编写WordCount数单词程序
0x00启动hadoop集群
shell脚本编写:
vim start
#!/bin/bash
/opt/hadoop-2.6.0-cdh5.6.0/sbin/start-all.sh
给脚本加权限
chmod 777 start
执行脚本
./start
0x01新建文件夹并编写程序
创建文件夹
mkdir -p /opt/test2/com/hellohadoop/
单词计数Mapper类
vim TokenizerMapper.java
package com.hellohadoop;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class TokenizerMapper extends Mapper<LongWritable,Text,Text,IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key,Text value,Context context) throws
IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
单词计数Reducer类
vim IntSumReducer.java
package com.hellohadoop;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable>{
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
单词计数main函数
vim WordCount.java
package com.hellohadoop;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static void main(String[] args) throws IOException,
ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
if(args.length != 2) {
System.err.println("Usage:wordcount<in><out>");
System.exit(2);
}
Job job = Job.getInstance(conf,WordCount.class.getSimpleName());
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
0x02编译
将hadoop的通用jar包路径添加进java的class路径中
export CLASSPATH=/opt/hadoop-2.6.0-cdh5.6.0/share/hadoop/common/hadoop-common-2.6.0-cdh5.6.0.jar:/opt/hadoop-2.6.0-cdh5.6.0/share/hadoop/mapreduce2/hadoop-mapreduce-client-core-2.6.0-cdh5.6.0.jar
注意要一起编译,不能单独编译
javac *.java
错误提示:!!!原来的程序提示API被覆盖,文章给出的代码是修改后的
//Job job=new Job(conf,"WordCount"); 这是原来的代码
Job job = Job.getInstance(conf,WordCount.class.getSimpleName()); //这是修改后的

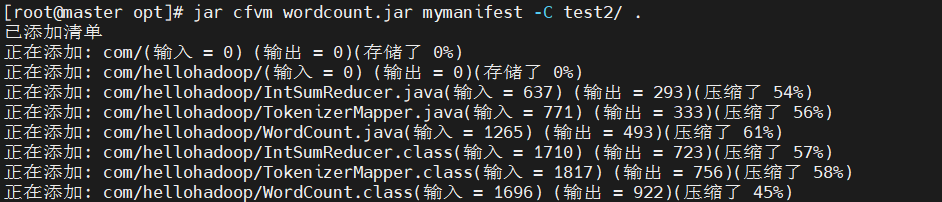
0x03打包
jar cfvm wordcount.jar mymanifest -C test2/ .
0x04运行程序
hadoop jar wordcount.jar com.hellohadoop.WordCount /user/test/wordcountinput /user/test/wordcountoutput
第一个路径是输入目录,第二个路径是输出目录
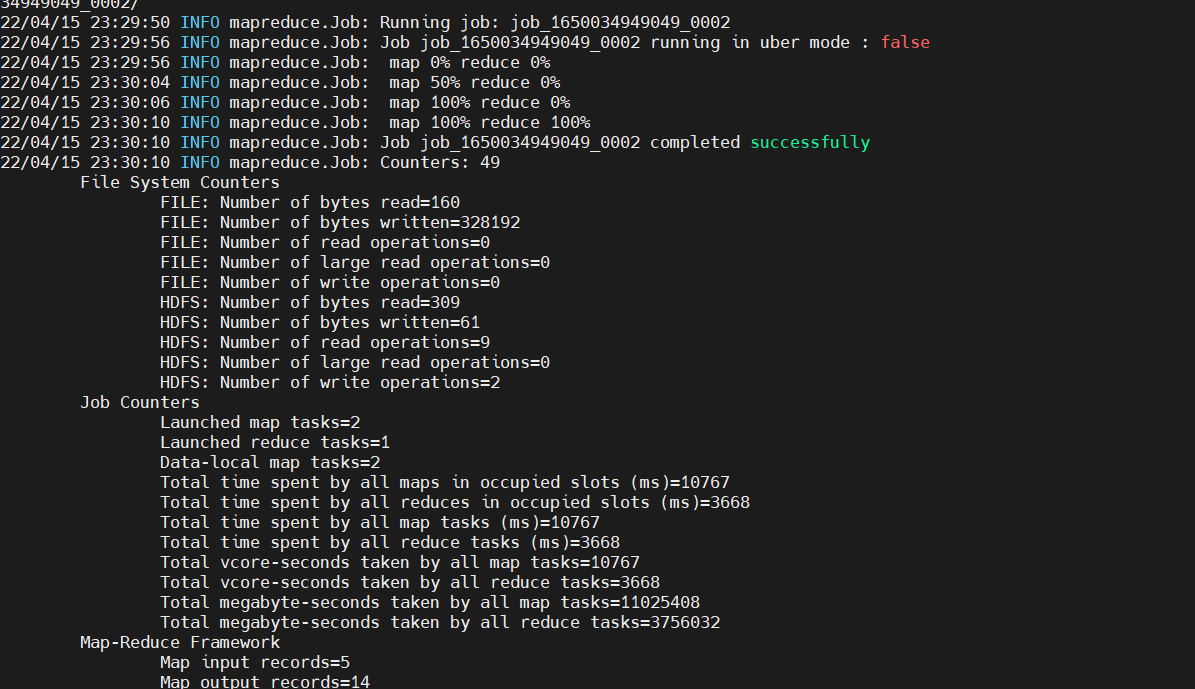
程序成功运行
0x05查看运行结果
