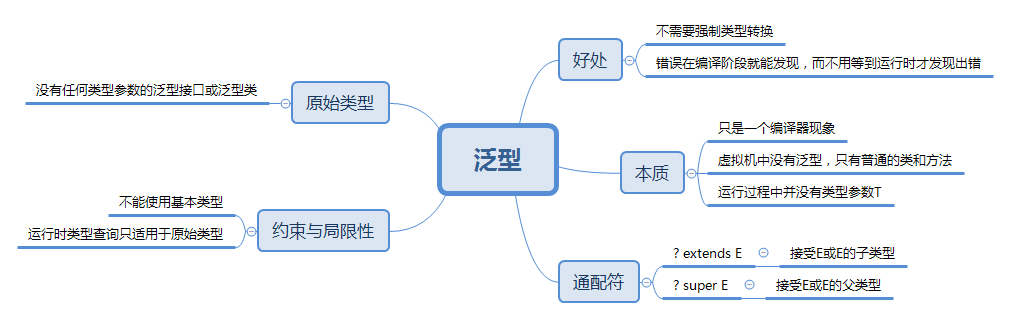
1. 本周学习总结
1.1 以你喜欢的方式(思维导图或其他)归纳总结集合与泛型相关内容。
1.2 选做:收集你认为有用的代码片段
1.遍历map的两种方法:
使用foreach循环
for (String a : map.keySet()) {
System.out.println(a+"="+map.get(a));
}
for (Map.Entry<String,ArrayList<Integer>> e:map.entrySet() ) {
System.out.println(e.getKey()+"="+e.getValue());
}
使用迭代器
Set<String> set=map.keySet();
Iterator<String> it=set.iterator();
while(it.hasNext()){
String a=it.next();
System.out.println(a+"="+map.get(a));
}
2.stream()、filter()和collect():
List<Student2> newStudent=s.stream().filter(e->e!=null&&e.getId()>1L&&e.getName().equals("xie")&&e.getAge()>17&&e.getGender()==Gender.girl&&e.isJoinsACM()==false).collect(Collectors.toList());
3.泛型方法:
public static <T extends Comparable<T>> T max(List<T> list){
Collections.sort(list);
return list.get(list.size()-1);
}
public static <T extends Comparable< ? super T>> T max1(List<T> list,Comparator< ? super T> comp) {
Collections.sort(list,comp);
return list.get(list.size()-1);
}
public static <T extends User> int myCompare(T o1,T o2, Comparator<? super T> c){
return c.compare(o1, o2);
}
2. 书面作业
1. List中指定元素的删除(题集题目)
1.1 实验总结。并回答:列举至少2种在List中删除元素的方法。
实验总结:
- 以空格(单个或多个)为分隔符,将line中的元素抽取出来,放入一个List:用正则表达式
String[] str=nextLine.split("\s+");将line中的元素抽取出来放入list中,并返回list - 在list中移除掉与str内容相同的元素:注意要从后往前遍历列表删除相同元素,否则不能完全遍历列表
在List中删除元素的方法:
1.从后往前遍历
private static void remove(List<String> list, String word) {
// TODO Auto-generated method stub
for(int i=list.size()-1;i>=0;i--){
