_HOME=/usr/java/jdk1.8.0_221 export SPARK_MASTER_IP=node1 export SPARK_MASTER_PORT=7077 export SPARK_WORKER_CORES=2 export SPARK_WORKER_MEMORY=3g scp -r spark-1.6.0 node2:`pwd` scp -r spark-1.6.0 node3:`pwd` cd ./sbin/ ./start-all.sh ## 启动集群 jps node1 master ,node2,3 worker http://node1:8080/ 查看集群(默认端口) 修改ui端口 [root@node1 bin]# cat ../conf/spark-env.sh | grep export export JAVA_HOME=/usr/java/jdk1.8.0_221 export SPARK_MASTER_IP=node1 export SPARK_MASTER_PORT=7077 export SPARK_WORKER_CORES=2 export SPARK_WORKER_MEMORY=3g export SPARK_MASTER_WEBUI_PORT=8888 ./sbin/stop-all.sh ./sbin/start-all.sh http://node1:8888/ 查看集群 ----------------------集群启动成功 计算example Pi spark-1.6.0/lib下已经存在example. bin/spark-submit 查看帮助 Options: --master MASTER_URL spark://host:port, mesos://host:port, yarn, or local. ... ./spark-submit --master spark://node1:7077 --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 100 ## 源码为正方形与圆的随机打点的命中率的面积比。
// 将集合转换为rdd ; 2是分区个数
val rdd = sc.parallelize(Array(1,2,3,4),2);
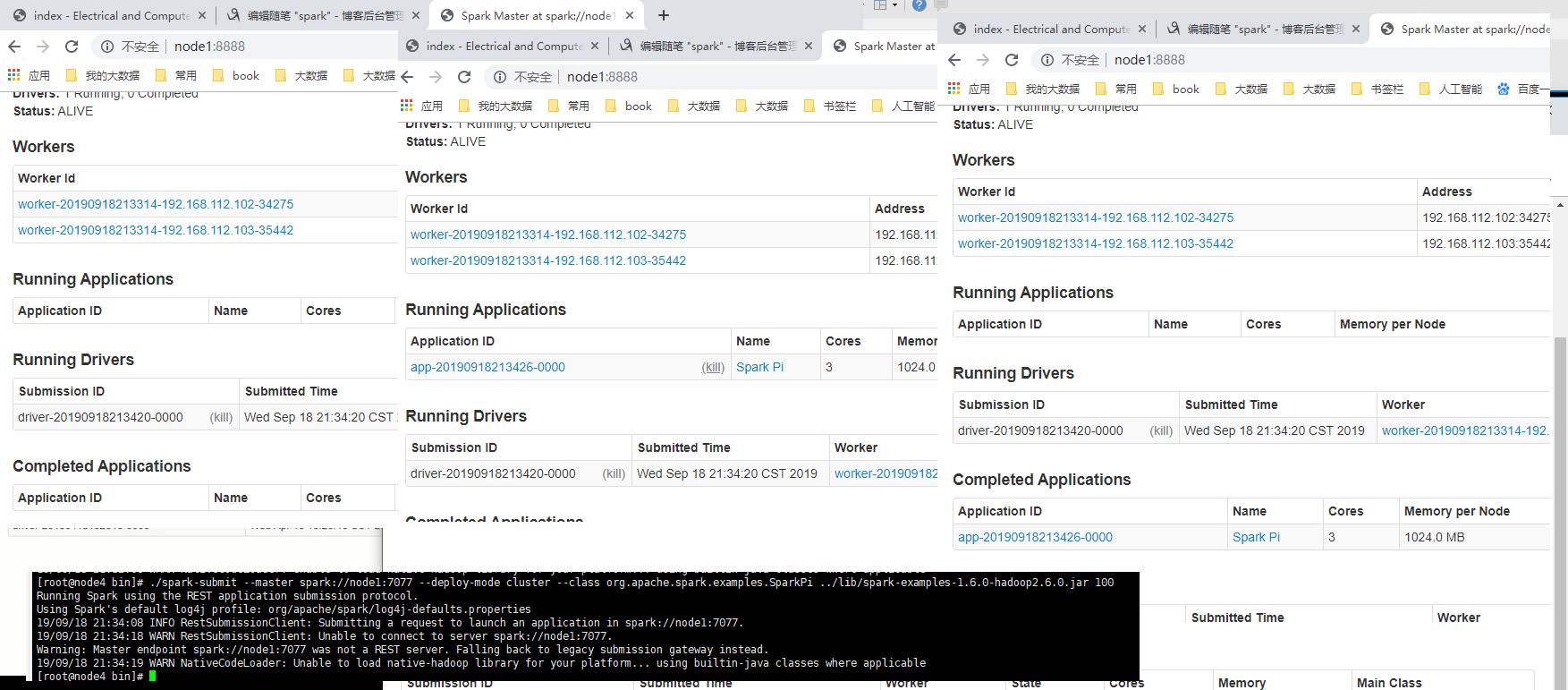
node4 部署单独的提交任务客户端 [root@node2 sxt]# scp -r spark-1.6.0 node4:`pwd` ./sbin/ rm slaves spark-env.sh ./bin/ ./spark-submit --master spark://node1:7077 --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 100

standalone-client [root@node4 bin]# pwd /opt/sxt/spark-1.6.0/bin [root@node4 bin]# ./spark-submit --master spark://node1:7077 --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 100 默认是client [root@node4 bin]# ./spark-submit --master spark://node1:7077 --deploy-mode client --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 100 在客户端可以看到task运行的日志 cluster [root@node4 bin]# ./spark-submit --master spark://node1:7077 --deploy-mode cluster --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 100 在客户端看不到task运行的日志
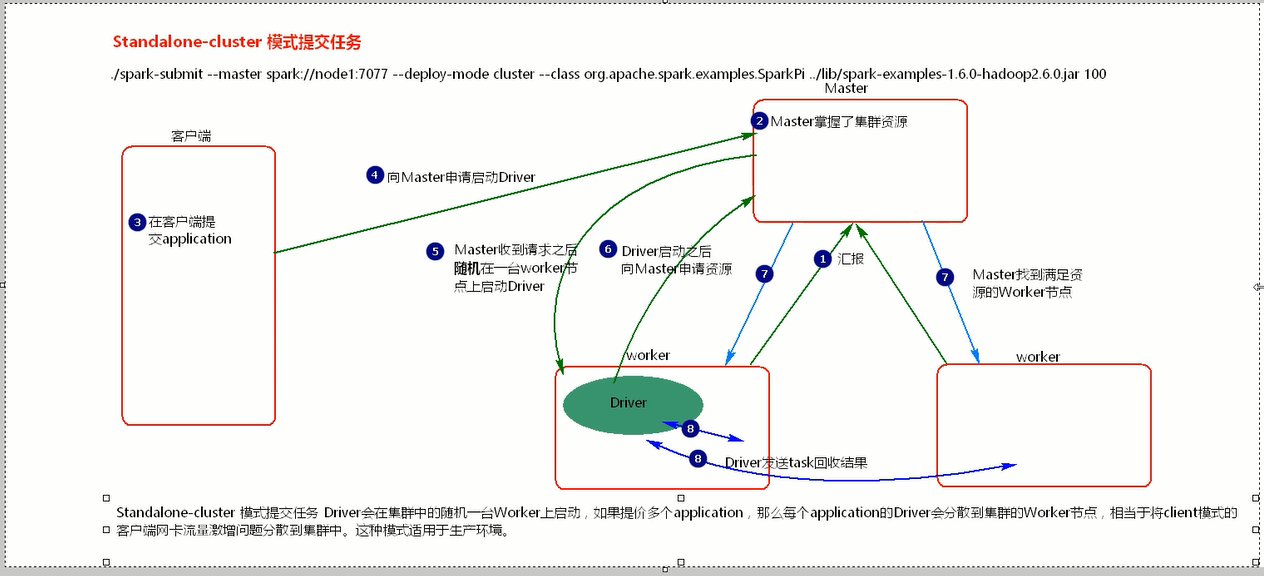
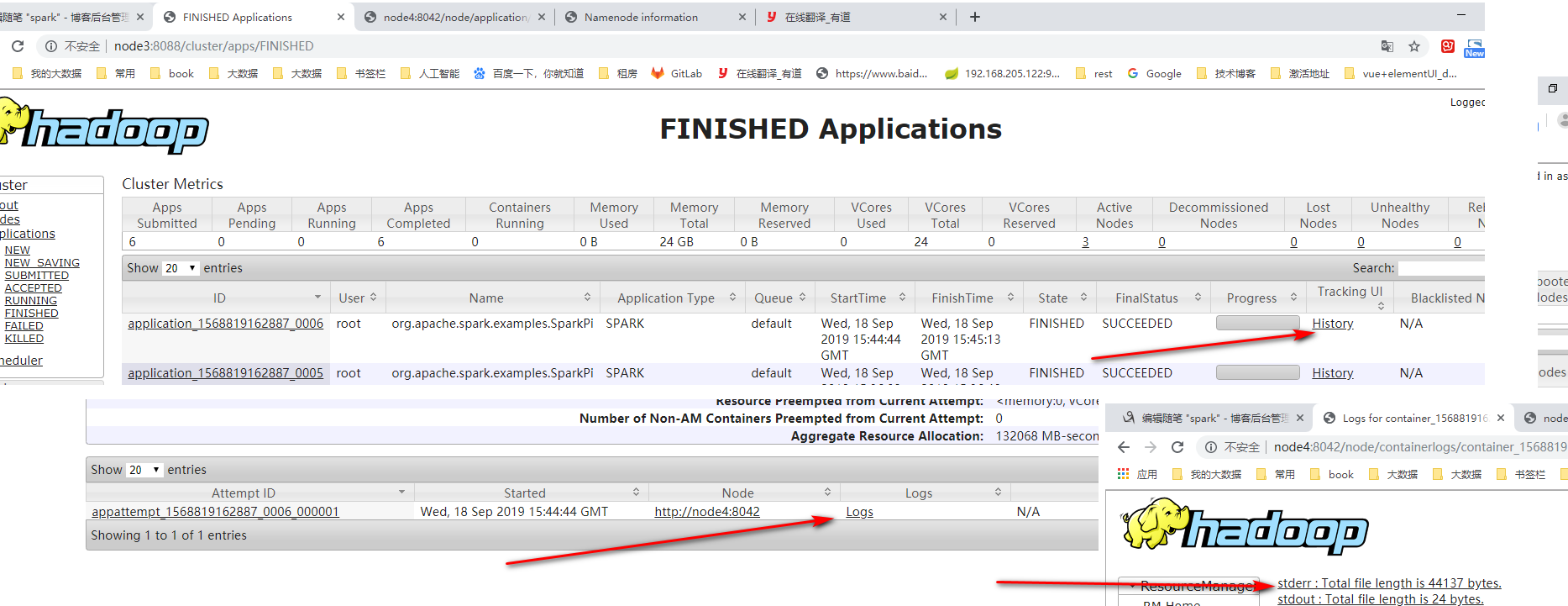
ctandalone-cluster模式提交任务
bash下 sparksubmit,运行一会儿自动退出,看不到task的日志。
spark webui 效果 dirver ,(dirver application ). complete

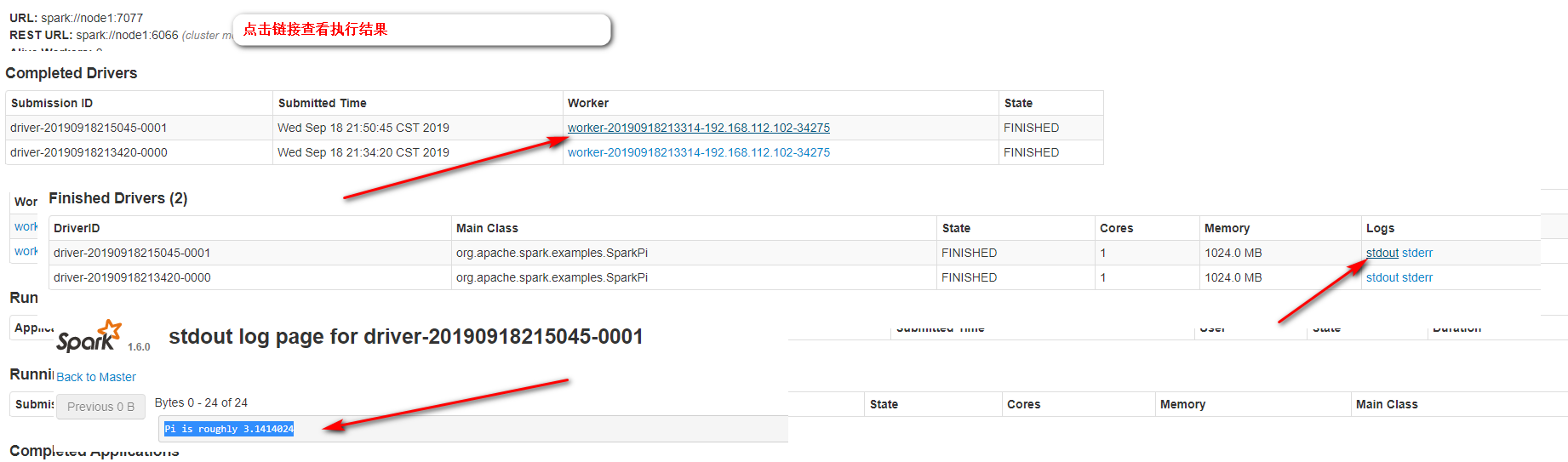
[root@node1 shells]# ./stop-spark.sh ## 先停掉spark. 表示yarn和standalone spark 没有关系
node2,3,4 /opt/sxt/zookeeper-3.4.6/bin/zkServer.sh start node1 [root@node1 shells]# start-dfs.sh [root@node1 shells]# ./start-yarn-ha.sh [root@node1 shells]# cat start-yarn-ha.sh start-yarn.sh ssh root@node3 "$HADOOP_HOME/sbin/yarn-daemon.sh start resourcemanager" ssh root@node4 "$HADOOP_HOME/sbin/yarn-daemon.sh start resourcemanager" yarn webui: http://node3:8088/cluster/nodes hdfs webui: http://node1:50070/explorer.html#/ [root@node4 conf]# pwd /opt/sxt/spark-1.6.0/conf [root@node4 conf]# cat spark-env.sh | grep export export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop ## 执行yarn-client 提交 [root@node4 bin]# ./spark-submit --master yarn --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 1000 ## 报错: .SparkException: Yarn application has already ended! webui log===》》ERROR yarn.ApplicationMaster: RECEIVED SIGNAL 15: SIGTERM ## 修改hadoop yarn-site.xml配置 增加: <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> ## 重启yarn 重新运行./spark-submit --master yarn --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 1000 执行成功。 ## 在客户端可以看到任务的执行和结果 ./spark-submit --master yarn | ./spark-submit --master yarn-client | ./spark-submit --master yarn --deploy-mode client ## 三种前缀都是yarn-client提交。