hdfs dfs -cat /user/test/wordcountoutput/part-r-00000
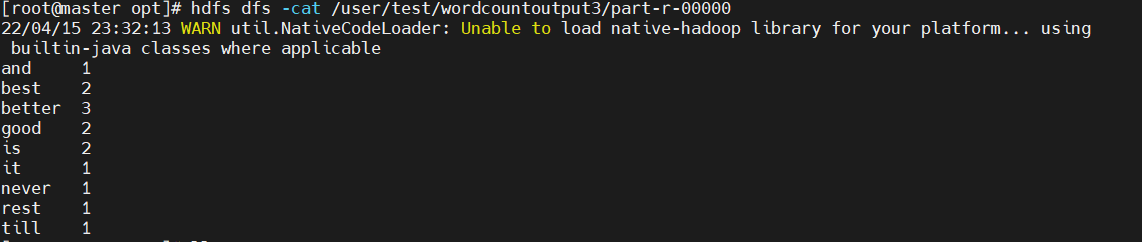
0x06增加要统计的文件
在本地新建一个文件
vim words.txt
网上随便找个英语短文。(中国日报上找的英文新闻http://www.chinadaily.com.cn/)
Public hospitals cannot refuse patients who need emergency treatment even if they do not test negative for COVID-19 within 48 hours, a Shanghai health official said on Friday.Wu Qianyu, a senior inspector of the municipal health commission, said public hospitals across the city must keep the emergency department, fever clinic and other key departments open during the ongoing COVID-19 outbreak."Should a patient who requires emergency treatment not have a valid nucleic acid test result, hospitals should administer the test as quickly as possible, and proceed with the patient's treatment in a buffer zone or special surgery room," said Wu."The test laboratory should be kept open 24 hours a day, and hospital should add more staff and shifts to reduce the waiting time of patients."In light of the outbreak, the Shanghai Bureau of Veteran Affairs has launched an online consultation platform helmed by volunteer medical personnel. Seventy-three veteran military medics have since Tuesday been taking turns to provide psychological counseling and advice on chronic diseases and daily healthcare matter.Deng Xiaodong, director of the bureau, said seven academicians and 25 experts retired from hospitals affiliated to the Naval Medical University were among the volunteer veteran medics.
将本地文件移动到hadoop集群中
hadoop dfs -put /opt/words.txt /user/test/wordcountinput
查看是否移动成功
hadoop dfs -ls /user/test/wordcountinput

可以看到刚才新建的文件
再次运行程序(!!!注意输出文件夹要新建,直接在命后面加数字即可)
hadoop jar wordcount.jar com.hellohadoop.WordCount /user/test/wordcountinput /user/test/wordcountoutput4
hdfs dfs -cat /user/test/wordcountoutput4/part-r-00000
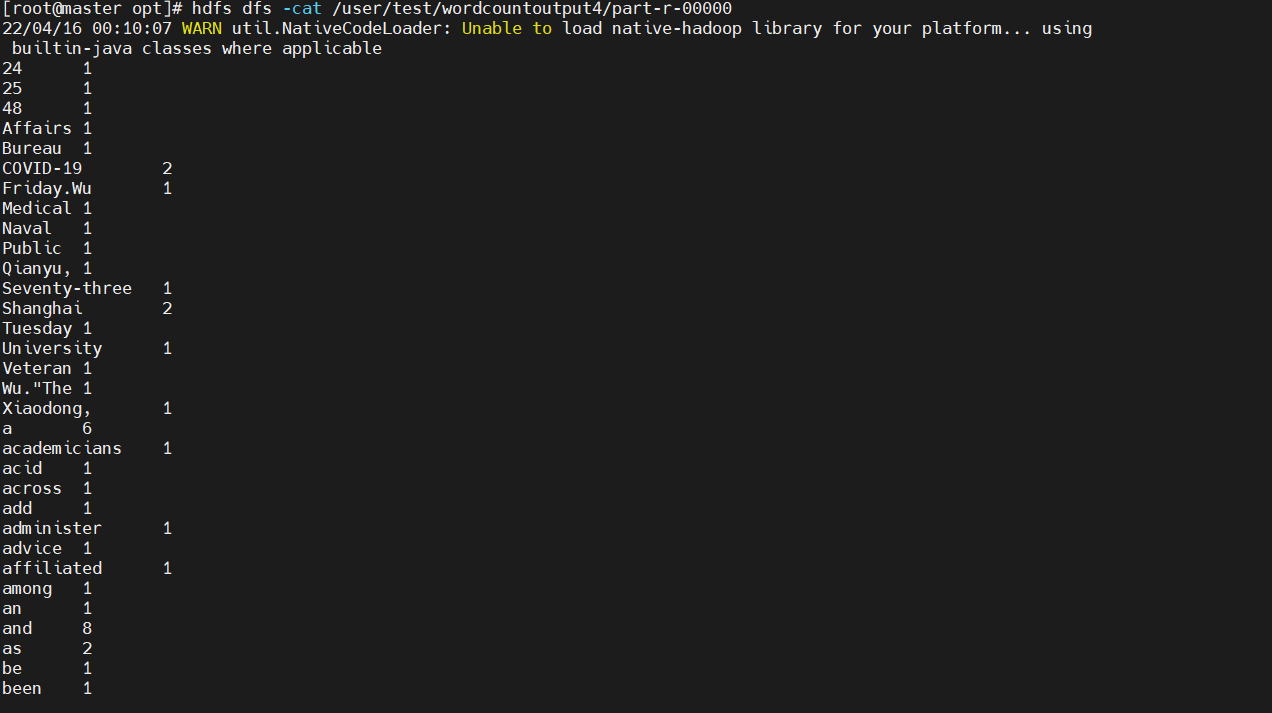
成功运行。