if(list.get(i).equals(word))
list.remove(list.get(i));
}
}
2.使用迭代器遍历
private static void remove(List<String> list, String word){
Iterator it=list.iterator();
while(it.hasNext()){
if(it.next().equals(word))
it.remove();
}
}
2. 统计文字中的单词数量并按出现次数排序(题集题目)
2.1 伪代码(不得复制代码,否则扣分)
while(true)
if(输入为!!!!!)
break;
else
if(hashmap中包含该元素)
修改value加1放入hashmap中
else
value为1放入hashmap中
将HashMap转化为ArrayList
实现Collections接口进行排序
输出单词数量
输出排序后的前十个单词
2.2 实验总结
要实现题目所说的排序功能,不能用TreeMap实现,要用Collections接口实现,TreeMap只能实现对键值的排序
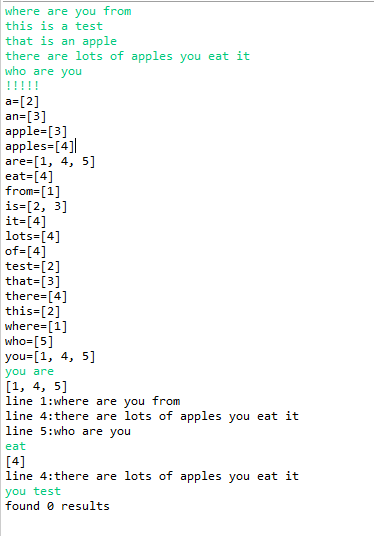
3. 倒排索引(题集题目)
3.1 截图你的代码运行结果
3.2 伪代码(不得复制代码,否则扣分)
while(有下一行文本)
if(输入的是!!!!!)
break;
else
将这一行文本加入列表s中
将文本中的每个单词(Key)及所在行数(Value)加入map中
遍历map输出每一个元素
while(true)
if(要索引的文本为空)
输出found 0 results
continue;
else
if(map中不包含要索引文本的每个单词)
输出found 0 results
continue;
else
将第一个单词的行数(Value)存进列表a
for(遍历剩下的单词)
将单词的行数(Value)存进列表b
取a和b的交集
if(a为空)
输出found 0 results
continue;
else
输出列表a的值
输出行集与行集内每一行的内容
3.3 实验总结
在将单词插入TreeMap中时,应该注意如果同一行出现相同单词,则不将该单词和行数加入TreeMap中,否则会出错
4.Stream与Lambda
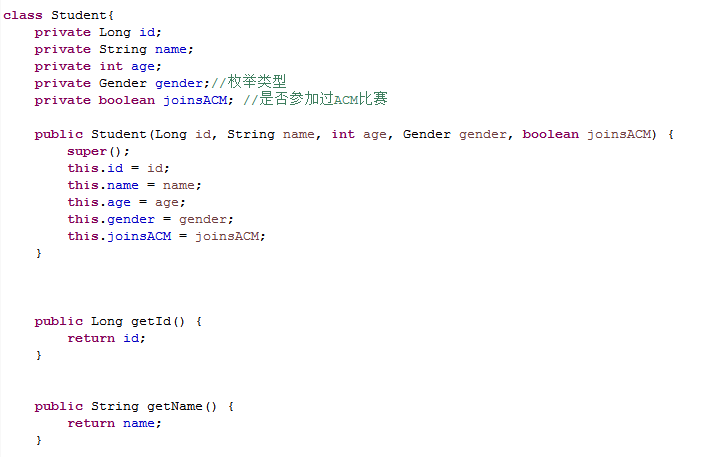
编写一个Student类,属性为:
private Long id;
private String name;
private int age;
private Gender gender;//枚举类型
private boolean joinsACM; //是否参加过ACM比赛
创建一集合对象,如List
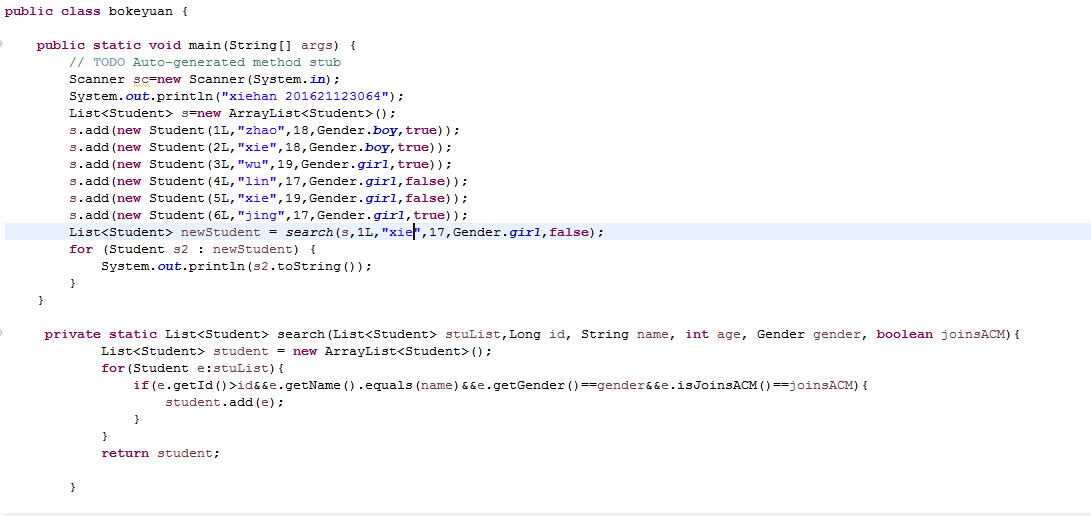
4.1 使用传统方法编写一个搜索方法List<Student> search(List<Student> stuList, Long id, String name, int age, Gender gender, boolean joinsACM),然后调用该方法将id>某个值,name为某个值, age>某个值, gender为某个值,参加过ACM比赛的学生筛选出来,放入新的集合。在main中调用,然后输出结果。(截图:出现学号、姓名)
Student类:

主函数:
运行结果:
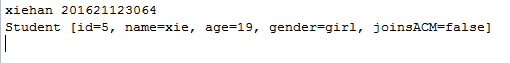
4.2 使用java8中的stream(), filter(), collect()编写功能同4.1的代码,并测试(要出现测试数据)。构建测试集合的时候,除了正常的Student对象,再往集合中添加一些null,你编写的方法应该能处理这些null而不是抛出异常。(截图:出现学号)
主要代码:
List<Student2> newStudent=s.stream().filter(e->e!=null&&e.getId()>1L&&e.getName().equals("xie")&&e.getAge()>17&&e.getGender()==Gender.girl&&e.isJoinsACM()==false).collect(Collectors.toList());
运行结果:

5. 泛型类:GeneralStack
5.1 GeneralStack接口的代码

5.2 结合本题与以前作业中的ArrayListIntegerStack相比,说明泛型有什么好处
以前的作业ArrayListIntegerStack类只要一定义完毕,就只能存放Integer类型的数据,这次作业中使用泛型技术,可以定义不同的栈存放不同类型的数据,比如Double类型,Integer类型,Car类型,增强了可拓展性,也大大简化了代码。
6. 选做:泛型方法
6.1 编写方法max,该方法可以返回List中所有元素的最大值。List中的元素必须实现Comparable接口。编写的max方法需使得String max = max(strList)可以运行成功,其中strList为List<String>类型。也能使得Integer maxInt = max(intList);运行成功,其中intList为List<Integer>类型。注意:不得直接调用Collections.max函数。
主要代码:
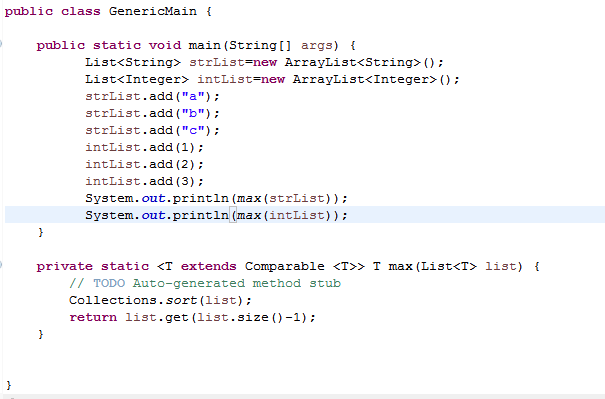
运行结果:

6.2 选做:现有User类,其子类为StuUser,且均实现了Comparable接口。编写方法max1,基本功能同6.1,使得User user = max1(stuList);可以运行成功,其中stuList为List类型。也可使得Object user = max(stuList)运行成功。
主要代码:
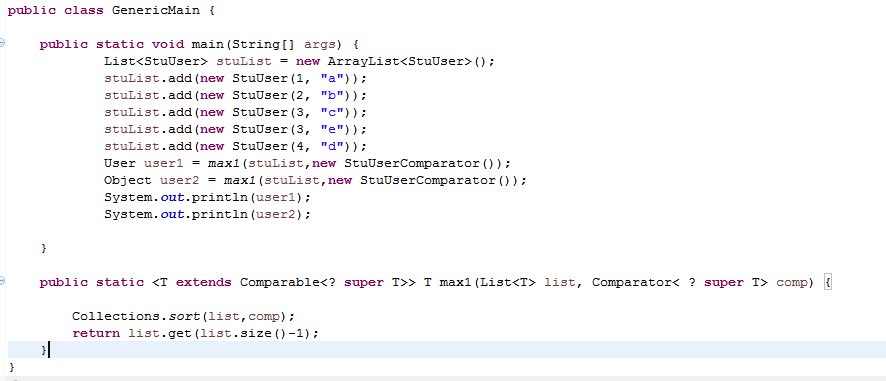
运行结果:

6.3 选做:编写int myCompare(T o1, T o2, Comparator c)方法,该方法可以比较两个User对象,也可以比较两个StuUser对象,传入的比较器c既可以是Comparator<User>,也可以是Comparator<StuUser>。注意:该方法声明未写全,请自行补全。
主要代码:
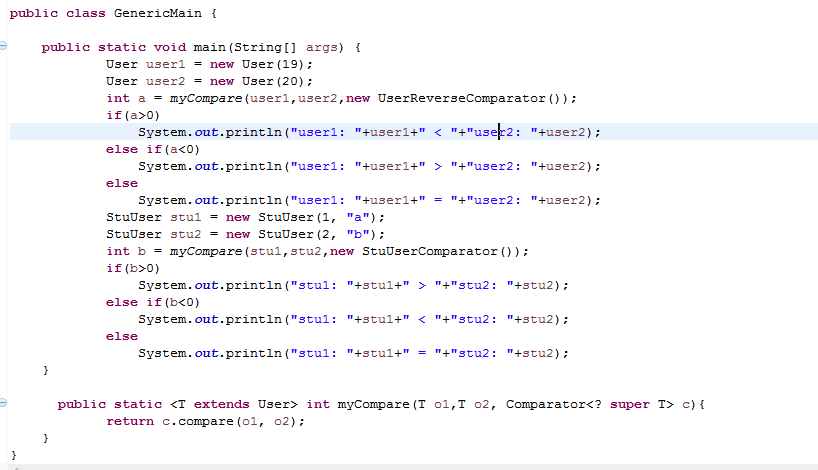
运行结果:

7. 选做:逆向最大匹配分词算法
7.1 写出伪代码(不得直接复制代码)
将每一个词添加进集合set
while(hasnextline)
i=line.length
while(i>0)
for(j=i-1->0)
如果set中包含line.substring(j,i)
将该词添加进list
i的位置向前进添加的词的长度
逆序输出list中的内容
清空list中的内容
7.2 截图你的代码运行结果。
这一题最后没完全实现好,在找词的时候应该找最长的词进列表list,有时间的话会再进行改进,还有输入“好朋友”的时候,set集中都没有“好”“朋”“友”三个字,为什么会有输出呢?这个地方我也没想明白