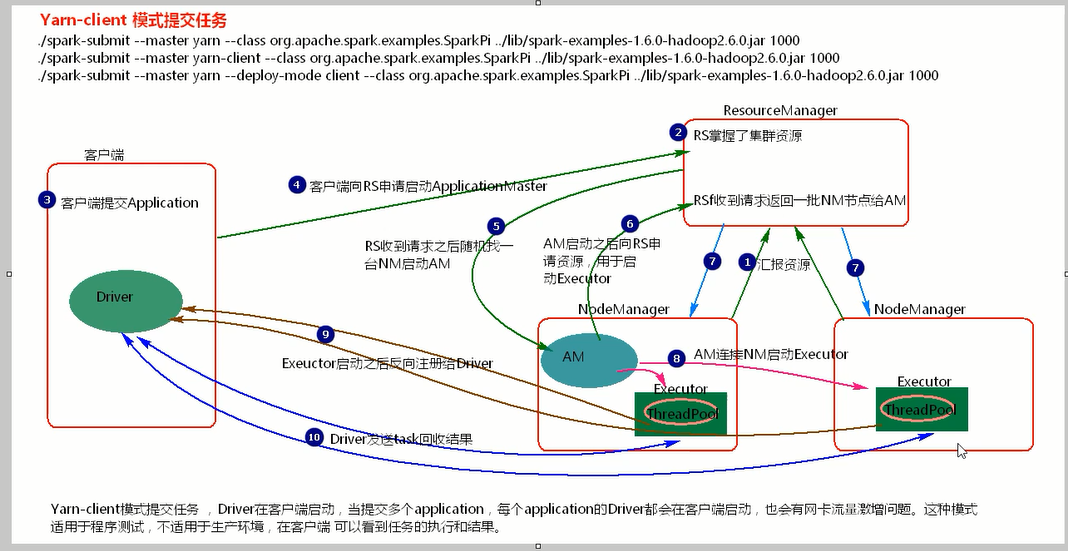
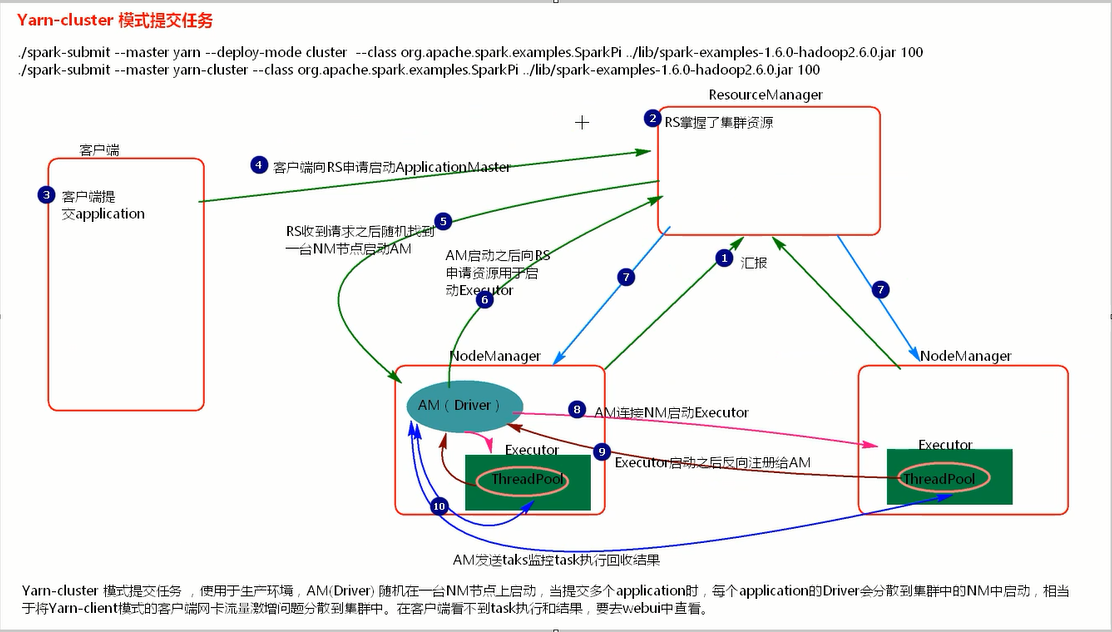
[root@node4 bin]# ./spark-submit --master yarn --deploy-mode cluster --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 100 [root@node4 bin]# ./spark-submit --master yarn-cluster --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 100
package com.bjsxt.spark;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.sql.functions;
import com.google.common.base.Optional;
import scala.Tuple2;
public class Day02 {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setMaster("local").setAppName("test");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> rdd = sc.parallelize(Arrays.asList("a","a","b","b","b","c","dg"));
JavaPairRDD<String,Integer> mapToPair = rdd.mapToPair(new PairFunction<String, String, Integer>( ) {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, Integer> call(String s) throws Exception {
// TODO Auto-generated method stub
return new Tuple2<String,Integer>(s,1);
}
});
JavaPairRDD<String,Integer> reduceByKey = mapToPair.reduceByKey(new Function2<Integer, Integer, Integer>() {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
// TODO Auto-generated method stub
return v1 + v2;
}
});
JavaRDD<String> map = reduceByKey.map(new Function<Tuple2<String,Integer>, String>() {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public String call(Tuple2<String, Integer> tuple) throws Exception {
// TODO Auto-generated method stub
return tuple._1;
}
});
map.foreach(new VoidFunction<String>() {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public void call(String arg0) throws Exception {
System.out.println(arg0);
}
});
JavaRDD<String> distinct = rdd.distinct();
distinct.foreach(new VoidFunction<String>() {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public void call(String arg0) throws Exception {
System.out.println(arg0);
}
});
/**
* foreachPartition 一个分区一个分区的执行,不会返回数据
*/
// rdd.foreachPartition(new VoidFunction<Iterator<String>>() {
//
// /**
// *
// */
// private static final long serialVersionUID = 1L;
//
// @Override
// public void call(Iterator<String> iter) throws Exception {
// List<String> list = new ArrayList<>();
//
// System.out.println("创建数据库连接......");
// while(iter.hasNext()){
// String s = iter.next();
// System.out.println("拼接sql....");
// list.add(s);
// }
//
// }
// });
/**
* foreach 一条条处理数据
*/
// rdd.foreach(new VoidFunction<String>() {
//
// /**
// *
// */
// private static final long serialVersionUID = 1L;
//
// @Override
// public void call(String s) throws Exception {
// System.out.println("创建数据库连接。。。。。");
// System.out.println("插入数据库连接。。。。。" + s);
// System.out.println("关闭数据库连接。。。。。");
//
// }
// });
/**
* mappartition
*/
// rdd.mapPartitions(new FlatMapFunction<Iterator<String>, String>() {
//
// /**
// *
// */
// private static final long serialVersionUID = 1L;
//
// @Override
// public Iterable<String> call(Iterator<String> iter)
// throws Exception {
// List<String> list = new ArrayList<>();
//
// System.out.println("创建数据库连接......");
// while(iter.hasNext()){
// String s = iter.next();
