有个200多万的用户表,显示列表时非常慢,查了一下原来使用了limit进行分页。
前几页用时很少

但是后面页数就简直不可忍了,实际的业务逻辑还有排序,就更慢了
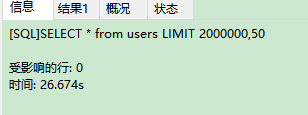
试试用查询时用带索引的键来确定范围。
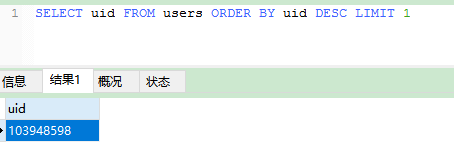
最大的id是103948598
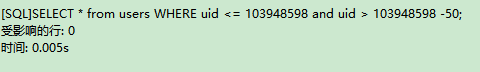
时间和用limit比相差几千倍啊!
使用explain 查看一下
mysql> explain SELECT * from users LIMIT 2000000,50;
+----+-------------+-------+------+---------------+------+---------+------+---------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+---------+-------+
| 1 | SIMPLE | users | ALL | NULL | NULL | NULL | NULL | 2839456 | |
+----+-------------+-------+------+---------------+------+---------+------+---------+-------+
1 row in set
mysql> EXPLAIN SELECT * from users WHERE uid <= 103948598 and uid > 103948598 -50;
+----+-------------+-------+-------+---------------+---------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+---------+---------+------+------+-------------+
| 1 | SIMPLE | users | range | PRIMARY | PRIMARY | 8 | NULL | 98 | Using where |
+----+-------------+-------+-------+---------------+---------+---------+------+------+-------------+
1 row in set
可以看到 limit是扫描了所有行,再按照需要返回指定范围的行,而使用uid时仅仅是扫描了指定范围的行。
所以用uid来确定范围就很稳定,而limit时,随着页数变大,就变的很慢了。
另外还可以使用缓存来优化,请见redispage