0x01 起因
前端时间遇到一个问题,怎么快速生成唯一的id,后来采用了hashid的方法。最近在网上读到了美团关于分布式唯一id生成器的解决方案,
其中提到了三种生成法:(建议看一下这篇文章,写得很详细,分析到位)
- UUID
- 数据库生成
- 类snowflake方案
0x02 问题
文中提到了如下几个问题
1.全局唯一性:不能出现重复的ID号,既然是唯一标识,这是最基本的要求。
2.趋势递增:在MySQL InnoDB引擎中使用的是聚集索引,由于多数RDBMS使用B-tree的数据结构来存储索引数据,在主键的选择上面我们应该尽量使用有序的主键保证写入性能。
3.单调递增:保证下一个ID一定大于上一个ID,例如事务版本号、IM增量消息、排序等特殊需求。
4.信息安全:如果ID是连续的,恶意用户的扒取工作就非常容易做了,直接按照顺序下载指定URL即可;如果是订单号就更危险了,竞对可以直接知道我们一天的单量。所以在一些应用场景下,会需要ID无规则、不规则。
上述123对应三类不同的场景,3和4需求还是互斥的,无法使用同一个方案满足。
0x03 解决思路
美团针对上面的场景,作了两种方案,Leaf-segment(数据库方式)和Leaf-snowflake(snowflake方式)。
由于之前用过hashid生成唯一id,突然觉得,我们可以保证上面的问题3和4,同时解决。
即用hashid来加密连续的id,发往客户端前先用hashid加密id,这样竞争对手就不能简单的相减订单号了。
不知道是否可用,还望大家指正。
0x04 其它方案
采用xid,xid和其它方案的对比如下:
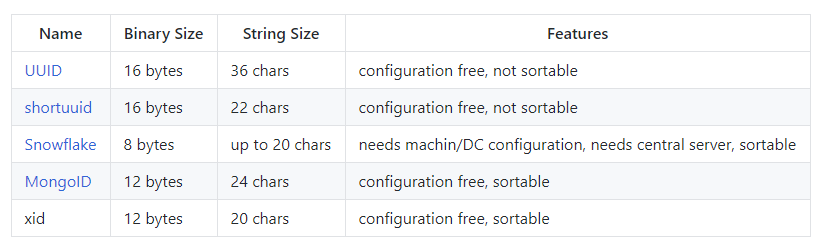
xid的由四部分组成
- 4 byte时间戳
- 3 byte机器特征
- 2 byte 进程id
- 3 byte 随机计数器
上代码测试一下
package main
import (
"github.com/rs/xid"
)
func main() {
for i := 1; i < 20; i++ {
guid := xid.New()
println(guid.String())
}
}
生成20个id,如下:
b8t55lhafc333a3mibh0
b8t55lhafc333a3mibhg
b8t55lhafc333a3mibi0
b8t55lhafc333a3mibig
b8t55lhafc333a3mibj0
b8t55lhafc333a3mibjg
b8t55lhafc333a3mibk0
b8t55lhafc333a3mibkg
b8t55lhafc333a3mibl0
b8t55lhafc333a3miblg
b8t55lhafc333a3mibm0
b8t55lhafc333a3mibmg
b8t55lhafc333a3mibn0
b8t55lhafc333a3mibng
b8t55lhafc333a3mibo0
b8t55lhafc333a3mibog
b8t55lhafc333a3mibp0
b8t55lhafc333a3mibpg
b8t55lhafc333a3mibq0
可以看到这些id也是单调递增的,那么可以搭建一个xid的服务,调用一次返回一个id。
另外还可以生成一个id池,比如预先存储一百万个id,然后消费者批量消费,当库存
剩下一半时,立马继续生产id放入id池。