// System.out.println("拼接sql....");
// list.add(s);
// }
//
// return list;
// }
// }).collect();
// JavaRDD<String> map = rdd.map(new Function<String, String>() {
//
// /**
// *
// */
// private static final long serialVersionUID = 1L;
//
// @Override
// public String call(String s) throws Exception {
// System.out.println("创建数据库连接。。。。。");
// System.out.println("插入数据库连接。。。。。" + s);
// System.out.println("关闭数据库连接。。。。。");
//
// return s + "~";
// }
// });
// map.collect();
// JavaPairRDD<String,String> rdd1 = sc.parallelizePairs(Arrays.asList(
// new Tuple2<String,String>("zhangsan","a"),
// new Tuple2<String,String>("zhangsan","aa"),
// new Tuple2<String,String>("zhangsan","aaa"),
// new Tuple2<String,String>("lisi","b"),
// new Tuple2<String,String>("lisi","bb"),
// new Tuple2<String,String>("wangwu","c")
// ));
//
//
// JavaPairRDD<String,String> rdd2 = sc.parallelizePairs(Arrays.asList(
// new Tuple2<String,String>("zhangsan","10000"),
// new Tuple2<String,String>("lisi","1"),
// new Tuple2<String,String>("lisi","10"),
// new Tuple2<String,String>("lisi","1000"),
// new Tuple2<String,String>("wangwu","3"),
// new Tuple2<String,String>("wangwu","30"),
// new Tuple2<String,String>("zhaoliu","200")
// ));
//
// /**
// * cogroup 将两个RDD的key合并,每个rdd总的key对应一个集合
// */
// JavaPairRDD<String,Tuple2<Iterable<String>,Iterable<String>>> cogroup = rdd1.cogroup(rdd2);
// cogroup.foreach(new VoidFunction<Tuple2<String,Tuple2<Iterable<String>,Iterable<String>>>>() {
//
// /**
// *
// */
// private static final long serialVersionUID = 1L;
//
// @Override
// public void call(
// Tuple2<String, Tuple2<Iterable<String>, Iterable<String>>> arg0)
// throws Exception {
// System.out.println(arg0);
// // (zhangsan,([a, aa, aaa],[10000])) ...
//
// }
// });
/**
* subtrack 取差集
*/
// JavaPairRDD<String,String> subtract = rdd1.subtract(rdd2);
//
// subtract.foreach(new VoidFunction<Tuple2<String,String>>() {
//
// /**
// *
// */
// private static final long serialVersionUID = 1L;
//
// @Override
// public void call(Tuple2<String, String> arg0) throws Exception {
// System.out.println(arg0);
//
// }
// });
/**
* intersection 取交集
*/
// JavaPairRDD<String,String> intersection = rdd1.intersection(rdd2);
// intersection.foreach(new VoidFunction<Tuple2<String,String>>() {
//
// /**
// *
// */
// private static final long serialVersionUID = 1L;
//
// @Override
// public void call(Tuple2<String, String> arg0) throws Exception {
// System.out.println(arg0);
//
// }
// });
// 如下才是k,v格式rdd
// JavaPairRDD<String,String> rdd1 = sc.parallelizePairs(Arrays.asList(
// new Tuple2<String,String>("zhangsan","a"),
// new Tuple2<String,String>("lisi","b"),
// new Tuple2<String,String>("wangwu","c"),
// new Tuple2<String,String>("zhaoliu","d")
// ),3);
//
//
// JavaPairRDD<String,Integer> rdd2 = sc.parallelizePairs(Arrays.asList(
// new Tuple2<String,Integer>("zhangsan",2),
// new Tuple2<String,Integer>("lisi",3),
// new Tuple2<String,Integer>("wangwu",4),
// new Tuple2<String,Integer>("tianqi",5)
// ),2);
// JavaPairRDD<String,String> rdd3 = sc.parallelizePairs(Arrays.asList(
// new Tuple2<String,String>("zhangsan1","a"),
// new Tuple2<String,String>("lisi1","b"),
// new Tuple2<String,String>("wangwu1","c"),