3.码云及PTA
3.1. 码云代码提交记录
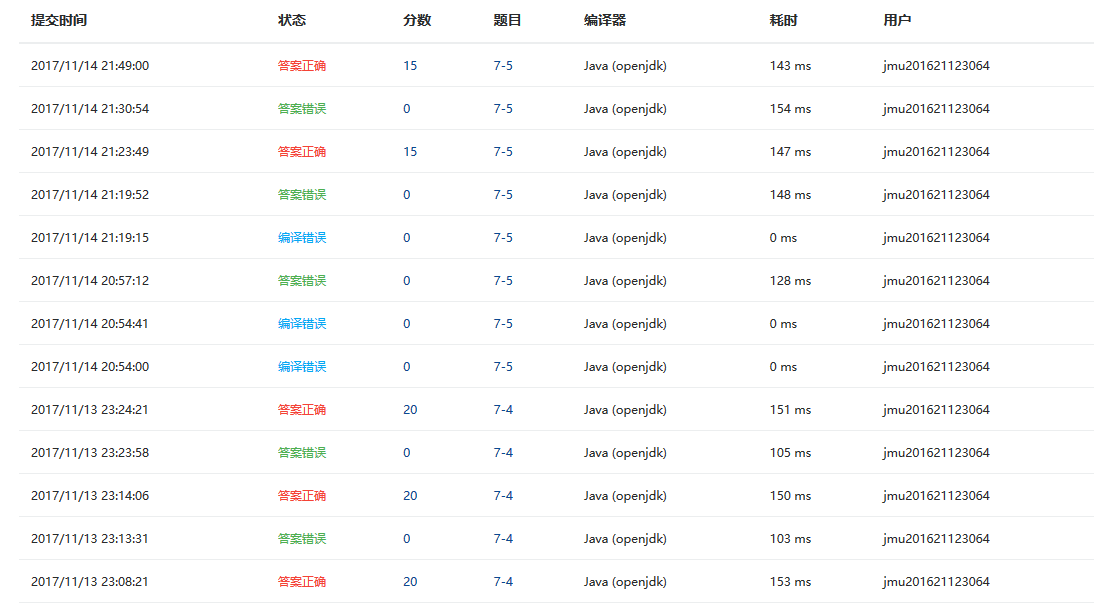
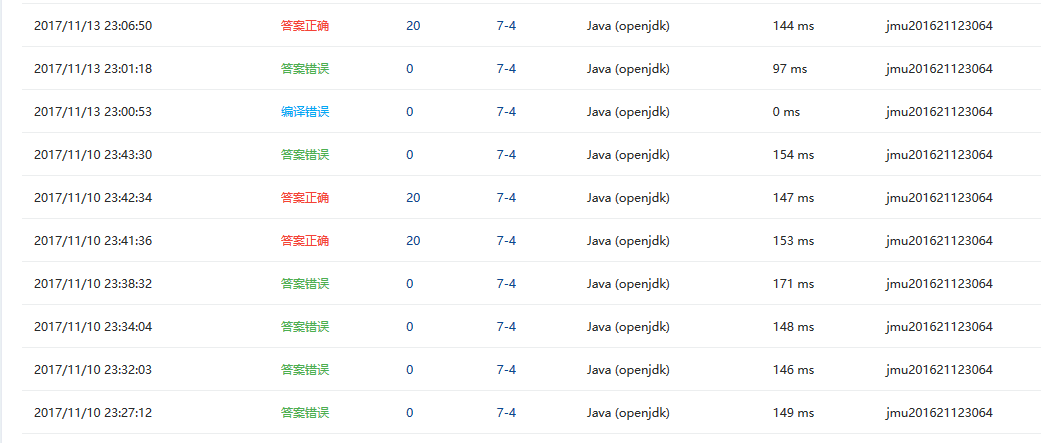
3.2 截图PTA题集完成情况图

3.3 统计本周完成的代码量

| 周次 | 总代码量 | 新增代码量 | 总文件数 | 新增文件数 |
|---|---|---|---|---|
| 2 | 343 | 343 | 10 | 10 |
| 3 | 498 | 498 | 8 | 8 |
| 5 | 788 | 788 | 26 | 26 |
| 6 | 536 | 536 | 16 | 16 |
| 7 | 776 | 776 | 9 | 9 |
| 8 | 846 | 846 | 4 | 4 |
| 9 | 668 | 668 | 12 | 12 |
| 10 | 501 | 501 | 7 | 7 |
4. 评估自己对Java的理解程度
| 维度 | 程度 |
|---|---|
| 语法 | PTA题目大部分可自行完成,不会的百度或者问问同学也能写出来,实在难的题目多花一点时间还是可以攻克的 |
| 面向对象设计能力 | 购物车系统做出来的效果不是很尽如人意,写一些单独的方法还是可以的,但是写大的系统需要考虑的东西比较多,思路很容易乱掉,需要较长的时间来建立模型 |
| 应用能力 | 还没尝试过 |
| 至今为止代码行数 | 4956 |
选做:5.使用Java解决实际问题
有n门课程,每个学生对每门课程都有几个不懂的问题(每题都有标号)。教师期望对所有学生的问题进行归类,首先对问题按课程分类,在某类中又将同一个学生的题目归类在一起。现有的操作流程,是每个学生把自己的各科目中不懂得题目按课程分类号后发给学习委员,学习委员进行统一汇总。现在希望编写一个程序,帮助学习委员分类,并统计每门课程中哪些题目不懂率最高。尝试写出解决该问题的大概步骤?每个学生发给学习委员的文件内容应遵循一定规范方便程序处理,尝试写出该规范。
输入的规范:
课程名称
性名 不懂的题目序号
例如:

思路:每一门课程是一个map,实现名字对题目的映射,不懂率可以对每个题目用一个count,输出count的值