作者: 刘用, 现任新东方APP团队高级软件工程师
2019年开始,新东方APP团队启动了长达半年以上的稳定性建设工作,为什么稳定性如此重要?因为随着每年30%以上的高速增长,现有的后端服务完全扛不住日益增多的用户带来的高并发,高可用场景。所以优化工作势在必行。
如果你是一名java程序员的话,相信你也会很清楚,有时候,在研发功能的时候,仅仅是贴着产品的需求在做开发,功能是都实现了,但是没有考虑到功能在高并发下面是否可用,响应是否及时。这就给以后的线上运行留下很多隐患。
我们做稳定性建设的原因就是要解决这些隐患,提高系统稳定性,提高单台机器的QPS性能。加快接口响应速度,优化数据库的sql查询。
下面看一下优化后的效果图:

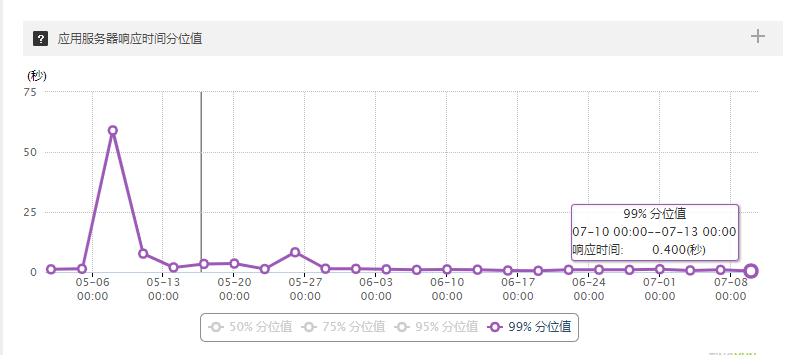
以上是单独一台服务器的吞吐率和响应时间曲线图,从图中可以看到,暑期吞吐率增长5倍,服务响应时间从最长的50多秒大幅度减少到0.4秒。优化效果明显。
以下从3方面阐述优化方法:
1、如何定位后端问题
2、如何解决数据库问题
3、如何分析和解决程序问题
一、定位后端问题的方法:
kibana。可以还原线上有问题的接口的参数列表(实时性比较好,统计多台服务器的日志,统一处理)。
听云 用听云监测慢事务,慢接口比较详细,能准确定位接口是sql慢,还是代码哪里慢。
二、数据库知识点和优化
1、2种存储引擎
在MySQL中,索引属于存储引擎级别的概念,不同存储引擎对索引的实现方式是不同的,本次主要讨论MyISAM和InnoDB两个存储引擎的索引实现方式。
1.1、MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址,在MyISAM中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求key是唯一的,而辅助索引的key可以重复。
1.2、虽然InnoDB也使用B+Tree作为索引结构,但具体实现方式却与MyISAM截然不同。第一个重大区别是InnoDB的数据文件本身就是索引文件。MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。而在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。
聚集索引这种实现方式使得按主键的搜索十分高效,但是辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。
辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。
2、关于索引:
索引并不是越多越好,要根据查询有针对性的创建,考虑在 WHERE 和 ORDER BY 命令上涉及的列建立索引,可根据 EXPLAIN 来查看是否用了索引还是全表扫描。
应尽量避免在 WHERE 子句中对字段进行 NULL 值判断,否则将导致引擎放弃使用索引而进行全表扫描。
值分布很稀少的字段不适合建索引,例如“性别”这种只有两三个值的字段。
字符字段最好不要做主键。
不用外键,由程序保证约束。
使用多列索引时注意顺序和查询条件保持一致,同时删除不必要的单列索引。
最左前缀匹配
当查询条件精确匹配索引的左边连续一个或几个列时,索引可以被用到,但是只能用到一部分,即条件所组成的最左前缀
查询 SQL
3、关于查询 SQL:
可通过开启慢查询日志来找出较慢的 SQL。
不做列运算:SELECT id WHERE age + 1 = 10,任何对列的操作都将导致表扫描,它包括数据库教程函数、计算表达式等等,查询时要尽可能将操作移至等号右边。
SQL 语句尽可能简单:一条 SQL只能在一个 CPU 运算;大语句拆小语句,减少锁时间;一条大 SQL 可以堵死整个库。
不用SELECT *。
IN 的个数建议控制在 200 以内。
不用函数和触发器,在应用程序实现。
不用 JOIN。
使用同类型进行比较,比如用 '123' 和 '123' 比,123 和 123 比。
尽量避免在 WHERE 子句中使用!=或<>操作符,否则引擎将放弃使用索引而进行全表扫描。
列表数据不要拿全表,要使用 LIMIT 来分页,每页数量也不要太大。
4、升级硬件
根据 MySQL 是 CPU 密集型还是 I/O 密集型,通过提升 CPU 和内存、使用 SSD,都能显著提升 MySQL 性能。
5、读写分离
也是目前常用的优化,从库读主库写,一般不要采用双主或多主引入很多复杂性,尽量采用其他方案来提高性能。
6、原则上索引个数不大于3个。条件复杂的情况,用复合索引代替多个单独索引。
三、程序问题
优化程序的前提是你必须先把接口代码完整读一遍,深刻理解业务,然后根据听云定位接口慢的地方。
vps系统里面有很多循环查询数据库的地方,以及in后面一个很大的集合的情况。这种情况可以采用多线程并行处理,加快速度。
1、In语句后面的参数集合太大,怎么办?
把数据库压力转移到程序中,拆分in后面的参数,采用多线程循环获取数据,用countDownLatch计数,等待所有返回。
2、第三方接口返回速度太慢,怎么办?
接口熔断机制,设置超时时间为6秒,加上3次重试机制。对于6秒以内的慢请求,添加缓存
3、对于复杂的join group by等操作,数据库返回慢怎么办?
把复杂的sql用java代码来实现逻辑,数据库只是执行简单的查询,后面的处理都交给代码来实现。