// new Tuple2<String,String>("zhaoliu1","d")
// ),3);
//
// /**
// * union 合并rdd,类型必须一致
// */
// JavaPairRDD<String,String> union = rdd1.union(rdd3);
//
// // 分区数是两个父分区的和
// System.out.println("join.partitions().size = " + union.partitions().size());
//
// union.foreach(new VoidFunction<Tuple2<String,String>>() {
//
// /**
// *
// */
// private static final long serialVersionUID = 1L;
//
// @Override
// public void call(Tuple2<String, String> arg0) throws Exception {
// System.out.println(arg0);
//
// }
// });
/**
* join
* 按照两个rdd的key去关联
*/
// 分区与父分区多的rdd一致
// JavaPairRDD<String,Tuple2<String,Integer>> join = rdd1.join(rdd2);
//
//
// System.out.println("join.partitions().size = " + join.partitions().size());
// join.foreach(new VoidFunction<Tuple2<String,Tuple2<String,Integer>>>() {
//
// /**
// *
// */
// private static final long serialVersionUID = 1L;
//
// @Override
// public void call(Tuple2<String, Tuple2<String, Integer>> arg0)
// throws Exception {
// System.out.println(arg0);
//
// }
// });
// JavaPairRDD<String,Tuple2<Optional<String>,Optional<Integer>>> fullOuterJoin = rdd1.fullOuterJoin(rdd2);
// JavaPairRDD<String,Tuple2<Optional<String>,Integer>> rightOuterJoin = rdd1.rightOuterJoin(rdd2);
// JavaPairRDD<String,Tuple2<String,Integer>> join = rdd1.join(rdd2);
//
//
// /**
// * leftOuterJoin
// */
// JavaPairRDD<String,Tuple2<String,Optional<Integer>>> leftOuterJoin = rdd1.leftOuterJoin(rdd2);
//
//
// leftOuterJoin.foreach(new VoidFunction<Tuple2<String,Tuple2<String,Optional<Integer>>>>() {
//
// /**
// *
// */
// private static final long serialVersionUID = 1L;
//
// @Override
// public void call(
// Tuple2<String, Tuple2<String, Optional<Integer>>> tuple)
// throws Exception {
// String key = tuple._1;
// String value1 = tuple._2._1;
// Optional<Integer> option = tuple._2._2;
// if(option.isPresent()){
// System.out.println("key=" + key + ", valu1=" +value1 + ", option=" + option.get());
// }else{
// System.out.println("key=" + key + ", valu1=" +value1 + ", option=" );
// }
//
// }
// });
// 如下不是k v的 rdd
// JavaRDD<Tuple2<String,String>> parallelize = sc.parallelize(Arrays.asList(
// new Tuple2<String,String>("zhangsan","a"),
// new Tuple2<String,String>("lisi","b"),
// new Tuple2<String,String>("wangwu","c")
// ),2);
// // 如下才是k,v格式rdd
// JavaPairRDD<String,String> parallelizePairs = sc.parallelizePairs(Arrays.asList(
// new Tuple2<String,String>("zhangsan","a"),
// new Tuple2<String,String>("lisi","b"),
// new Tuple2<String,String>("wangwu","c")
// ),2);
// List<String> asList = Arrays.asList("a","b","c","d","e","f");
// JavaRDD<String> rdd = sc.parallelize(asList); // local 一个分区
// JavaRDD<String> rdd = sc.parallelize(asList,4); // 4个分区
//
// System.out.println("rdd partition length=" + rdd.partitions().size());
// List<String> collect = rdd.collect();
sc.stop();
sc.close();
}
}
package com.bjsxt.spark
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
object Day02 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("test")
val sc = new SparkContext(conf)
val rdd1 = sc.makeRDD( List(
("zhangsan",18),("lisi",19),("wangwu",20),("maliu",21),("lisi",19),("wangwu",20)))
rdd1.foreachPartition(iter =>{
println("插入数据库....")
})
// rdd1.mapPartitions(iter=>{
// println("插入数据库....")
// iter
// },true).collect() // true 分区器与父rdd保持一致
// rdd1.distinct().foreach(println)
// val rdd2 = sc.makeRDD( Array( ("zhangsan",18),("lisi",19),("wangwu",20),("maliu",21)),3)
// rdd1.intersection(rdd2).foreach(println)
// rdd1.subtract(rdd2).foreach(println)
// val result = rdd1.union(rdd2);
// val result = rdd1.leftOuterJoin(rdd2);
// val result = rdd1.rightOuterJoin(rdd2);
// val result = rdd1.join(rdd2);
// result.foreach(println)
sc.stop()
}
}


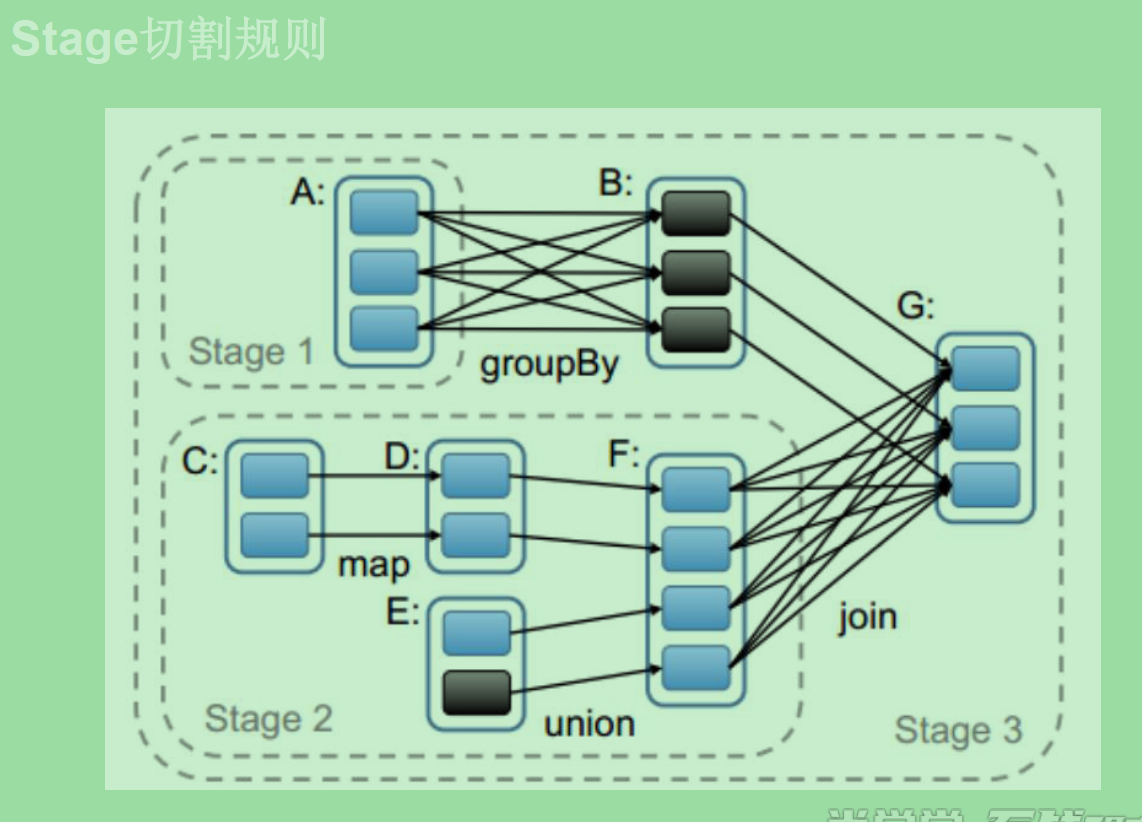
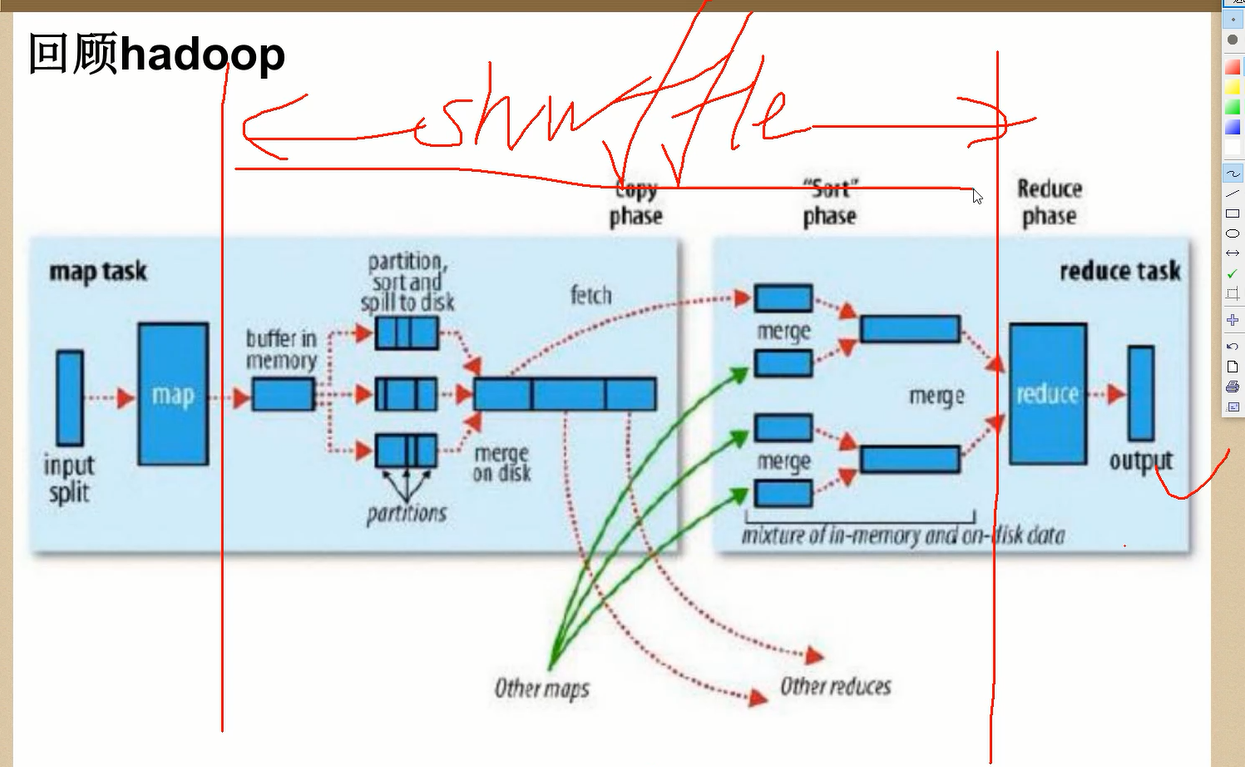
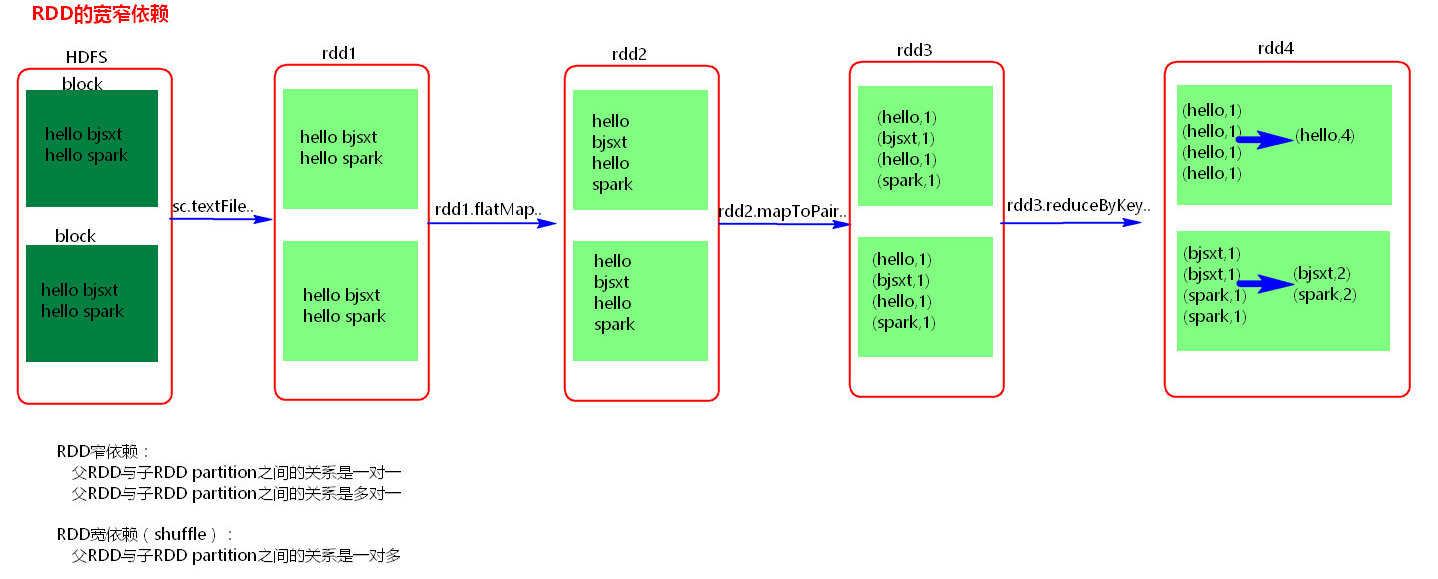
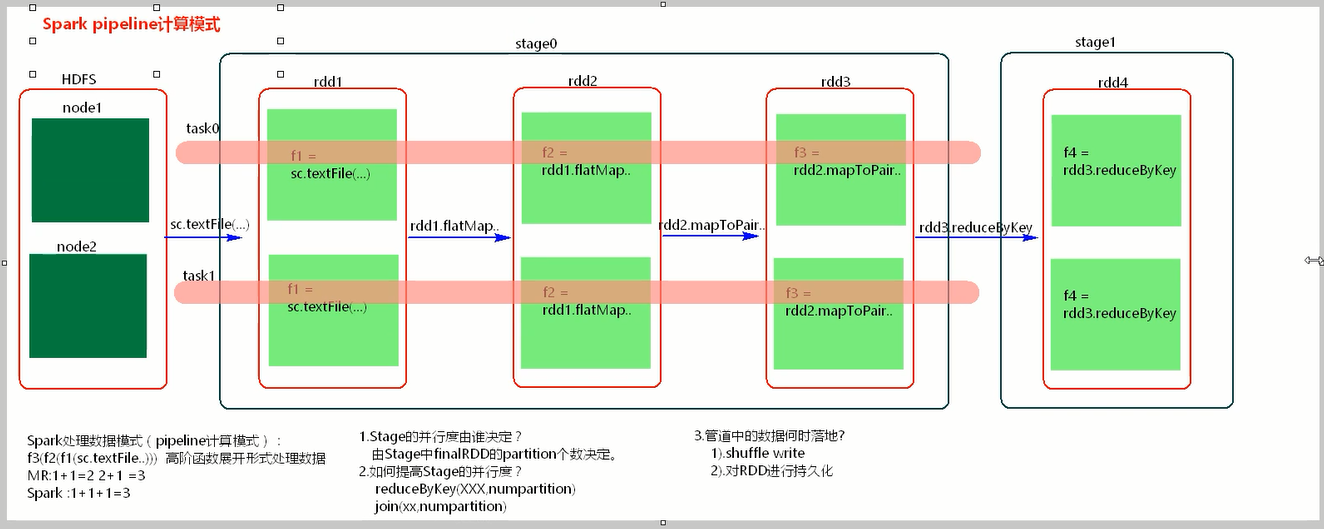
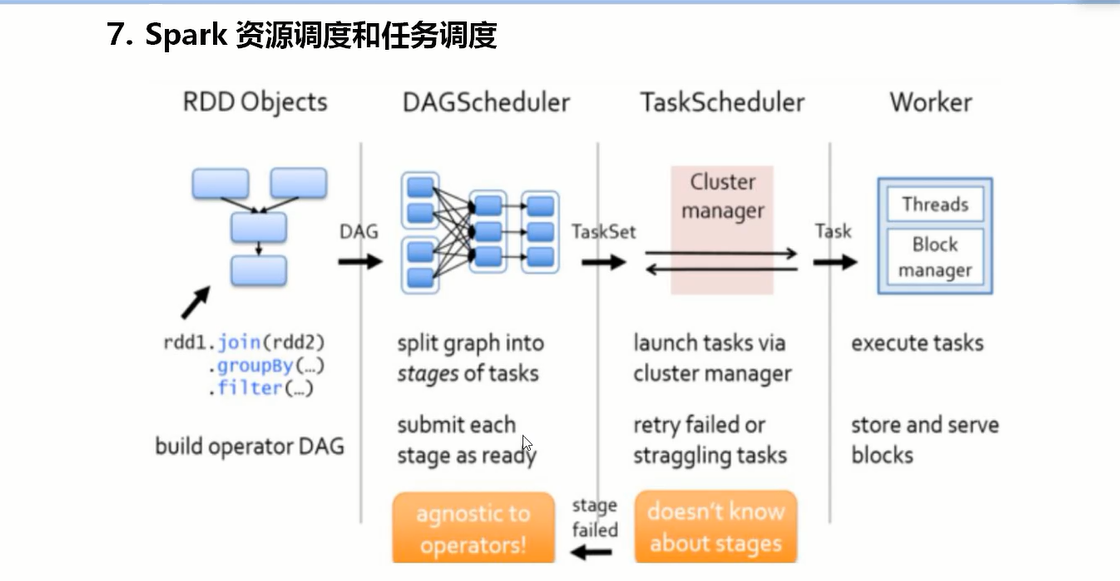
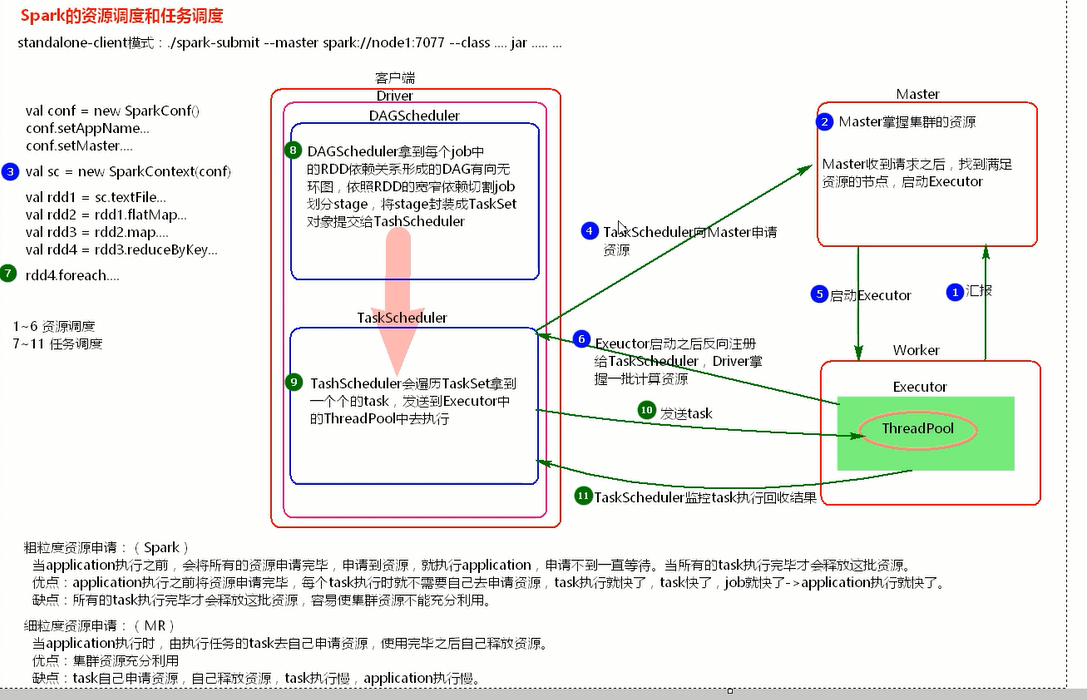
stage 切割的原理是遇到宽依赖切一刀。 rdd依赖关系形成DAG 某一个stage内是基于内存处理的。 stage是一组并行的task组成。
application中的job个数是action算子的个数。
straggling
美 ['strægl]
- v. 杂乱地蔓延;落伍(straggle 的现在分词)
- adj. 凌乱的
推测执行机制:默认是关闭的(spark任务慢,启动新线程从头执行);对于ELT数据入库,不能开启此机制,避免数据重复。
package com.bjsxt.spark;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function2;
public class Day03 {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setMaster("local").setAppName("day03test");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> rdd1 = sc.parallelize(Arrays.asList(
"local","local2","local3","local4",
"local5","local6","local7","local8",
"local9","local10","local11","local12"
),3);
/**
* mapPartitionsWithIndex
* 分区索引下标 Index 输入的数据, 返回的数据
* <Integer, Iterator<String>, Iterator<String>
*/
JavaRDD<String> mapPartitionsWithIndex = rdd1.mapPartitionsWithIndex(new Function2<Integer, Iterator<String>, Iterator<String>>() {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public Iterator<String> call(Integer index, Iterator<String> iter)
throws Exception {
List<String> list = new ArrayList<>();
while(iter.hasNext()){
String one = iter.next();
// System.out.println("partition index = 【" + index + "】, 【value =" + one + "】");
list.add("partition index = 【" + index + "】, 【value =" + one + "】");
}
return list.iterator();
}
}, true);
/**
* repartition 是有shuffle的算子,可以对rdd重新分区,可以增加分区,也可以减少分区。
* repartition = coalesce(numPartitions,true)
*/
// JavaRDD<String> repartition = mapPartitionsWithIndex.repartition(4);
// JavaRDD<String> repartition = mapPartitionsWithIndex.repartition(2);
/**'coalesce 与repartition一样,可以对rdd进行分区,可以增多分区,也可以减少分区。
* coalsece(slice,shuffle [Boolean=false]) false 不产生shuffle
*/
JavaRDD<String> rdd2 = mapPartitionsWithIndex.coalesce(4,false);
System.out.println("rdd1 partition length = " + rdd2.partitions().size());
JavaRDD<String> mapPartitionsWithIndex2 = rdd2.mapPartitionsWithIndex(new Function2<Integer, Iterator<String>, Iterator<String>>() {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public Iterator<String> call(Integer index, Iterator<String> iter)
throws Exception {
List<String> list = new ArrayList<>();
while(iter.hasNext()){
String one = iter.next();
// System.out.println("partition index = 【" + index + "】, 【value =" + one + "】");
list.add("rdd2 partition index = 【" + index + "】, 【value =" + one + "】");
}
return list.iterator();
}
}, true);
// System.out.println("rdd1 partition length = " + rdd1.partitions().size());
List<String> collect = mapPartitionsWithIndex2.collect();
for (String string : collect) {
System.out.println(string);
}
sc.stop();
}
}
package com.bjsxt.spark;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Map.Entry;
import java.util.Set;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.VoidFunction;
import scala.Tuple2;
public class Day03Transformation {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setMaster("local").setAppName("day03test");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaPairRDD<String, String> rdd1 = sc.parallelizePairs(Arrays.asList(
new Tuple2<String, String>("zhangsan", "18"),
new Tuple2<String, String>("zhangsan", "18"),
new Tuple2<String, String>("lisi", "190"),
new Tuple2<String, String>("lisi", "190"),
new Tuple2<String, String>("wangwu", "100"),
new Tuple2<String, String>("wangwu", "100")
));
/**
* countByValue
*/
Map<Tuple2<String, String>, Long> countByValue = rdd1.countByValue();
Set<Entry<Tuple2<String,String>,Long>> entrySet = countByValue.entrySet();
for (Entry<Tuple2<String, String>, Long> entry : entrySet) {
System.out.println(entry.getKey() + ":" + entry.getValue());
}
// /**
// * countByKey
// * Action算子 对RDD中相同的key的元素计数
// */
// Map<String, Object> countByKey = rdd1.countByKey();
//
// Set<Entry<String,Object>> entrySet = countByKey.entrySet();
//
// for (Entry<String, Object> entry : entrySet) {
// System.out.println(entry.getKey() + " :" + entry.getValue());
// }
/**
* reduce Action算子 对RDD中的每个元素使用传递的逻辑去处理
*/
// JavaRDD<Integer> rdd2 = sc.parallelize(Arrays.asList(1,2,3,4,5));
// Integer reduce = rdd2.reduce(new Function2<Integer, Integer, Integer>() {
//
// /**
// *
// */
// private static final long serialVersionUID = 1L;
//
// @Override
// public Integer call(Integer v1, Integer v2) throws Exception {
// // TODO Auto-generated method stub
// return v1 + v2;
// }
// });
// System.out.println(reduce);
/**
* zipzipWithIndex
* 给RDD中的每个元素与当前元素的下标压缩成一个K,V格式的RDD
*/
// JavaPairRDD<Tuple2<String,String>,Long> zipWithIndex = rdd1.zipWithIndex();
// zipWithIndex.foreach(new VoidFunction<Tuple2<Tuple2<String,String>,Long>>() {
//
// /**
// *
// */
// private static final long serialVersionUID = 1L;
//
// @Override
// public void call(Tuple2<Tuple2<String, String>, Long> arg0)
// throws Exception {
// System.out.println(arg0);
//
// }
// });
// JavaPairRDD<String, Integer> rdd2 = sc.parallelizePairs(Arrays.asList(
// new Tuple2<String, Integer>("zhangsan", 100),
// new Tuple2<String, Integer>("zhangsan",200),
// new Tuple2<String, Integer>("lisi", 300),
// new Tuple2<String, Integer>("lisi", 400),
// new Tuple2<String, Integer>("wangwu", 500),
// new Tuple2<String, Integer>("wangwu", 600)
// ));
//
// /**
// * zip 将两个RDD压缩成一个K,V格式RDD
// * 两个RDD中每个分区的数据要一致
// */
// JavaPairRDD<Tuple2<String,String>,Tuple2<String,Integer>> zip = rdd1.zip(rdd2);
//
// zip.foreach(new VoidFunction<Tuple2<Tuple2<String,String>,Tuple2<String,Integer>>>() {
//
// /**
// *
// */
// private static final long serialVersionUID = 1L;
//
// @Override
// public void call(
// Tuple2<Tuple2<String, String>, Tuple2<String, Integer>> arg0)
// throws Exception {
// System.out.println(arg0);
//
// }
// });
//
/**
* groupByKey
* 将RDD中相同的key分组
*/
// JavaPairRDD<String,Iterable<String>> groupByKey = parallelizePairs.groupByKey();
//
//
// groupByKey.foreach(new VoidFunction<Tuple2<String,Iterable<String>>>() {
//
// /**
// *
// */
// private static final long serialVersionUID = 1L;
//
// @Override
// public void call(Tuple2<String, Iterable<String>> arg0) throws Exception {
//
// System.out.println(arg0);
//
// }
// });
sc.stop();
}
}
package com.bjsxt.spark
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import scala.collection.mutable.ListBuffer
object Day02Transformation {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("day02test")
val sc = new SparkContext(conf)
val rdd1 = sc.parallelize(List(
(1,"a"),(2,"b"),(3,"c"),(3,"d")), 2)
rdd1.countByKey().foreach(println)
// val rdd2 = sc.parallelize(List(
// "lovel1","lovel2","lovel3","lovel4",
// "lovel5","lovel6","lovel7","lovel8",
// "lovel9","lovel10","lovel11","lovel12"), 2)
// rdd1.countByValue().foreach(println)
// rdd1.zipWithIndex().foreach(println)
// rdd1.zip(rdd2).foreach(println)
// val rdd2 = rdd1.mapPartitionsWithIndex((index,iter)=>{
// val list = new ListBuffer[String]()
// while(iter.hasNext){
// list.+=("rdd1 partition index = " + index + ",value="+iter.next())
// }
// list.iterator
// }, true)
// rdd2.coalesce(4, false)
// rdd2.foreach(println)
sc.stop()
}
}
spark ha node2 master node3 master-backup worker node4 worker [root@node2 ~]# cat /opt/sxt/spark-1.6.0/conf/spark-env.sh | grep export export JAVA_HOME=/usr/java/jdk1.8.0_221 export SPARK_MASTER_IP=node2 export SPARK_MASTER_PORT=7077 export SPARK_WORKER_CORES=2 export SPARK_WORKER_MEMORY=3g export SPARK_MASTER_WEBUI_PORT=8888 export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node2:2181,node3:2181,node4:2181 -Dspark.deploy.zookeeper.dir=/sparkmaster0821" scp 到node3,4 修改: [root@node3 ~]# cat /opt/sxt/spark-1.6.0/conf/spark-env.sh | grep export export SPARK_MASTER_IP=node3 启动 node 2,3,4 的zookeeper /opt/sxt/zookeeper-3.4.6/bin/zkServer.sh start node2启动spark 集群 /opt/sxt/spark-1.6.0/sbin/start-all.sh node3启动master集群 /opt/sxt/spark-1.6.0/sbin/start-master.sh http://node2:8888/ http://node3:8888/ node2 /opt/sxt/spark-1.6.0/sbin/stop-master.sh 稍等一会儿,观察 http://node3:8888/ ## 启动 node2的master,执行提交如何应用程序。立即 kill node3 的master,查看效果 ./spark-submit --master spark://node2:7077,node3:7077 --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 10000